The key words "MUST", "MUST NOT",
"REQUIRED", "SHALL", "SHALL NOT",
"SHOULD", "SHOULD NOT", "RECOMMENDED",
"MAY", and "OPTIONAL" are to be interpreted as described in
[RFC2119].
While RFC2119 permits the use of
synonyms, to achieve consistency across specifications, “MUST” is used instead
of “SHALL” and “REQUIRED”, “MUST NOT” instead of “SHALL NOT”, and “SHOULD”
instead of “RECOMMENDED” in this specification. To enable easy identification
of the keywords, uppercase is used for keywords.
Following are the core entities and its definitions
used by CIQ TC:
Name
Name of a person or an organisation
Address
A physical location or a mail delivery point
Party
A Party could be of two types namely,
·
Person
·
Organisation
An Organisation
could be a company, association, club, not-for-profit, private firm, public
firm, consortium, university, school, etc.
Party data
consists of many attributes (e.g. Name, Address, email address, telephone, etc)
that are unique to a party. However, a person or organisation’s name and
address are generally the key identifiers (but not necessarily the unique
identifiers) of a “Party”. A “Customer” is of type “Party”.
Party Relationship
Pairwise
affiliation or association between two people, between two organisations, or
between an organisation and a person.
xPRL supports chains of interlocking
pairwise party relationships, linked by common members.
2.1 Formal Design Requirements
Following are
the formal design requirements taken into consideration for version 3.0 XML Schemas
of CIQ Specifications:
·
Data structures SHOULD be described using W3C XML
Schema language
·
Data structures SHOULD be separated into
multiple namespaces for reuse of the core Party entities (e.g. Person Name,
Organisation Name, Address, Party Centric Information)
·
Data structures SHOULD be able to accommodate
all information types used for data exchanges based on previous versions of
the CIQ Specifications
·
Data structures SHOULD be extensible (also,
allow reduction in complexity) to provide enough flexibility for point-to-point
solutions and application-specific scenarios
·
Data structures SHOULD allow application-specific
information to be attached to entities without breaking the structures.
·
Implementation complexity SHOULD be proportional
to the complexity of the subset of data structures used by the implementer
·
Data structures SHOULD be customisable to meet different
end user requirements without breaking the structures and at the same time,
conforming to the core specification.
The entire party information space is
divided into a number of complex information types that are viewed as core entities.
This enables re-use of the core entities as required. We categorise these core
entities of CIQ Specifications into four namely,
·
Name
·
Address
·
Party Centric Information, and
·
Party Relationships
Following are
the basic and core CIQ specification entities defined in XML schemas as
re-usable types:
·
Name (Person or Organisation - see xNL.xsd
schema)
·
Address (see xAL.xsd schema)
·
Name and Address combined (see xNAL.xsd
schema)
·
Personal details of a person (person-centric
information) (see xPIL.xsd schema)
·
Organisation specific details (organisation-centric
information) (see xPIL.xsd schema)
·
Party Relationships (see xPRL.xsd [not available in this release] and xLink-2003-12-31-revised.xsd
schemas)
These core
entities are supported by relevant code lists/enumerations to add “semantics/meaning”
to the data they represent. This will be discussed in detail in the following
sections.
Following are the different XML schemas
produced for version 3.0:
|
XML Schema File name
|
Description
|
Comments
|
|
xNL.xsd
|
Entity Name
|
Defines a set of reusable types and elements for a name
of individual or organisation
|
|
xNL-types.xsd
|
Entity Name Enumerations
|
Defines a set of enumerations to support Name entity
|
|
xAL.xsd
|
Entity Address
|
Defines a set of reusable types and elements for an
address, location name or description
|
|
xAL-types.xsd
|
Entity Address Enumerations
|
Defines a set of enumerations to support address entity
|
|
xNAL.xsd
|
Name and Address binding
|
Defines two constructs to associate/link names and
addresses for data exchange or postal purposes
|
|
xNAL-types.xsd
|
Name and Address binding Enumerations
|
Defines a set of enumerations to support name and address
binding
|
|
xPIL.xsd (formerly xCIL.xsd)
|
Entity Party (organisation or individual)
|
Defines a set of reusable types and elements for a
detailed description of an organisation or individual centric information
|
|
xPIL-types.xsd
|
Entity Party (organisation or individual) Enumerations
|
Defines a set of enumerations to support party centric
information entity
|
|
CommonTypes.xsd
|
Common Data Types and Enumerations
|
Defines a set of commonly used data types and
enumerations in the CIQ Schemas
|
|
xLink-2003-12-31.xsd
|
xLink attributes
|
Implements a subset of W3C xLink specification attributes
as XML schema
|
|
*.gc files
|
Entity Party, Name, and Address
|
Defines a set of enumerations/code lists in genericode
format
|
Name, Address
and Party schemas are designed to bring interoperability to the way these most “common”
Party related entities are used across all spectrums of business and
government.
Name, Address and
Party information components of version 3.0 share common design concepts that
are implemented as XML Schemas. This commonality should simplify understanding
and adoption of the XML Schemas. The xNAL schema design concept varies
slightly as it is only a simple container for associating/linking names and
addresses.
The design
concepts of Name, Address and Party schemas are similar in terms of the way semantic
information is represented to add the required “meaning” to the data. For
example, for a person’s name data, “Given Name, “Middle Name’ Surname” etc, are
the semantic information that add meaning to the data.
All common design concepts used in the
CIQ Specifications (e.g. using code lists/enumerations, customising CIQ entity
schemas, extending CIQ entity schemas, referencing between entities, defining
business rules to constrain CIQ entity schemas) are equally applicable for all
key entities of CIQ specifications namely, Name, Address and Party. These
common concepts are explained in detail in section 3 (Entity “Name”). Users
SHOULD study that section in detail before proceeding to other entities namely,
Address and Party, as these concepts are applicable to these entities also.
Following are the namespaces used in the
specification:
|
Entity
|
Namespace
|
Suggested Prefix
|
XML Schema Files
|
|
Name
|
urn:oasis:names:tc:ciq:xnl:3
|
xnl (or) n
|
xNL.xsd
xNL-types.xsd
|
|
Address
|
urn:oasis:names:tc:ciq:xal:3
|
xal (or) a
|
xAL.xsd
xAL-types.xsd
|
|
Name and Address
|
urn:oasis:names:tc:ciq:xnal:3
|
xnal
|
xNAL.xsd
xNAL-types.xsd
|
|
Party
|
urn:oasis:names:tc:ciq:xpil:3
|
xpil (or) p
|
xPIL.xsd
xPIL-types.xsd
|
|
Party Relationships
|
urn:oasis:names:tc:ciq:xprl:3
|
xprl (or) r
|
xPRL.xsd
xPRL-types.xsd
|
|
xLink
|
http://www.w3.org/1999/xlink
|
xLink
|
xLink-2003-12-31.xsd
|
This document
contains references to XML Linking Language (XLink) Version 1.0, W3C
Recommendation 27 June 2001 available at http://www.w3.org/TR/xlink/
. The CIQ TC strongly recommends readers to read the xLink specification from
W3C if they want to use this supported feature in CIQ Specifications.
This document
contains references to Code List version 1.0, OASIS Code List Representation TC
Committee Specification 01, December 2007 available at http://www.oasis-open.org/committees/codelist.
The CIQ TC strongly recommends readers to read the code list specification if
they want to use this supported feature in CIQ Specification.
This document contains references to Context Value Association, Working Draft 0.2, November 2007, available at http://www.oasis-open.org/committees/codelist.
The CIQ TC strongly recommends readers to read the methodology if they want to
use this supported feature in CIQ Specification.
GeoRSS 2.0
(georss.org) from Open Geospatial Consortium (http://www.opengeospatial.net) has
been referenced in this specification as it is critical to assuring
interoperability with a variety of geospatial technologies, such as GIS,
Spatial Data Infrastructures, Location Services, and the GeoWeb.
Entity “Name”
has been modelled independent of any context as a standalone specification to
reflect some common understanding of concepts “Person Name” and “Organisation
Name”.
CIQ Version 3.0
“Name” XML schema is separated into two parts: a structural part (xNL.xsd)
as shown in the XML schema diagram below and, separate enumeration/code list
files (code lists defined in an XML schema (xNL-types.xsd) and also,
code lists represented in genericode format as .gc files) supporting the
structure by adding semantics to the data. “Genericode” will be discussed in
later sections.
The structural
part (xNL.xsd) SHOULD remain unchanged over the course of time while the
code list/enumeration files (xNL-types.xsd or .gc files) MAY be customised
to meet particular implementation needs as the semantics of data varies from
one requirement to another.
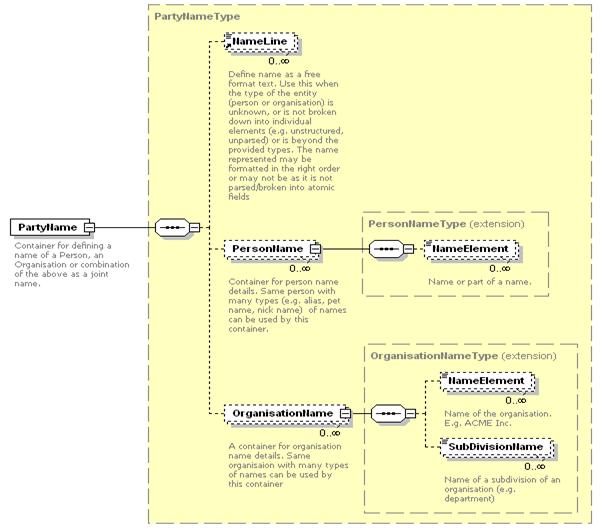
In the schema
structure above (xNL.xsd), “NameElement” stores the name of a party and
the supporting enumeration lists referenced as attributes in the schema
structure (see the xNL.xsd schema for the list of attributes or the HTML
documentation of the schema) that provide the semantic meaning of the data.
The structure
allows for different semantic levels based on the following paradigm:
·
A simple data structure with minimum semantics
SHOULD fit into the schema with minimal effort
·
A complex data structure SHOULD fit into the
schema without loss of any semantic information
The least level
of complexity in representing party name data is when a typical database does
not differentiate between a person name and an organisation name where only one
field has been allocated for storing the complete name information
(unstructured data). This database can be mapped to xNL as follows:
<n:PartyName>
<n:NameLine>Mr Jeremy Apatuta Johnson</n:NameLine>
</n:PartyName>
In this example,
information related to party name, resides in NameLine element. It has no
semantic information that MAY indicate what kind of name it is, i.e. person
name or an organisation name, and what the individual name elements (atomic
data) are (i.e., the data has not been parsed into first name, last name,
title, etc.). What is known is that it is a name of some party, be it a person
or an organisation. Data in this free formatted/unstructured text form is
classified as “poor quality” as it is subject to different interpretations and MAY
cause interoperability problems when exchanged between two or more
applications/systems.
Many common
applications fall under this “No Semantics” category.
The medium level
of complexity in representing data is when a database differentiates between
person and organisation name. In this case, names are placed in the appropriate
elements namely, PersonName or OrganisationName inside the
structure.
Person Name:
<n:PartyName>
<n:PersonName>
<n:NameElement>Mr Jeremy Apatuta Johnson</n:NameElement>
</n:PersonName>
</n:PartyName>
This example
shows that name information belongs to an individual, but the semantics of the
individual name elements (e.g. what are the meanings of “Mr”, “Jeremy”, etc.) are
unknown.
Organisation Name:
<n:PartyName>
<n:OrganisationName>
<n:NameElement>Khandallah Laundering
Ltd.</n:NameElement>
</n:OrganisationName>
</n:PartyName>
This example is similar to the previous
one, except that the name belongs to an organisation. The quality of data in
this case is marginally better than Example 1.
Many common applications fall under this “Minimal
Semantics” category.
The maximum level
of complexity in representing data is when a database differentiates between
person and organisation name and also differentiates between different name
elements within a name (the semantics). The data is structured and the quality
of data is excellent.
<n:PartyName>
<n:PersonName>
<n:NameElement Abbreviation="true"
ElementType="Title">Mr</n:NameElement>
<n:NameElement
ElementType="FirstName">Jeremy</n:NameElement>
<n:NameElement
ElementType="MiddleName">Apatuta</n:NameElement>
<n:NameElement
ElementType="LastName">Johnson</n:NameElement>
<n:NameElement
ElementType="GenerationIdentifier">III</n:NameElement>
<n:NameElement
ElementType="GenerationIdentifier">Junior</n:NameElement>
<n:NameElement
ElementType="Title">PhD</n:NameElement>
</n:PersonName>
</n:PartyName>
This example
introduces ElementType attribute that indicates the exact meaning of the
name element. Few applications and in particular, applications dealing with
data quality and integrity, fall under this “Full Semantics” category and
often, the database supported by these applications are high in the quality of
the data it manages. This is an additional level of semantics that is supported
through code list/enumerated values. Technically, the enumerations sit in a
separate schema (xNL-types.xsd) or in genericode files.
The more structured
the data is, the better the interoperability of the data.
An example of
enumeration is a list of name element types for a person name defined in xNL-types.xsd
as shown below.
<xs:simpleType name="PersonNameElementsEnumeration">
<xs:restriction base="xs:string">
<xs:enumeration value="PrecedingTitle"/>
<xs:enumeration value="Title"/>
<xs:enumeration value="FirstName"/>
<xs:enumeration value="MiddleName"/>
<xs:enumeration value="LastName"/>
<xs:enumeration value="OtherName"/>
<xs:enumeration value="Alias"/>
<xs:enumeration
value="GenerationIdentifier"/>
</xs:restriction>
</xs:simpleType>
All elements and
attributes in xNL schema have strong data types.
All free-text
values of elements (text nodes) and attributes are constrained by a simple type
“NormalizedString” (collapsed white spaces) defined in CommonTypes.xsd.
Other XML Schema data types are also used throughout the schema.
This is an important section that users
MUST give serious attention if they want to customise the CIQ schemas to meet
their specific requirements.
A code list (also called enumeration)
defines a classification scheme and a set of classification values to support
the scheme. For example, “Administrative Area” is a classification scheme and a
set of classification values for this classification scheme could be: State,
City, Province, Town, Region, District, etc.
XML Schema describes
the structural and lexical constraints on an XML document. Some information items
in a document are described in the schema lexically as a simple value whereby
the value is a code representing an agreed-upon semantic concept. The value
used is typically chosen from a set of unique coded values enumerating related
concepts. These sets of coded values are sometimes termed code lists.
Earlier versions
of CIQ Name, Address and Party Information specifications had concrete schema
grammar (e.g. First Name, Middle Name, Last Name, etc XML elements/tags for a person
name as shown in the figure below) to define the party entities.
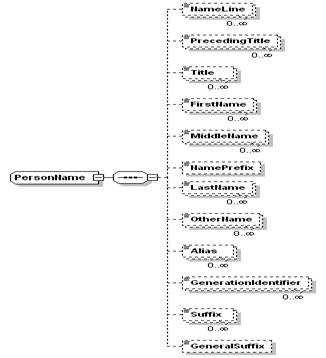
This did not
satisfy many name, address and party data usage scenarios that are geographic
and cultural specific. For example, in certain cultures, the concept of first
name, middle name, and last/family/surname for a person name does not exist. Representing
person names from these cultures in the earlier version of CIQ Specifications were
difficult as its name schema (v2.0 of xNL.xsd as shown in the above
figure) had pre-defined element names as FirstName, MiddleName, and LastName,
and they were semantically incorrect metadata for the data. To be precise, in some
culture where the concept of First Name does not exist, using First Name
element of CIQ specification to a data that appears in the first position of a
person’s name string is semantically incorrect.
Let us look at the following example
(this is not a fictitious person name, but real legal name of a person born in
the USA, who is a childhood friend of the Chair of CIQ TC. The street name and father’s name of the person have been
deliberately changed in this example to protect the identity of the person). The person’s name is:
Mr. William Street Rajan United States
Virginia Indian, where
“William Street”, is the name of
the street where the person was born
“Rajan”, is the name of the
person’s father
“United States”, is the country
where the person was born
“Virginia”, is the state where the
person was born, and
“Indian”, is the origin of the
person
The person is legally and formally called
as “WRUVI”
In the above
example, using the concept of First Name, Middle Name, Last Name, Surname,
Family Name, etc. does not provide the intended meaning of the name, and
therefore, the meaning of the data is lost.
The Name,
Address and Party schemas in this version provides code lists/enumerations
designed to satisfy common usage scenarios of the data by providing
semantically correct metadata/information/meaning to the data. These code lists
are customisable by the users to satisfy different name and address data requirements,
but at the same time ensures that the core CIQ schema structure is intact i.e.,
there is no need to change the schema to suit context specific semantic requirements.
A default set of code list/enumerated values (or in many cases, no values) are
provided with the schemas and these default values are not complete by any
means and therefore, are customisable by the user to suit their requirements.
The default code
list values/enumerations for Party Name used in the CIQ Specifications are
built using common sense and with culture-specific view of the subject area (in
this case Anglo-American culture, where the terms such as First Name, Middle
Name, Last Name are used), rather than adopted from a specific
application. The reason why we say “cultural specific view” is because some
cultures do not have the concept of First Name, Middle Name, and Last
Name and so on.
NOTE: The code
list/enumeration values for different code/enumeration lists that are provided
as part of the specifications are not complete. They only provide sample values
(and in most case no values) and it is up to the end users to customise them to
meet their data exchange requirements if the default values are incomplete, not
appropriate or over kill
There is always
a possibility that a specific application requires certain enumerated values
that are not part of the standard xNL, xAL and xPIL
specifications. It is acceptable for specific applications to provide its own
enumerated values (e.g. could be new one, delete an existing default one), but
it is important that all participants (could be internal business systems or
external systems) involved in data exchange SHOULD be aware of what the new
enumeration values are to enable interoperability. Otherwise, interoperability
will fail. Therefore, some agreement SHOULD be in place between the
participants involved in the data exchange process (e.g. Information Exchange Agreement
for data exchange) to agree on the enumeration values. These agreed enumeration
values SHOULD also be governed to manage any changes to them in order to
prevent interoperability breakdown. Any further information about these sorts
of agreements is outside the scope of the CIQ technical committee.
Therefore, for a
generic international specification like CIQ that is independent of any
application/industry/culture, the ability to customise the specification to
define context specific semantics to the data is important.
Now let us revisit
example 3.3.2.1 again. To
overcome the semantics problem and to not loose the semantics of the data,
using version 3.0 of the CIQ specification, users can define the correct
context specific semantics to the person name data as follows:
<n:PartyName>
<n:PersonName>
<n:NameElement ElementType="Title">Mr.</n:NameElement>
<n:NameElement ElementType="Birth Street
Name">William Street</n:NameElement>
<n:NameElement ElementType="Father
Name">Rajan</n:NameElement>
<n:NameElement ElementType="Country Of Birth”>United States</n:NameElement>
<n:NameElement ElementType="State Of Birth">Virginia</n:NameElement>
<n:NameElement ElementType="Country Of
Origin>Indian</n:NameElement>
</n:PersonName>
</n:PartyName>
All user has to
do is include the above semantic values that do not exist in the default “PersonNameElementList”
code list (e.g. Birth Street, Father Name, Country Of Birth, State of Birth,
Country Of Origin) without modifying the core xNL.xsd schema.
Using
customisable code list approach provided by CIQ Specifications,
interoperability of data (represented using CIQ Specifications) between applications
can be significantly improved. Any attribute/element that can add semantic
meaning to data (e.g. type of address, where the value “Airport” adds semantic
meaning to an address data) is defined as a customisable code list in CIQ
Specifications. For example, PersonName element in xNL.xsd uses
an attribute PersonIDType that provides a default code list, but with no
default values. When a code list has no values, XML Parsers treat the
attribute/element that references the code list as the same XML schema data
type defined for that element/attribute. This allows an application to define
any value for the data type without any restriction. This could result in
interoperability breakdown between the sending application and the receiver
application because the receiving application needs to know the value of the
data type that is passed for further processing and it is unknown at run time. To
improve interoperability by controlling the use of the values for the data type,
users SHOULD define specific values in the code list during design time, and
importantly these values SHOULD be agreed at design time by the parties
exchanging the data. This will give confidence to the users that the data
exchanged during application run time conforms to the code list values that
have been agreed during application design time.
To provide enough
flexibility to users to define the semantics of the data, over 100 default code
lists (most of them are empty, i.e., no default code values are provided) are
provided by CIQ Specifications that are customisable by users to improve
interoperability of data.
CIQ
Specifications provide TWO OPTIONS for users to define and manage code lists.
The options are:
·
OPTION 1: An XML
schema file per CIQ entity (Name, Address and Party) representing
all code lists for the entity is provided as part of the specification. The enumeration/code
list files are xNL-types.xsd (for Name Entity code lists),
xAL-types.xsd (For Address Entity code lists), xNAL-types.xsd
(for Name and Address Entities code list) and xPIL-types.xsd
(for Party Entity code lists). This is the “DEFAULT” approach for using
code lists.
·
OPTION 2: A
genericode based code list file (.gc) per code list for all CIQ entities (Name,
Address and Party) is provided as part of the specification.
Genericode is an OASIS industry specification for representing code lists. For
example, xNL-types.xsd file has 13 code lists in Option 1, and these
code lists are represented as 13 individual genericode (.gc) files in this
option. Therefore, xNL-types.xsd, xAL-types.xsd, xNAL-types.xsd,
and xPIL-types.xsd Code List schemas are not part of this option and
instead, are replaced with .gc files.
Users MUST choose one of the above two options as part of
the specification implementation, but MUST NOT use both the options in the same
implementation.
Option 2 (Genericode
approach) uses a “two pass validation” methodology (explained in the later
sections) on a CIQ XML document instance (first pass for XML document
structural and lexical validation against the core CIQ XML schema (xNL.xsd)
and second pass for validation of code list value in the XML document).
CIQ
specifications are normally embedded/implemented as part of any broader
application specific schema such as customer information management, postal
services, identity management, human resource management, financial services, etc.
The application specific schema MAY or MAY NOT implement genericode approach to
code lists. If only Option 2 is provided as part of the CIQ specifications, end
users implementing CIQ XML schema that is included as part of their application
specific schema to represent party data, will be forced to perform two pass
validation on the application’s XML document instance and in particular, on the
fragments in the XML document where party data is represented using CIQ. This
limits the usage of CIQ specifications for wider adoption and hence, two
options are provided to enable end users to pick an approach that suits their
requirements. The two options are explained in detail in the following sections.
“Include” code
lists are XML schemas that are “included” in the CIQ entity structure XML
schemas, i.e., xNL.xsd (Name Entity schema) “includes” xNL-types.xsd
code list schema (as shown in the sample code below), xAL.xsd (Address
Entity schema) “includes” xAL-types.xsd code list schema, xNAL.xsd
schema “includes” xNAL-types.xsd code list schema, and xPIL.xsd
(party entity schema) “includes” xPIL-types.xsd schema.
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns="urn:oasis:names:tc:ciq:xnl:3" xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:ct="urn:oasis:names:tc:ciq:ct:3"
targetNamespace="urn:oasis:names:tc:ciq:xnl:3"
elementFormDefault="qualified"
attributeFormDefault="qualified">
<xs:include schemaLocation="xNL-types.xsd"/>
<!—code list schema included -à
Users MAY modify
the code list XML schema to add or delete values depending upon their data
exchange requirements without modifying the structure of the CIQ entity
schemas. Validation of the code list values will be performed by XML parsers as
part of the XML document instance validation in “one” pass (i.e., XML document
structure validation and the code list value validation will be performed in
one pass).
Any changes to
the code list schema results in changes to the software code (e.g. java object generated
from xNL.xsd using XML Beans must be re-created) based on the entity
schema as the entity schema “includes” the code list schema.
The values of
code lists provided as part of CIQ Specifications v3.0 are only sample values (and
in most cases, no values are provided) and by no means are accurate or complete
list of values. It is up to the users to customise the default code list.
However, when exchanging data with more than one party (trading partner or
application), it is important that all the concerned parties SHOULD be aware of
the code list and the values that will be used as part of the data exchange
process to achieve interoperability.
The following example shows an XML schema representation
of code list for SubDivisionTypeList provided by CIQ specification as
part of xNL-types.xsd.
<xs:simpleType
name=SubDivisionTypeList”>
<xs:annotation>
<xs:documentation>
A list of common types for sub divisions
</xs:documentation>
</xs:annotations>
<xs:restriction base=”xs:string”>
<xs:enumeration value=”Department”/>
<xs:enumeration
value=”Branch”/>
<xs:enumeration
value=”Business Unit”/>
<xs:enumeration
value=”School”/>
<xs:enumeration
value=”Section”/>
</xs:restriction>
</xs:simpleType>
In the following example, the code list “OrganisationNameTypeList”
under “xNL-types.xsd” is customised by replacing the default values with
new values to meet user requirements.
|
Default values for “OrganisationNameTypeList”
Code List
|
Customised values
|
|
LegalName
|
ReportedName
|
|
NameChange
|
OriginalName
|
|
CommonUse
|
LegalName
|
|
PublishingName
|
|
|
OfficialName
|
|
|
UnofficialName
|
|
|
Undefined
|
|
The code for the specification with the
original code list for “OrganisationNameTypeList” would look like the
following:
<xs:simpleType name="OrganisationNameTypeList">
<xs:restriction base="xs:string">
<xs:enumeration value="LegalName"/>
<xs:enumeration value="NameChange"/>
<xs:enumeration value="CommonUse"/>
<xs:enumeration value="PublishingName"/>
<xs:enumeration value="OfficialName"/>
<xs:enumeration value="UnofficialName"/>
<xs:enumeration value="Undefined"/>
</xs:restriction>
</xs:simpleType>
The code for the new customised code list for
“OrganisationNameTypeList” would look like the following:
<xs:simpleType name="OrganisationNameTypeList">
<xs:restriction base="xs:string">
<xs:enumeration value="ReportedName"/>
<xs:enumeration value="OriginalName"/>
<xs:enumeration value="LegalName"/>
</xs:restriction>
</xs:simpleType>
This level of flexibility allows customisation
of the xNL.xsd schema through changing the code lists only, without
changing the basic structure of the xNL.xsd schema. It is important to
ensure that all schema users involved in data exchange SHOULD use the same code
lists for interoperability to be successful. This SHOULD be negotiated between
the data exchange parties and a proper governance process SHOULD be in place to
manage this process.
Assume that participants of a data exchange process agreed
that for their purpose only a very simple name structure is required. One of
the options for them is to modify PersonNameElementsList code list in the
xNL-types.xsd file with the following values and remove the rest of the
default values provided by the specification:
<xs:simpleType name="PersonNameElementsList">
<xs:restriction base="xs:string">
<xs:enumeration value="Title"/>
<xs:enumeration value="FirstName"/>
<xs:enumeration value="MiddleName"/>
<xs:enumeration value="LastName"/>
</xs:restriction>
</xs:simpleType>
In Russia, it would be more appropriate to use the
following enumeration:
<xs:simpleType name="PersonNameElementList">
<xs:restriction base="xs:string">
<xs:enumeration value="Title"/>
<xs:enumeration value="Name"/>
<xs:enumeration value="FathersName"/>
<xs:enumeration value="FamilyName"/>
</xs:restriction>
</xs:simpleType>
Again, it is up to the implementers involved in data
exchange to modify PersonNameElementList code list in xNL-types.xsd
file.
Option 1 is the
default approach for CIQ Specifications to use code lists. However, users are
given the choice to use Option 2 instead of Option 1. It is up to the users to
decide which approach to use and this is based on their requirements.
The OASIS Code
List Representation format, “Genericode”, is a single industry model and
XML format (with a W3C XML Schema) that can encode/standardise a broad range of
code list information. The XML format is designed to support interchange or
distribution of machine-readable code list information between systems. Details
about this specification are available at: http://www.oasis-open.org/committees/codelist.
Let us consider
an instance where trading partners who use CIQ
Specifications for exchanging party related data. The trading partners MAY wish
to agree that different sets of values from the same code lists MAY be allowed
at multiple locations within a single document (perhaps allowing the state for
the buyer in an order is from a different set of states than that allowed for
the seller). Option 1 approach MAY not be able to accommodate such differentiation
very elegantly or robustly, or possibly could not be able to express such
varied constraints due to limitations of the schema language's modelling
semantics. Moreover it is not necessarily the role of CIQ entity schemas to
accommodate such differentiation mandated by the use of it. Having a methodology and supporting document types with which to
perform code list value validation enables parties involved in document
exchange to formally describe the sets of coded values that are to be used and
the document contexts in which those sets are to be used. Such a formal and
unambiguous description SHOULD then become part of a trading partner
contractual agreement, supported by processes to ensure the agreement is not
being breached by a given document instance.
This Option uses
a “two” pass validation methodology, whereby, the “first” pass validation,
allows the XML document instance to be validated for its structure and well-formedness
(ensures that information items are in the correct places and are correctly
formed) against the entity XML schema, and the “second” pass validation allows
the code list values in XML document instance to be validated against the
genericode based code lists and this does not involve the entity schemas.
Any change to
the genericode based code list does not require changes to the software code
(e.g. java object must be re-created) based on the entity schema as the entity
schema reference the genericode based code list.
OASIS Code List Technical Committee
describes an approach called “Context Value Association (CVA)” for using the
“two” validation approach as discussed in the previous section. CVA describes the file format used in a "context/value
association" file (termed in short as "a CVA file"). This file
format is an XML vocabulary using a subset of W3C XPath 1.0 to specify
hierarchical document contexts and the associated controlled vocabulary of
values allowed at each context. A document context specifies one or more
locations found in an XML document or other similarly structured hierarchy.
This file format specification assumes the controlled vocabulary of values is
expressed in an external resource described by the genericode OASIS standard.
Context/value association is useful in
many aspects of working with an XML document using controlled vocabularies. Two
examples are (1) for the direction of user data entry in the creation of an XML
document, ensuring that only valid values are proffered in a user interface
selection such as a drop-down menu; and (2) for the validation of the correct
use of valid values found in an XML document.
CVA enables validating code list values
and supporting document types with which trading partners can agree
unambiguously on the sets of code lists, identifiers and other enumerated
values against which exchanged documents must validate. The objective of
applying CVA to a set of document instances being validated is to express the
lists of values that are allowed in the context of information items found in
the instances. One asserts that particular values must be used in particular
contexts, and the validation process confirms the assertions do not fail.
Schemata
describe the structural and lexical constraints on a document. Some information
items in a document are described in the schema lexically as a simple value
whereby the value is a code representing an agreed-upon semantic concept. The
value used is typically chosen from a set of unique coded values enumerating
related concepts. CVA is in support of the second pass of a two-pass validation
strategy, where the “first pass” confirms the structural and lexical
constraints of a document and the “second pass” confirms the value constraints
of a document.
The “first
pass” can be accomplished with an XML document schema language such as W3C
Schema or ISO/IEC 19757-2 RELAX NG; “the second pass” is accomplished with a
transformation language such as a W3C XSLT 1.0 stylesheet or a Python program. In
this specification, the second pass is an implementation of ISO/IEC 19757-3
Schematron schemas that are utilised by CVA.
ISO Schematron is a powerful and yet
simple assertion-based schema language used to confirm the success or failure
of a set of assertions made about XML document instances. One can use ISO
Schematron to express assertions supporting business rules and other
limitations of XML information items so as to aggregate sets of requirements
for the value validation of documents.
In the figure below, “Methodology context
association” depicts a file of context/value associations in the lower centre,
where each association specifies for information items in the document instance
being validated which lists of valid values in external value list expressions
are to be used.
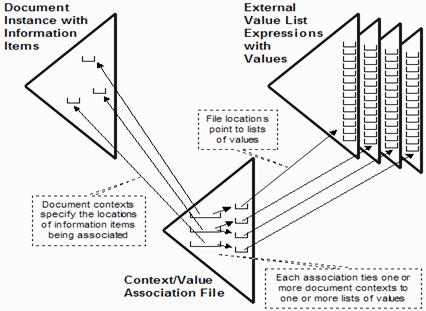
The synthesis of a pattern of ISO
Schematron assertions to validate the values found in document contexts, and
the use of ISO Schematron to validate those assertions are illustrated in
“Methodology overview” figure below.
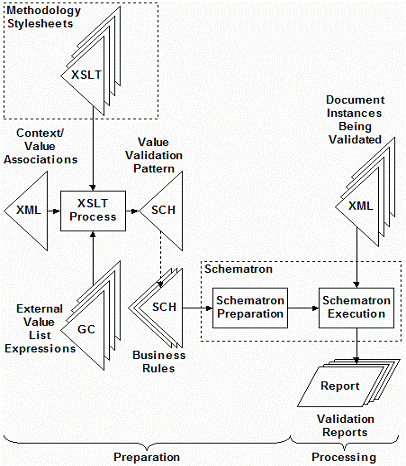
To feed the ISO Schematron process, one
needs to express the contexts of information items and the values used in those
contexts. CVA prescribes an XML vocabulary to create instances that express such
associations of values for contexts. The stylesheets provided with CVA read these
instances of context/value associations that point to externally-expressed
lists of values and produce an ISO Schematron pattern of assertions that
can then be combined with other patterns for business rule assertions to
aggregate all document value validation requirements into a single process. The
validation process is then used against documents to be validated, producing
for each document a report of that document's failures of assertions.
By using CVA, users can
use a default code list values for data exchange by adding more values to the
default code list or restricting the values in the default code lists by
defining constraints and business rules.
The following example shows Genericode representation of
code list for SubDivisionTypeList represented in a file called “SubDivisionTypeList.gc”.
<CodeList>
<SimpleCodeList>
<Row>
<Value
ColumnRef=”code”>
<SimpleValue>Department</SimpleValue> <!—- code list value -à
</Value>
<Value
ColumnRef=”name”>
<SimpleValue>Department</SimpleValue> <!—- description of the
value-à
</Value>
</Row>
<Row>
<Value
ColumnRef=”code”>
<SimpleValue>Division</SimpleValue>
</Value>
<Value
ColumnRef=”name”>
<SimpleValue>Division</SimpleValue>
</Value>
</Row>
<<Row>
<Value
ColumnRef=”code”>
<SimpleValue>Branch</SimpleValue>
</Value>
<Value
ColumnRef=”name”>
<SimpleValue>Branch</SimpleValue>
</Value>
</Row>
<Row>
<Value
ColumnRef=”code”>
<SimpleValue>BusinessUnit</SimpleValue>
</Value>
<Value
ColumnRef=”name”>
<SimpleValue>BusinessUnit</SimpleValue>
</Value>
</Row>
<Row>
<Value
ColumnRef=”code”>
<SimpleValue>Section</SimpleValue>
</Value>
<Value
ColumnRef=”name”>
<SimpleValue>Section</SimpleValue>
</Value>
</Row>
</SimpleCodeList>
</CodeList>
Taking the same example of customising
code lists in Option 1, OrganisationNameTypeList code list will be a
separate file called “OrganisationNameTypeList.gc”. To create a
completely new set of code lists to replace the default one, a new .gc file
with the new set of code list values say, “ReplaceOrganisationNameTypeList.gc”
is created. By applying the constraints rule in a separate file, this new code
list replaces the default code list.
The process of customising the
code lists is documented in CVA
for code list and value validation.
The OASIS Code List Technical
Committee has used OASIS CIQ Specification V3.0’s Name entity (xNL.xsd)
as a case study to demonstrate to end users how genericode based code list
approach can be used to replace XML schema approach to validate code lists (the
default approach used by CIQ Specifications). This document is listed in the
reference section.
Following are the documents that
users of CIQ Specifications implementing Genericode based Code List (Option 2) approach
MUST read and understand:
·
OASIS Codelist Representation (Genericode) Version 1.0, Committee
Specification 01, December 2007, http://www.oasis-open.org/committees/codelist
·
Context Value Association, Working Draft 0.2, November
2007, http://www.oasis-open.org/committees/codelist
·
OASIS Code List Adaptation Case Study (OASIS
CIQ), 2007, http://www.oasis-open.org/committees/codelist
3.5 Code List Packages –
Option 1 and Option 2
CIQ Specification comes with two
sets of supporting CIQ entity XML schema packages, one for Option 1 and the
other for Option 2 of code lists. To assist users in getting a quick
understanding of Option 2, all code lists for CIQ specifications are
represented as genericode files along with default constraints, appropriate XSLT
to process code lists, and with sample test XML document instance examples. It
also contains test scenarios with customised code lists from the default code
lists along with business rules, constraints supporting the customised code
lists, XSLT and sample XML document instance examples.
The CIQ Specification entity
schemas (xNL.xsd, xAL.xsd, xPIL.xsd, and xNAL.xsd) for both
option 1 and 2 are in the same namespaces as users will use one of the two.
A separate document titled, “CIQ
Specifications V3.0 Package” explains the structure of the CIQ Specifications
V3.0 package.
Section 7.4 explains the differences between the CIQ Core Entity schemas used
in Option 1 and Option 2.
Order of name
elements MUST be preserved for correct presentation (e.g. printing name
elements on an envelope).
If an
application needs to present the name to a user, it MAY not always be aware
about the correct order of the elements if the semantics of the name elements
are not available.
Mr Jeremy Apatuta Johnson PhD
could be presented as follows
<n:PartyName>
<n:PersonName>
<n:NameElement>Mr</n:NameElement>
<n:NameElement>Jeremy</n:NameElement>
<n:NameElement>Apatuta</n:NameElement>
<n:NameElement>Johnson</n:NameElement>
<n:NameElement>PhD</n:NameElement>
</n:PersonName>
</n:PartyName>
and restored back to Mr Jeremy Apatuta Johnson PhD.
Any other order of NameElement tags in the XML fragment
could lead to an incorrect presentation of the name.
Mapping data
between the xNL schema and a target database is not expected to be problematic
as xNL provides enough flexibility for virtually any level of data
decomposition. However, the main issue lies in the area of mapping a data
provider with a data consumer through xNL.
For example,
consider a data provider that has a person name in one line (free text and
unparsed) and a data consumer that has a highly decomposed data structure for a
person’s name requires first name, family name and title to reside in their
respective fields. There is no way of strong the free text and unparsed data in
the target data structure without parsing it first using some smart name
parsing data quality parsing/scrubbing tool (there are plenty in the market).
Such parsing/scrubbing is expected to be the responsibility of the data
consumer under this scenario and importantly, agreeing in advance with the data
provider that the incoming data is not parsed.
The source
database easily maps to the xNL NameElement qualified with the ElementType
attribute set to values as in the diagram
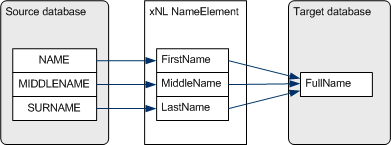
Source Database
|
NAME
|
MIDDLENAME
|
SURNAME
|
|
John
|
Anthony
|
Jackson
|
xNL
<n:PersonName>
<n:NameElement
n:ElementType="FirstName">John</n:NameElement>
<n:NameElement
n:ElementType="MiddleName">Anthony</n:NameElement>
<n:NameElement n:ElementType="LastName">Jackson</n:NameElement>
</n:PersonName>
Target Database
|
FULLNAME
|
|
John Anthony Jackson
|
This type of
mapping does not present a major challenge as it is a direct mapping from
source to xNL and then concatenating the data values to form the full name to
be stored in a database field/column.
The source
database has the name in a simple unparsed form which can be easily mapped to xNL,
but cannot be directly mapped to the target database as in the following
diagram:
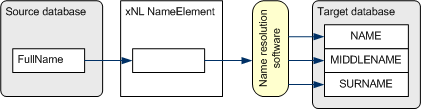
Source Database
|
FULLNAME
|
|
John Anthony Jackson
|
xNL
<n:PersonName>
<n:NameElement>John Anthony Jackson</n:NameElement>
</n:PersonName>
At this point,
the name resolution/parsing software splits John Anthony Jackson into a
form acceptable by the target database.
Target Database
|
NAME
|
MIDDLENAME
|
SURNAME
|
|
John
|
Anthony
|
Jackson
|
The
quality of any information management/processing system is only as good as the
quality of the data it processes/stores/manages. No matter how
efficient is the process to interoperate data, if the quality of data that is
interoperated is poor, the business benefit arising out of the information
processing system is expected to be poor. To structurally represent the
data, understand the semantics of the data to integrate and interoperate the
data, quality of the data is critical. CIQ specifications have been designed
with the above principle in mind.
xNL schema
allows for data quality information to be provided as part of the entity using an
attribute DataQuality that can be set to either “Valid” or “Invalid”
(default values), if such status is known. If DataQuality attribute is
omitted, it is presumed that the validity of the data is unknown. Users can customise
the DataQuality code list to add more data quality attributes (e.g. confidence
levels) if required.
DataQuality attribute refers to the content of a container, e.g. PersonName,
asserting that all the values are known to be true and correct in a particular
defined period. This specification also has provision to define partial data
quality where some parts of the content are correct and some are not or
unknown.
<n:PersonName n:DataQuality="Valid"
n: ValidFrom="2001-01-01T00:00:00"
<n:NameElement>John Anthony Jackson</n:NameElement>
</n:PersonName>
In this example John Anthony Jackson is known to be
the true and correct value asserted by the sender of this data and the validity
of the data has been recorded as of 2001-01-01.
This feature
allows the recipient of data to get an understanding of the quality of data
they are receiving and thereby, assists them to take appropriate measures to
handle the data according to its quality.
This
specification does not mandate any data verification rules or requirements. It
is entirely up to the data exchange participants to establish them.
Also, the
participants need to establish if the data quality information can be trusted.
This
specification does not mandate any data validation rules or requirements. It is
entirely up to the data exchange participants to establish such rules and
requirements.
All elements in Name,
Address and Party namespaces support extensibility by allowing
for any number of attributes from a non-target namespace to be added. This is
allowed in the XML Schema specifications of CIQ.
All elements
share the same declaration:
<xs:anyAttribute namespace="##other"
processContents="lax"/>
Although this
specification provides an extensibility mechanism, it is up to the participants
of the data exchange process to agree on the use of any extensions to the
target namespace. Extensions without agreements between parties involved in
data exchange will break interoperability.
This
specification mandates that an application SHOULD not fail if it encounters an
attribute from a non-target namespace. The application MAY choose to ignore or
remove the attribute.
CIQ
Specifications does its best to provide the minimum required set of elements
and attributes that are commonly used independent of applications to define
party data (name, address and other party attributes). If specific applications
require some additional set of attributes that are not defined in CIQ
specifications, then this extensibility mechanism SHOULD be used provided the
extensions are agreed with other parties in case of data exchange involving
more than one application. If no agreement is in place to manage extensions to
the specification, interoperability will not be achieved. Use of this
extensibility mechanism SHOULD be governed.
Participants involved in data exchanges MAY wish to add
their system specific identifiers for easy matching of known data, e.g. if
system A sends a message containing a name of a person to system B as in the
example below
<n:PartyName xmlns:b="urn:acme.org:corporate:IDs" b:PartyID="123445">
<n:PersonName>
<n:NameElement>John Johnson</n:NameElement>
</n:PersonName>
</n:PartyName>
then Attribute b:PartyID="123445" is not
in xNL namespace and acts as an identifier for system A. When system B returns
a response or sends another message and needs to include information about the
same party, it MAY use the same identifier as in the following example:
<n:PartyName xmlns:b="urn:acme.org:corporate:IDs" b:PartyID="123445"
/>
The response could include the original payload with the
name details.
Sometimes it MAY be required to include some additional
metadata that is specific to a particular system or application. Consider these
examples:
<n:PartyName xmlns:x="urn:acme.org:corporate" x:OperatorID="buba7">
.............
<n:PartyName xmlns:b="urn:acme.org:corporate ">
<n:PersonName>
<n:NameElement b:Corrected="true">John
Johnson</n:NameElement>
</n:PersonName>
</n:PartyName>
In the above examples, “OperatorID” and
“Corrected” are additional metadata added to “PartyName” from different
namespaces without breaking the structure of the schema.
Linking and
referencing of different resources such as Party Name or Party Address
(internal to the document or external to the document) can be achieved by two
ways. It is important for parties involved in data exchange SHOULD decide
during design time the approach they will be implementing. Implementing both
the options will lead to interoperability problems. Just choose one. The two
options are:
-
Using xLink
-
Using Key Reference
CIQ has now included
support for xLink style referencing. These attributes are
OPTIONAL and so will not impact implementers who want to ignore them. The
xLink attributes have been associated with extensible type entities
within the CIQ data structure thereby allowing these to be externally referenced
to support dynamic value lists. The xBRL (extensible Business
Reporting Language) standards community for example, uses this approach
extensively to indicate the type values of objects in the data structure.
Names can be
referenced internally (i.e. within some XML infoset that contains both
referencing and referenced elements) through xlink:href pointing at an
element with xml:id with a matching value. External entities can also be
referenced if they are accessible by the recipient via HTTP(s)/GET.
The following
example illustrates PartyName elements that reference other PartyName
elements that reside elsewhere, in this case outside of the document.
<a:Contacts
xmlns:a="urn:acme.org:corporate:contacts" xmlns:n="urn:oasis:names:tc:ciq:xsdschema:xNL:3.0/20050427"
xmlns:xlink="http://www.w3.org/1999/xlink">
<n:PartyName
xlink:href="http://example.org/party?id=123445"
xlink:type="locator"/>
<n:PartyName
xlink:href="http://example.org/party?id=83453485"
xlink:type="locator"/>
</a:Contacts>
This example
presumes that the recipient of this XML fragment has access to resource http://example.org/party
and that the resource returns PartyName element as an XML fragment of text/xml
MIME type.
Usage of xLink
attributes in the CIQ specifications MAY slightly differ from the original xLink
specification. See CIQ TC Party Relationships Specification for more
information on using xLink with xNL [Not
available in this version]. The xLink specification is available
at http://www.w3.org/TR/xlink/.
Element PartyName
can be either of type locator or resource in relation to xLink.
Implementers are
not restricted to only using XLink for this purpose - for example the
xlink:href attribute MAY be re-used for a URL to a REST-based lookup, and so
forth. The intent is to provide additional flexibility for communities of
practice to develop their own guidelines when adopting CIQ.
This approach MAY
be used for internal references (i.e. within some XML infoset that contains both
referencing and referenced elements). Two keys are used to reference an entity
namely, Party and Address. Two keys are:
1.
Key – Primary Key
of the entity, and
2.
KeyRef – Foreign
Key to reference an entity
The following
example illustrates PartyName elements that reference other PartyName
elements that reside elsewhere, in this case inside the document.
<c:Customers
xmlns:c="urn:acme.org:corporate:customers"
xmlns:a="urn:oasis:names:tc:ciq:xal:3"
xmlns:n="urn:oasis:names:tc:ciq:xnl:3"
xmlns:p="urn:oasis:names:tc:ciq:xpil:3"
<p:Party PartyKey=”111”>
<n:PartyName>
<n:PersonName>
<n:NameElement n:ElementType=”FirstName”>Ram</n:NameElement>
<n:NameElement n:ElementType=”LastName”>Kumar</n:LastName>
</n:PersonName>
</n:PartyName>
<p:Party p:PartyKey=”222”>
<n:PartyName>
<n:PersonName>
<n:NameElement n:ElementType=”FirstName”>Joe</n:NameElement>
<n:NameElement n:ElementType=”LastName”>Sullivan</n:LastName>
</n:PersonName>
</n:PartyName>
</p:Party>
<c:Contacts>
<c:Contact c:PartyKeyRef=”222”>
<c:Contact c:PartyKeyRef=”111”>
<c:/Contacts>
</c:Customers>
Attribute ID
is used with complex type PersonNameType and elements PersonName
and OrganisationName. This attribute allows unique identification of the
collection of data it belongs to. The value of the attribute MUST be unique
within the scope of the application of xNL and the value MUST be globally
unique. The term ‘globally unique’ means a unique identifier that is
“mathematically guaranteed” to be unique. For example, GUID (Globally Unique
Identifier) is a unique identifier that is based on the simple principle that
the total number of unique keys (or) is so large that the possibility of the
same number being generated twice is virtually zero.
This unique ID
attribute SHOULD be used to uniquely identify collections of data as in the
example below:
Application A supplies an xNL fragment containing
some PersonName to Application B. The fragment contains attribute ID
with some unique value.
<n:PartyName
n:ID="52F89CC0-5C10-4423-B367-2E8C14453926">
<n:PersonName>
<n:NameElement>Max Voskob</n:NameElement>
</n:PersonName>
<n:OrganisationName>
<n:NameElement>Khandallah Laundering
Ltd.</n:NameElement>
</n:OrganisationName>
</n:PartyName>
If Application B decides to reply to A and
use the same xNL fragment it need only provide the outer element (n:PartyName
in this case) with ID as the only attribute.
<n:PartyName n:ID="52F89CC0-5C10-4423-B367-2E8C14453926"
/>
Application A should recognise the value of ID,
so no additional data is required from B in relation to this.
The exact
behaviour of the ID attribute is not specified in this document and is
left to the users to decide and implement.
The difference
between the ID attribute and xLink attributes is that ID
attribute cannot be resolved to a location of the data – it identifies already
known data.
Any XML
documents produced MUST conform to the CIQ Specifications Schemas namely, xNL.xsd,
xAL.xsd, xNAL.xsd and xPIL.xsd i.e. the documents MUST be successfully
validated against the Schemas. This assumes that the base schemas MUST be modified.
If Option 2 for
Code List is used, all genericode files MUST conform to the Genericode XML
Schema, i.e. all genericode files MUST successfully validate against the
schema.
Any
customisation of the code list files based on Option 1 MUST be well formed
schemas.
The broad nature
and cultural diversity of entity “Name” makes it very difficult to produce one
schema that would satisfy all applications and all cultures while keeping the
size and complexity of the schema manageable. This specification allows some
changes to the schema by adopters of the schema to fit their specific
requirements and constraints. However, note that any change to the schema
breaks the CIQ Specifications compatibility and so, they MUST NOT be changed.
The namespace
identifier SHOULD be changed if it is possible for an XML fragment valid under
the altered schema to be invalid under the original schema.
Users SHOULD retain the minimum structure of
Name entity as in the following diagram:
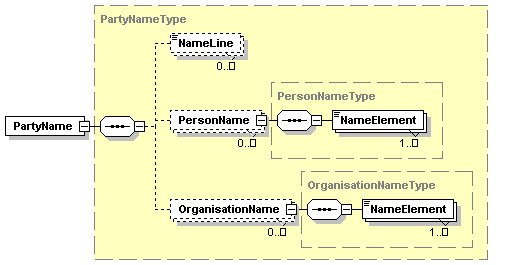
This structure
allows for most names to be represented, with exception for
·
organisation subdivision hierarchy (SubdivisionName),
e.g. faculty / school / department
Any further
reduction in structure MAY lead to loss of flexibility and expressive power of
the schema.
Users MUST NOT
remove any attributes from the schema. Attributes in the schema can be easily
ignored during the processing.
3.13.2.1
Implications of changing Name Entity Schema
Any changes to
the Name Entity schema (xNL.xsd) are likely to break the compatibility
one way or another.
It MAY be
possible that an XML fragment created for the original schema is invalid for
the altered schema or vice versa. This issue SHOULD be considered before making
any changes to the schema that could break the compatibility.
Meeting all
requirements of different cultures and ethnicity in terms of representing the
names in one specification is not trivial. This is the reason why code lists/enumerations
are introduced in order to keep the specification/schema simple, but at the
same time provide the flexibility to adapt to different requirements.
The values of
the code lists/enumerations can be changed or new ones added as required.
NOTE: The code list/enumeration values
for different enumeration lists that are provided as part of the specification
are not complete. They only provides some sample values (and in most cases no
values) and it is up to the end users to customise them to meet their data
exchange requirements if the default values are incomplete, not appropriate or
over kill
This level of flexibility allows
some customisation of the schema through changing the code list/enumerations only,
without changing the basic structure of the schema. It is important to ensure
that all schema users involved in data exchange use the same code list/enumerations
for interoperability to be successful. This has to be negotiated between the
data exchange parties and a proper governance process SHOULD be in place to
manage this process.
The other approach to customise
the CIQ Name schema (includes other entity schemas namely Party and Address) without
touching it is by using CVA.
In this approach, one can use Schematron patterns to define assertion rules to customise
the xNL.xsd schema without modifying it. For example, it is possible to customise
xNL.xsd schema to restrict the use of elements, the occurrence of
elements, the use of attributes, and the occurrence of attributes, making
elements and attributes mandatory, etc.
So, users who believe that many
elements and attributes in the CIQ specifications are overwhelming to what
their requirements are, can define business rules using Schematron patterns to
constraint the CIQ base entity schemas. By constraining the CIQ schemas, users
get two major benefits:
·
CIQ Specifications that are tailored indirectly with the help of
business rules to meet specific application requirements
·
Applications that use the customised CIQ Specifications with the
help of business rules are still compliant with the CIQ Specifications.
Therefore, by CIQ specifications
providing two options for customising schemas (Option 1 and Option 2), the
specifications are powerful to address any specific application requirements
for party information.
NOTE: The
business rules used to constraint base schemas SHOULD be agreed by all the
parties that are involved in CIQ based data exchange to ensure interoperability
and the rules SHOULD be governed.
xNL.xsd uses “NameElement” element as part of
“PersonName” element to represent the name of a person and this is supported by
using the attribute “ElementType” to add semantics to the name. Let us look at
the following example:
<n:PersonName>
<n:NameElement
n:ElementType=”FirstName>Paruvachi</n:NameElement>
<n:NameElement
n:ElementType=”FirstName>Ram</n:NameElement>
<n:NameElement
n:ElementType=”MiddleName>Kumar</n:NameElement>
<n:NameElement
n:ElementType=”LastName>Venkatachalam</n:NameElement>
<n:NameElement
n:ElementType=”LastName>Gounder</n:NameElement>
</n:PersonName>
In the above example, there is no restriction on the
number of times First Name and Last Name can occur as per
xNL.xsd schema grammar. Some applications might want to apply strict
validation and constraint rules on the xNL.xsd schema to avoid use of First
Name and Last Name values to data at least once and no more than
once. This is where CVA can
be used to define business rules to constraint the xNL.xsd schema
without modifying the xNL.xsd schema. The business rule code defined
using Schematron pattern for the above constraint is given below:
<rule
context=”n:PersonName[not(parent::n:PartyName)]”>
<assert
test=count(n:NameElement [@n:ElementType=’FirstName’]=1”
>Must
have exactly one FirstName component</assert>
<assert
test=count(n:NameElement[@n:ElementType=’LastName’])=1”
>Must
have exactly one LastName component</assert>
</rule>
When first pass validation (structure validation) is
performed on the above sample XML instance document, the document is valid
against the xNL.xsd. During second pass validation (business rule
constraint and value validation) on the above XML instance document, the
following error is reported:
Must
have exactly one FirstName component
Must
have exactly one LastName component
Entity “Address”
has been modelled independent of any context as a standalone class to reflect some
common understanding of concepts “Location” and “Delivery Point”.
The design
concepts for “Address” are similar to “Name”. Refer to section 2.4
Common Design Concepts for more information.
The high level schema elements of xAL
schema are illustrated in the diagram in the next page.
An address can be structured according to
the complexity level of its source.
Suppose that the source database does not differentiate
between different address elements and treats them as Address Line 1, Address
Line 2, Address Line “N”, the address information can then be placed inside a
free text container (element FreeTextAddress).
<a:Address>
<a:FreeTextAddress>
<a:AddressLine>Substation C</a:AddressLine>
<a:AddressLine >17 James Street</a:AddressLine
>
<a:AddressLine>SPRINGVALE VIC
3171</a:AddressLine>
</a:FreeTextAddress>
</a:Address>
It is up to the receiving application to parse this
address and map it to the target data structure. It is possible that some sort
of parsing software or human involvement will be required to accomplish the
task. Data represented in this free formatted text form is classified as “poor
quality” as it is subject to different interpretations of the data and will
cause interoperability problems.
Many common applications fall under this category.
Assume that the address was captured in some
semi-structured form such as State, Suburb and Street.
<a:Address>
<a:AdministrativeArea>
<a:Name>WA</a:Name>
</a:AdministrativeArea>
<a:Locality>
<a:Name>OCEAN REEF</a:Name>
</a:Locality>
<a:Thoroughfare>
<a:NameElement>16 Patterson Street</a:NameElement>
</a:Thoroughfare>
</a:Address>
In this example, the free text information resides in
containers that provide some semantic information on the content. E.g. State
-> AdministrativeArea, Suburb -> Locality, Street -> Thoroughfare. At
the same time, the Thoroughfare element contains street name and number in one
line as free text, which MAY not be detailed enough for data structures where
street name and number are separate fields.
Many common applications fall under this category.
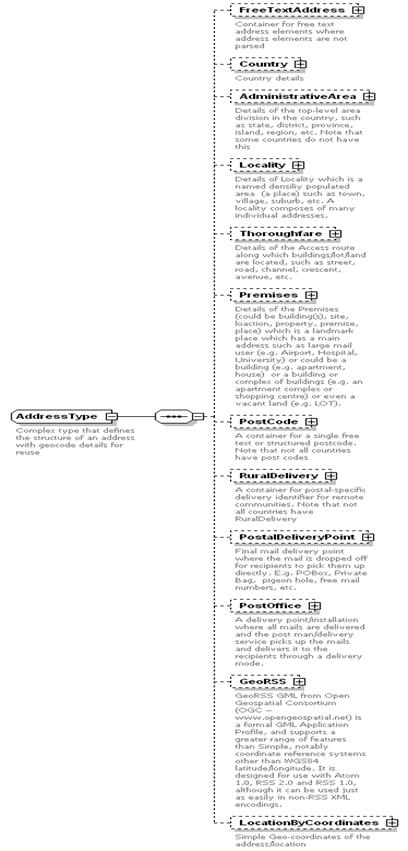
The following example illustrates an address structure
that was decomposed into its atomic elements:
<a:Address>
<a:AdministrativeArea a:Type="state">
<a:NameElement a:Abbreviation="true"
a:NameType="Name">VIC</a:NameElement>
</a:AdministrativeArea>
<a:Locality a:Type="suburb">
<a:NameElement a:NameType="Name">CLAYTON</a:NameElement>
<a:SubLocality a:Type="Area">
<a:NameElement a:NameType="Name">Technology Park</a:NameElement>
</a:SubLocality>
</a:Locality>
<a:Thoroughfare a:Type="ROAD">
<a:NameElement a:NameType="NameandType">Dandenong Road</a:NameElement>
<a:Number a:IdentifierType="RangeFrom">200</a:Number>
<a:Number a:IdentifierType="Separator">-</a:Number>
<a:Number a:IdentifierType="RangeTo">350</a:Number>
<a:SubThoroughfare a:Type=”AVENUE”>
<a:NameElement a:NameType="NameAndType">Fifth Avenue</a:NameElement>
</a:SubThoroughfare>
</a:Thoroughfare>
<a:Premises a:Type="Building">
<a:NameElement a:NameType="Name">Toshiba Building</a:NameElement>
</a:Premises>
<a:PostCode>
<a:Identifier>3168</a:Identifier>
</a:PostalCode>
</a:Address>
Few
applications and in particular, applications dealing with data quality and integrity,
fall under this category and the quality of data processed by these
applications are generally high.
All elements and
attributes in xAL schema have strong data types.
All free-text
values of elements (text nodes) and attributes are constrained by a simple type
“NormalizedString” (collapsed white spaces) defined in CommonTypes.xsd.
Other XML Schema data types are also used throughout the schema.
Other XML Schema
defined data types (e.g. int, string, DateTime) are also used throughout xAL
namespace.
Use of code
lists/enumerations is identical to use of code lists/enumerations for entity “Name”.
Refer to section 3.3 for more
information.
Code Lists used
in xAL for Option 1 reside in an “include” file xAL-types.xsd and
for option 2 as separate genericode files.
NOTE: The code list values for different
code lists that are provided as part of the specifications are not complete.
They only provides some sample values (and in most cases no values) and it is
up to the end users to customise them to meet their data exchange requirements
if the default values are incomplete, not appropriate or an over kill
Order of address
elements MUST be preserved for correct presentation in a fashion similar to
what is described in section 3.6.
Mapping data
between xAL schema and a database is similar to that of entity “Name”
as described in section 3.7.
23 Archer Street
Chatswood, NSW 2067
Australia
could be presented as follows
<a:Address>
<a:FreeTextAddress>
<a:AddressLine>23 Archer Street</a:AddressLine>
<a:AddressLine>Chatswood, NSW
2067</a:AddressLine>
<a:AddressLine>Australia</a:AddressLine>
</a:FreeTextAddress>
</a:Address>
and restored back to
23 Archer Street
Chatswood,
NSW 2067
Australia
during data formatting exercise.
Any other order of AddressLine tags in the XML
fragment could lead to an incorrect presentation of the address.
xAL schema allows for data quality information to be provided as part
of the entity using attribute DataQuality as for entity “Name”.
Refer to section 3.8 for more
information.
All elements in Address namespace
are extensible as described in section 3.9.
All linking and referencing rules described
in section 3.10 apply to entity
“Address”.
Use of attribute ID is described in section
3.11.
Schema conformance described in section 3.12 is fully applicable to entity “Address”.
xAL supports
representation of Address/location in two ways namely,
1.
By using explicit coordinates with qualifiers
for accuracy and precision, and
2.
By using the GeoRSS application profile, which
expresses decimal degrees coordinates with accuracy and precision, and is
implemented via external namespaces (either ATOM or RSS).
Explicit
coordinates are typically available from the process of geo-coding the street
addresses. Coordinates are expressed in the Latitude and Longitude
elements, including DegreesMeasure, MinutesMeasure, SecondsMeasure, and
Direction. Data quality is expressed as attributes of coordinates
including Meridian, Datum and Projection.
GeoRSS
incorporates a huge body of knowledge and expertise in geographical systems
interoperability that can be reused for our purpose rather than re-inventing
what has already been developed. The basic expression of a:LocationByCoordinate
element in xAL.xsd schema has limits in utility for e-commerce
applications. More interoperable expression of coordinate is possible via
GeoRSS, due to the ability to reduce ambiguity introduced by requirements for
different coordinate systems, units and measurements, or the ability to define
more complex (non-point) geographic features.
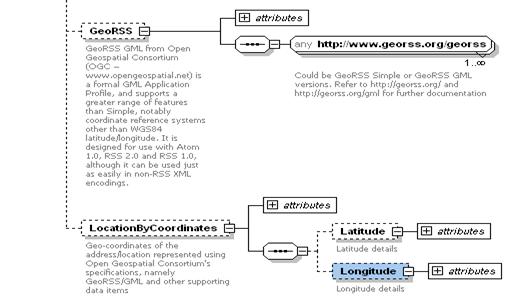
Support for GeoRSS and Location
Coordinates for address/locations in xAL.xsd schema is shown in the
following figure.
As RSS becomes more and more
prevalent as a way to publish and share information, it becomes increasingly
important that location is described in an interoperable manner so that
applications can request,
aggregate,
share
and map
geographically tagged feeds.
GeoRSS (Geographically Encoded
Objects for RSS feeds) enables geo-enabling, or tagging, "really simple
syndication" (RSS) feeds with location information. GeoRSS proposes a
standardised way in which location is encoded with enough simplicity and descriptive
power to satisfy most needs to describe the location of Web content.
GeoRSS MAY not work for every use, but it should serve as an easy-to-use
geo-tagging encoding that is brief and simple with useful defaults but
extensible and upwardly-compatible with more sophisticated encoding standards
such as the OGC (Open Geospatial Consortium) GML (Geography Markup Language).
GeoRSS was developed as a
collaborative effort of numerous individuals with expertise in geospatial
interoperability, RSS, and standards, including participants in the -- the W3C
(World Wide Web Consortium)
and OGC (Open Geospatial Consortium).
GeoRSS is a formal GML
Application Profile, with two flavours: ‘GeoRSS Simple’, which describes a
point, and ‘GeoRSS GML’, which describes four essential types of shapes for
geo-referencing (point, line, box and polygon).
GeoRSS Simple has greater
brevity, but also has limited extensibility. When describing a point or
coordinate, GeoRSS Simple can be used in all the same ways and places as GeoRSS
GML.
GeoRSS GML supports a greater
range of features, notably coordinate reference systems other than WGS84
latitude/longitude. It is designed for use with Atom 1.0, RSS 2.0 and RSS 1.0,
although it can be used just as easily in non-RSS XML encodings.
Further detailed documentation
and sample xml implementation information are published on the sites listed
below:
·
http://georss.org/
·
http://georss.org/gml
·
http://georss.org/atom
The UML model
for the GeoRSS application schema and the XML schema is shown below:
GeoRSS is
supported by an element a:GeoRSS in xAL.xsd schema as a non
target namespace. The content of a:GeoRSS must comply with the following
requirements:
·
Be from the GeoRSS/GML/Atom namespace
·
Refer to finest level of address details available in the address
structure that a:GeoRSS belongs to
·
Be used unambiguously so that there is no confusion whether the
coordinates belong to the postal delivery point (e.g. Post Box) or a physical
address (e.g. flat) as it is possible to have both in the same address
structure.
There is no
restriction on the shape of the area, a:GeoRSS can describe be it a
point, linear feature, polygon or a rectangle.
The following are GeoRSS examples and demonstrate what
GeoRSS Simple and GeoRSS GML encodings look like. The location being specified
is city center Ft. Collins.
Simple GeoRSS:
<georss:point>40.533203 -105.0712</georss:point>
GML GeoRSS:
<GeoRSS:where>
<gml:Point>
<gml:pos>40.533203
-105.0712</gml:pos>
</gml:Point>
<GeoRSS:where>
These examples are in XML. However, RSS and GeoRSS are
general models that can also be expressed in other serializations such as Java,
RDF or XHTML.
A good way to describe a trip that has many places of interest
like a boat trip or a hike is to specify the overall trip's path with a line as
a child of the <feed>. Then mark each location of interest with a point
in the <entry>.
<feed
xmlns="http://www.w3.org/2005/Atom"
xmlns:georss="http://www.georss.org/georss"
xmlns:gml="http://www.opengis.net/gml">
<title>Dino's Mt. Washington trip</title>
<link href="http://www.myisp.com/dbv/"/>
<updated>2005-12-13T18:30:02Z</updated>
<author>
<name>Dino Bravo</name>
<email>dbv@example.org</email>
</author>
<id>http://www.myisp.com/dbv/</id>
<georss:where>
<gml:LineString>
<gml:posList>
45.256 -110.45 46.46 -109.48 43.84 -109.86 45.8 -109.2
</gml:posList>
</gml:LineString>
</georss:where>
<entry>
<title>Setting off</title>
<link href="http://www.myisp.com/dbv/1"/>
<id>http://www.myisp.com/dbv/1</id>
<updated>2005-08-17T07:02:32Z</updated>
<content>getting ready to take the mountain!</content>
<georss:where>
<gml:Point>
<gml:pos>45.256 -110.45</gml:pos>
</gml:Point>
</georss:where>
</entry>
<entry>
<title>Crossing Muddy Creek</title>
<link href="http://www.myisp.com/dbv/2"/>
<id>http://www.myisp.com/dbv/2</id>
<updated>2005-08-15T07:02:32Z</updated>
<content>Check out the salamanders here</content>
<georss:where>
<gml:Point>
<gml:pos>45.94 -74.377</gml:pos>
</gml:Point>
</georss:where>
</entry>
</feed>
If end users
feel that GeoRSS GML is “overkill” or complex for their requirement and
instead, want to just define the coordinates for location/address, xAL.xsd
schema provides a default set of basic and commonly used elements representing
explicit location coordinates through the element a:LocationByCoordinates.
a:LocationByCoordinates element provides attributes namely, Datum, type of code used
for Datum, Meridian, type of code used for Meridian, Projection
and type of code used for Projection.
a:LocationByCoordinates/a:Latitude and a:LocationByCoordinates/a:Longitude elements provide
attributes namely, DegreesMeasure, MinutesMeasure, SecondsMeasure, and Direction.
Schema
customisation rules and concepts described in section 3.13 are fully applicable to entity “Address”.
Addressing the
240+ country address semantics in one schema and at the same time keeping the
schema simple is not trivial. Some countries have a city and some do not, some
countries have counties, provinces or villages and some do not, some countries
use canal names to represent the property on the banks of the canal, and, some
countries have postal codes and some do not.
Key components
of international addresses that vary from country to country are represented in
the specification using the schema elements namely, Administrative Area,
Sub Administrative Area, Locality, Sub Locality, Premises,
Sub Premises, Thoroughfare, and Postal Delivery Point.
CIQ TC chose these names because they are independent of any country specific
semantic terms such as City, Town, State, Street, etc. Providing valid and meaningful
list of code lists/enumerations as default values to these elements that covers
all countries is not a trivial exercise and therefore, this exercise was not
conducted by CIQ TC. Instead, these elements are customisable using code
lists/enumerations by end users to preserve the address semantics of each
country which assists in improving the semantic quality of the address. To
enable end users to preserve the meaning of the address semantics, the
specification provides the ability to customise the schema using code
lists/enumerations without changing the structure of the schema itself.
For example,
“State” defined in the code list/enumeration list for Administrative Area type
could be valid for countries like India, Malaysia and Australia, but not for Singapore as it does not have the concept of “State”. A value “Nagar” in the
code list/enumeration list for Sub Locality type could be only valid for
countries like India and Pakistan.
If there is no
intent to use the code list/enumeration list for the above schema elements, the
code list/enumeration list can be ignored. There is requirement that the
default values for the enumeration lists provided by the specification must
exist. The list can be empty also. As long as the code list/enumeration list
values are agreed between the parties involved in data exchange (whether data
exchange between internal business system or with external systems),
interoperability is not an issue.
In Option 1 of
representing code lists, the values clarifying the meaning of geographical
entity types (e.g. AdministrativeAreaType, LocalityAreaType) in xAL.xsd
were intentionally taken out of the main schema file into an “include” file (xAL-types.xsd)
to make customisation easier. In Option 2 of Code List representation, these
code lists are represented as separate .gc file in genericode format.
The values of the code lists/enumerations can be changed or new ones
added as required.
NOTE: The
code list/enumeration values for different code/enumeration lists that are
provided as part of the specifications are not complete. They only provide
sample values (and in most case no values) and it is up to the end users to
customise them to meet their data exchange requirements if the default values
are incomplete, not appropriate or over kill
In the example below, we use the country, Singapore. The default values provided by xAL.xsd for AdministrativeAreaType
enumeration are given below. The user might want to restrict the values to
meet only the address requirements for Singapore. Singapore does not have any
administrative areas as it does not have state, city, or districts or
provinces. So, the user can customise the schema by making the AdministrativeAreaType
enumeration as an empty list as shown in the table below.
|
Original
values for “AdministrativeAreaType” Code List
|
Customised Values
|
|
City
|
|
|
State
|
|
|
Territory
|
|
|
Province
|
|
This level of flexibility allows
some customisation of the schema through changing the enumerations only,
without changing the basic structure of the schema. It is important to ensure
that all schema users involved in data exchange use the same enumerations for
interoperability to be successful. This has to be negotiated between the data
exchange parties and a proper governance process SHOULD be in place to manage
this process.
Any changes to
the Address Entity schema (xAL.xsd) are likely to break the
compatibility one way or another.
It MAY be
possible that an XML fragment created for the original schema is invalid for
the altered schema or vice versa. This issue needs to be considered before
making any changes to the schema that could break the compatibility.
4.12.2 Using CVA to customise CIQ Address
Schema to meet application specific requirements
The other approach to customise
the CIQ address schema (xAL.xsd) without modifying it is by CVA. In this approach, one can use
Schematron patterns to define assertion rules to customise CIQ address schema
without modifying it. For example, it is possible to customise CIQ address
schema to restrict the use of address entitties that are not required for a
specific country. For example, a country like Singapore will not need address
entities namely, Administrative Area, Sub Administrative Area, Sub
Locality, Rural Delivery and Post Office. These entities can be
restricted using Schematron based assertion rules. Some might want to just use
free text address lines and a few of the address entities like locality and
postcode. Schematron assertion rules help users to achieve this.
NOTE: The
business rules used to constraint CIQ address schema SHOULD be agreed by all
the parties that are involved in data exchange of CIQ based address data to
ensure interoperability and the rules SHOULD be governed.
Let us use the country “Singapore” as an example again.
Let us say that the country “Singapore” only requires the following address
entities defined in xAL.xsd and does not require the rest of the entities
as they are not applicable to the country:
·
Country
·
Locality
·
Thoroughfare
·
PostCode
This restriction can be achieved without modifying the xAL.xsd
schema and by applying the following schematron pattern rules outside of xAL.xsd
schema as follows:
<rule context=”a:Address/*”>
<assert test=”(name()=’a:Country’) or (name()=’a:PostCode’)
or
(name()=’a.Thoroughfare’) or (name()=’a:Locality’)”
>Invalid data element present in the document
</assert>
</rule>
The above simple rule restricts the use of other elements
and attributes in xAL.xsd when an XML instance document is produced and
validated.
Now let us take the following XML instance document:
<a:Address>
<a:Country>
<a:NameElement>Singapore</a:NameElement>
</a:Country>
<a:AdministrativeArea>
<a:NameElement></a:NameElement>
</a:AdministrativeArea>
<a:Locality>
<a:NameElement>NUS
Campus</a:NameElement>
</a:Locality>
<a:Thoroughfare>
<a:NameElement>23 Woodside Road</a:NameElement>
</a:Thoroughfare>
<a:Premises>
<a:NameElement></a:NameElement>
</a:Premises>
<a:PostCode>
<a:Identifier>51120</a:Identifier>
</a:PostCode>
</a:Address>
When the above document instance is validated using CVA, pass one validation
(structure validation against xAL.xsd) will be successful. Pass two
validation (business rules and value validation) will report the following
errors:
Invalid
data element present in the document
:/a:Address/a:AdministrativeArea
Invalid
data element present in the document
:/a:Address/a:Premises
Let us consider another example where an application
requires using only the free text address lines in xAL.xsd and no other
address entities.
This restriction can be achieved without modifying the xAL.xsd
schema and by applying the following schematron pattern rules outside of the
schema as follows:
<rule context=”a:Address/*”>
<assert test=”name()=’a:FreeTextAddress’”
>Invalid data element present in the document
</assert>
</rule>
The above simple rule restricts the use of elements and
attributes other than “FreeTextAddress” element in xAL.xsd when
an XML instance document is produced and validated.
xNAL (Name and Address) schema is a container for
combining related names and addresses. This specification recognises two ways
of achieving this and they are:
·
Binding multiple names to multiple addresses
(element xnal:Record)
·
Binding multiple names to a single address for
postal purposes (element xnal:PostalLabel)
Element xnal:Record
is a binding container that shows that some names relate to some addresses
as in the following diagram:
The relationship
type is application specific, but in general it is assumed that a person
defined in the xNL part have some connection/link with an address specified
in the xAL part. Use attributes from other namespace to specify the type
of relationships and roles of names and addresses.
Mr H G Guy, 9 Uxbridge Street, Redwood, Christchurch 8005
<xnal:Record>
<n:PartyName>
<n:NameLine>Mr H G Guy</n:NameLine>
</n:PartyName>
<a:Address>
<a:Locality>
<a:Name>Christchurch</a:Name>
<a:SubLocality>Redwood</a:SubLocality>
</a:Locality>
<a:Thoroughfare>
<a:Number>9</a:Number>
<a:NameElement>Uxbridge Street</a:NameElement>
</a:Thoroughfare>
<a:PostCode>
<a:Identifier>8005</a:Identifier>
</a:PostCode>
</a:Address>
</xnal:Record>
Element xnal:PostalLabel
is a binding container that provides elements and attributes for
information often used for postal / delivery purposes, as in the following
diagram. This has two main containers, an addressee and the address:
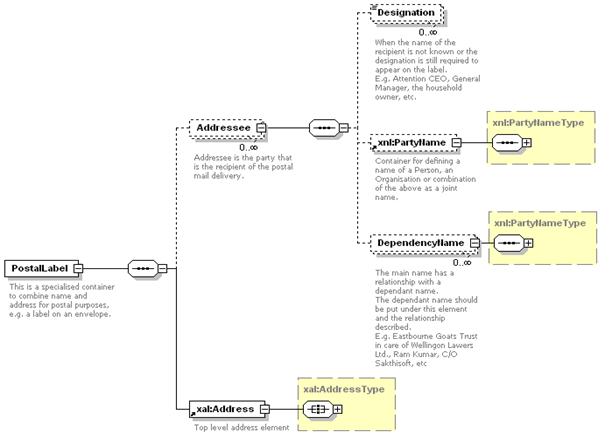
This structure
allows for any number of recipients to be linked to a single address with some
delivery specific elements such as Designation and DependencyName.
Attention: Mr S Mart
Director
Name Plate Engravers
The Emporium
855 Atawhai Drive
Atawhai
Nelson 7001
translates into the following xNAL fragment:
<xnal:PostalLabel>
<xnal:Addressee>
<xnal:Designation>Attention: Mr S Mart</xnal:Designation>
<xnal:Designation>Director</xnal:Designation>
<n:PartyName>
<n:NameLine>Name Plate Engravers</n:NameLine>
</n:PartyName>
</xnal:Addressee>
<a:Address>
<a:Locality>
<a:Name>Nelson</a:Name>
<a:SubLocality>Atawhai</a:SubLocality>
</a:Locality>
<a:Thoroughfare>
<a:NameElement>Atawhai Drive</a:NameElement>
<a:Number>855</a:Number>
</a:Thoroughfare>
<a:PostCode>
<a:Identifier>7001</a:Identifier>
</a:PostCode>
</a:Address>
</xnal:PostalLabel>
Users can use the xNL and xAL
constructs and create their own name and address container schema to meet their
specific requirements rather than using a container element called “Record” as
in xNAL if they believe that xNAL schema does not meet their
requirements. This is where the power of CIQ Specifications comes in to play.
It provides the basic party constructs to enable users to reuse the base
constructs of CIQ specifications as part of their application specific data
model and at the same time meeting their application specific requirements.
For example, users can create a
schema called Customers.xsd that could reuse xNL and xAL
to represent their customers. This is shown in the following figure:
In the above figure, PersonName is OPTIONAL.
In the above figure, “Customer”
is of type “Party” as defined in xNL schema. “Customer” is then extended
to include “Address” element that is of type “Address” as defined in xAL
schema.
Entity “Party”
encapsulates some most commonly used unique characteristics/attributes of Person
or Organisation, such as name, address, personal details, contact
details, physical features, etc.
This assists in uniquely
identifying a party with these unique party attributes.
The schema consists
of top level containers that MAY appear in any order or MAY be omitted. The
containers are declared globally and can be reused by other schemas. The full
schema for defining a Party can be found in xPIL,xsd file with
enumerations in xPIL-types.xsd file for Code List Option 1 and .gc files
for Code List Option 2. See the sample XML files for examples.
xPIL provides a number of elements/attributes that are common to both a
person and an organisation (e.g. account, electronic address identifier, name,
address, contact numbers, membership, vehicle, etc).
xPIL provides a number of elements/attributes that are applicable to a
person only (e.g. gender, marital status, age, ethnicity, physical information,
hobbies, etc)
xPIL provides a number of elements/attributes that are applicable to an
organisation only (e.g. industry type, registration details, number of
employees, etc)
“Name” of xPIL
schema reuses PartyNameType constructs from xNL namespace and “Address”
of the xPIL schema reuses AddressType construct from xAL namespace
as illustrated in the following diagram:
The design
paradigm for this xPIL schema is similar to those of Name and Address
entities. Likewise, it is possible to combine information at different detail
and semantic levels.
The following examples
illustrate use of a selection of party constructs.
<p:Qualifications>
<p:Qualification>
<p:QualificationElement p:Type="QualificationName">BComp.Sc.</p:QualificationElement>
<p:QualificationElement p:Type="MajorSubject">Mathematics</p:QualificationElement>
<p:QualificationElement p:Type="MinorSubject">Statistics</p:QualificationElement>
<p:QualificationElement p:Type="Award">Honours</p:QualificationElement>
<p:InstitutionName>
<n:NameLine>University of Technology Sydney</n:NameLine>
</p:InstitutionName>
</p:Qualification>
</p:Qualifications>
<p:BirthInfo p:BirthDateTime="1977-01-22T00:00:00"/>
<p:Document p:ValidTo="2004-04-22T00:00:00">
<p:IssuePlace>
<a:Country>
<a:Name>Australia</a:Name>
</a:Country>
<a:AdministrativeArea>
<a:Name>NSW</a:Name>
</a:AdministrativeArea>
</p:IssuePlace>
<p:DocumentElement p:Type="DocumentID">74183768C</p:DocumentElement>
<p:DocumentElement p:Type="DocumentType">Driver
License</p:DocumentElement>
<p:DocumentElement
p:Type="Priviledge">Silver</p:DocumentElement>
<p:DocumentElement p:Type="Restriction">Car</p:DocumentElement>
</p:Document>
<p:ContactNumber p:MediaType="Telephone" p:ContactNature="Business
Line" p:ContactHours="9:00AM - 5:00PM">
<p:ContactNumberElement p:Type="CountryCode">61</p:ContactNumberElement>
<p:ContactNumberElement p:Type="AreaCode">2</p:ContactNumberElement>
<p:ContactNumberElement p:Type="LocalNumber">94338765</p:ContactNumberElement>
</p:ContactNumber>
<p:ElectronicAddressIdentifiers>
<p:ElectronicAddressIdentifier p:Type="SKYPE"
p:Usage="Personal">rkumar
</p:ElectronicAddressIdentifiers>
<p:ElectronicAddressIdentifier p:Type="EMAIL"
p:Usage="Business">ram.kumar@email.com
</p:ElectronicAddressIdentifiers>
<p:ElectronicAddressIdentifier p:Type="URL" p:Usage="Personal">http://www.ramkumar.com
</p:ElectronicAddressIdentifiers>
xPIL schema represents details of a Party. The Party has a
name as specified in n:PartyName element. A “Party” can be a unique name
(e.g. A person or an Organisation) or a joint name (e.g. Mrs. Sarah Johnson and
Mr. James Johnson (or) Mrs. & Mr. Johnson). In this case, all the other
details of the party defined using xPIL apply to the party as a whole
(i.e. to both the persons in the above example) and not to one of the Parties
(e.g. say only to Mrs. Sarah Johnson or Mr. James Johnson in the example).
Also, all the addresses specified in Addresses element relate to the Party
as a whole (i.e. applies to both Mrs. and Mr. Johnson in this example).
If for example,
Mrs. Sarah Johnson and Mr. James Johnson have to be defined separately with
their own unique characteristics (e.g. address, vehicle, etc), then each person
SHOULD be defined as an individual party.
xPIL provides the ability to also define simple one to one relationships
between a party (person or an organisation) and other parties (person or
organisation). This is shown in the following diagram (an extract of XML
schema).
However, it is
strongly advised that users interested in implementing relationships between
parties using CIQ specifications SHOULD use CIQ xPRL (extensible Party
Relationships Language) specification version 3.0 exclusively defined for dealing
with party relationships.
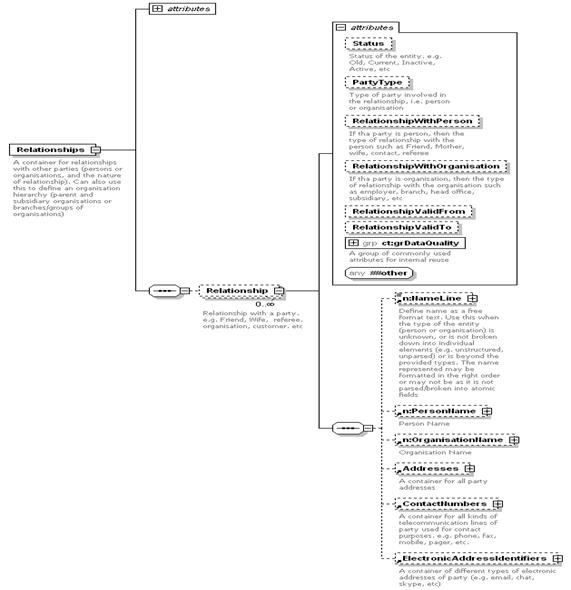
Examples of
relationships include, Friend, Spouse, Referee, Contact, etc for a person, and
Client, customer, branch, head office, etc for an organisation.
Details of each
party involved in the relationship can be defined namely, Person Name,
Organisation Name, Contact Numbers and Electronic Address Identifiers.
The “Relationship”
element provides the relationship details between the parties. It’s attribute Status
defines the status of relationship; attribute RelationshipWithPerson defines
the type of relationship with the person (e.g. friend, spouse) if the party is
a person; attribute RelationshipWithOrganisation defines the type of
relationship with the organisation (e.g. client, branch, subsidiary) if the
party is an organisation; attributes RelationshipValidFrom and RelationshipValidTo
defines the dates of the relationship with the party.
<p:Relationships>
<p:Relationship p:RelationshipWithPersonGroup=”Friend”>
<p:PartyDetails>
<p:PersonName>
<p:NameElement=”FullName”>Andy Chen</NameElement>
</p:PersonName>
</p:PartyDetails>
</p:Relationship>
<p:Relationship p:RelationshipWithPersonGroup=”Friend”>
<p:PartyDetails>
<p:PersonName>
<p:NameElement=”FullName”>John
Freedman</NameElement>
</p:PersonName>
</p:PartyDetails>
</p:Relationship>
<p:Relationship p:RelationshipWithPersonGroup=”Friend”>
<p:PartyDetails>
<p:PersonName>
<p:NameElement=”FullName”>Peter
Jackson</NameElement>
</p:PersonName>
</p:PartyDetails>
</p:GroupRelationship>
</p:Relationships>
<p:Relationships>
<p:Relationship p:PartyType=”Organisation” p:RelationshipWithOrganisation=”Branch”>
<p:NameLine>XYZ Pty. Ltd</p:NameLine>
<p:Address>
<p:FreeTextAddress>
<p:AddressLine>23 Archer Street, Chastwood, NSW 2067,
Australia
</p:AddressLine>
</p:FreeTextAddress>
</p:Address>
</p:Relationship>
<p:Relationship p:PartyType=”Organisation”
p:RelationshipWithOrganisation=”Branch”>
<p:NameLine>XYZ Pte. Ltd</p:NameLine>
<p:Address>
<p:FreeTextAddress>
<p:AddressLine>15, Meena Rd, K.K.Nagar, Chennai
600078
India
</p:AddressLine>
</p:FreeTextAddress>
</p:Address>
</p:Relationshiop>
</p:Relationships>
<p:Relationships>
<p: Relationship p:RelationsipWithPersonGroup=”Son”>
<p:PersonName>
<p:NameElement=”FullName”>Andy
Chen</NameElement>
</p:PersonName>
</p:Relationship>
</p:Relationships>
All elements and
attributes in xPIL schema have strong data types.
All free-text
values of elements (text nodes) and attributes are constrained by a simple type
“NormalizedString” (collapsed white spaces) defined in CommonTypes.xsd.
Other XML Schema data types are also used throughout the schema.
Other XML Schema
defined data types are also used throughout the schema.
Use of code
lists/enumerations is identical to use of code lists for entity “Name”.
Refer to section 3.3 for more
information.
Code
lists/enumerations used in xPIL for code list option 1 reside in an
“include” xPIL-types.xsd. Code lists/enumerations used in xPIL
for code list option 2 reside as .gc genericode files.
NOTE: The code
list/enumeration values for different code lists/enumeration lists that are
provided as part of the specifications are not complete. They only provides
some sample values (and in most cases no values) and it is up to the end users
to customise them to meet their data exchange requirements if the default
values are incomplete, not appropriate or over kill
Order of
elements without qualifier (@...type attribute) MUST be preserved for correct
presentation as described in section 3.6.
Mapping data
between xPIL schema and a database is similar to that of entity “Name”
as described in section 3.7.
xPIL schema allows for data quality information to be provided as part
of the entity using attribute DataQuality as for entity “Name”.
Refer to section 3.8 for more
information.
All elements in Party namespaces are
extensible as described in section 3.10.
All linking and
referencing rules described in section 3.9 apply to entity “Party”.
The following
example illustrates PartyName elements that reference other PartyName
element that resides elsewhere, in this case outside of the document.
<a:Contacts
xmlns:a="urn:acme.org:corporate:contacts">
<xnl:PartyName xlink:href="http://example.org/party?id=123445"/>
<xnl:PartyName
xlink:href="http://example.org/party?id=83453485"/>
</a:Contacts>
This example
presumes that the recipient of this XML fragment has access to resource “http://example.org/party”
(possibly over HTTP/GET) and that the resource returns as PartyName
element as an XML fragment of text/xml MIME type.
Use of attribute
ID is described in section 3.11.
Schema conformance described in section 3.12 is fully applicable to entity “Party”.
Schema
customisation rules and concepts described in section 3.13 are fully applicable to entity “Party”.
If there is no
intent to use the code list/enumeration list for the xPIL schema
elements, the code list/enumeration list can be ignored. There is no absolute
must rule that the default values for the enumeration lists provided by the
specification must exist. The list can be empty also. As long as the code
list/enumeration list values are agreed between the parties involved in data
exchange (whether data exchange between internal business system or with
external systems), interoperability is not an issue.
In Option 1 of
representing code lists, the values clarifying the meaning of party element
types (e.g. DocumentType,ElectronicAddressIdentifierType ) in xPIL.xsd
were intentionally taken out of the main schema file into an “include” file (xPIL-types.xsd)
to make customisation easier. In Option 2 of Code List representation, these
code lists are represented as separate .gc file in genericode format.
The values of
the code lists/enumerations can be changed or new ones added as required.
NOTE: The
code list/enumeration values for different code/enumeration lists that are
provided as part of the specifications are not complete. They only provide
sample values (and in most case no values) and it is up to the end users to
customise them to meet their data exchange requirements if the default values
are incomplete, not appropriate or over kill
In the example below, we use Identifier element of xPIL.xsd.
The default values provided by CIQ Specification for Identifier type’s
enumeration are given below. The user might want to restrict these values. So,
the user can customise the code list for Identifier types by making the PartyIdentifierTypeEnumeration
with the required values as shown in the table below.
|
Default values for “PartyIdentifierTypeList”
Code List
|
Customised
values
|
|
TaxID
|
TaxID
|
|
CompanyID
|
|
|
NationalID
|
|
|
RegistrationID
|
|
This level of flexibility allows
some customisation of the schema through changing the code list/enumerations only,
without changing the basic structure of the schema. It is important to ensure
that all schema users involved in data exchange use the same cod list/enumerations
for interoperability to be successful. This has to be negotiated between the
data exchange parties and a proper governance process SHOULD be in place to
manage this process.
Any changes to
the Party Entity schema (xPIL.xsd) are likely to break the compatibility
one way or another.
It MAY be
possible that an XML fragment created for the original schema is invalid for
the altered schema or vice versa. This issue needs to be considered before
making any changes to the schema that could break the compatibility.
6.13.2 Using CVA to customise Party Schema to
meet application specific requirements
The other approach to customise
the CIQ party schema (xPIL.xsd) without touching it is by using CVA. In this approach, one can use
Schematron patterns to define assertion rules to customise party schema without
touching or modifying it. For example, it is possible to customise party schema
to restrict the use of party entities (elements and attributes) that are not
required for a specific application. These entities can be restricted using Schematron
based assertion rules.
NOTE: The
business rules used to constraint CIQ party schema SHOULD be agreed by all the
parties that are involved in data exchange of CIQ based party data to ensure
interoperability and the rules SHOULD be governed.
CIQ Specifications comes with two types of
entity schemas (xNL.xsd, xAL.xsd, xPIL.xsd, and xNAL.xsd) based
on the type of code lists/enumerations used. The types of code
lists/enumerations options used are:
Option1 (Default): All code lists for an entity represented using XML schema (in one
file) and “included” in the appropriate entity schema (xNL-types.xsd,
xAL-types.xsd, xNAL-types.xsd, and xPIL-types.xsd).
Option 2: Code
Lists represented using Genericode structure of OASIS Codelist TC. Each
enumeration list in option 1 is a separate “.gc” file in this option.
Following are the XML schema files provided
as default in CIQ Specifications package for Option 1:
·
xNL.xsd
·
xNL-types.xsd (13 Default Code Lists
defined for xNL)
·
xAL.xsd
·
xAL-types.xsd (32 Default Code Lists
defined for xAL)
·
xPIL.xsd
·
xPIL-types.xsd (60 Default Code Lists
defined for xPIL)
·
xNAL.xsd
·
xNAL-types.xsd (2 Default Code List
defined for xNAL)
·
CommonTypes.xsd (2 Default Code Lists
defined for Common Type for all entities)
·
xlink-2003-12-21.xsd
The relationship between the different XML
Schemas for Option 1 is shown in the following diagram:
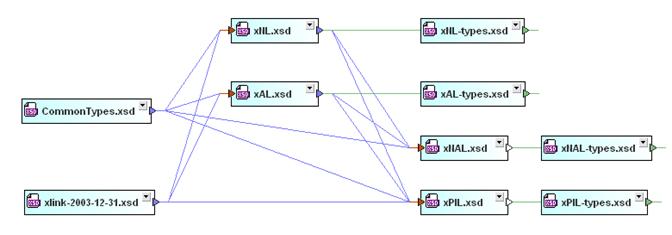
Following are the files provided as default
in CIQ Specifications package for Option 2:
·
xNL.xsd
·
xAL.xsd
·
xPIL.xsd
·
xNAL.xsd
·
CommonTypes.xsd
·
xlink-2003-12-21.xsd
No *-types.xsd files exist in Option
2 as all the code lists are defined as genericode files.
The relationship between the different
schemas for Option 2 is shown in the following figure. As you can see, the
enumeration list XML schemas do not exist. Instead, each CIQ entity (Name,
Address, and Party) has a set of genericode based Code List files (.gc).
12 default genericode based code list files
with .gc extension. Each enumeration list in Option 1 is defined as a separate
file in Option 2.
32 default genericode based code list files
with .gc extension. Each enumeration list in Option 1 is defined as a separate
file in Option 2.
2 default genericode based code list files
with .gc extension. The enumeration list in Option 1 is defined as a separate
file in Option 2.
54 default genericode based code list files
with .gc extension. Each enumeration list in Option 1 is defined as a separate
file in Option 2.
2 default genericode based code list files
with .gc extension.
Both the types of entity schemas (for
option 1 and option 2) use the same namespaces to ensure that the XML instance
documents generated from any of these two options are compatible with both
types of CIQ entity XML schemas.
The key
difference between the two types of CIQ entity schemas (Option 1 and Option 2) are
the additional metadata information for information item values in XML
instances for Option 2. This metadata information is defined as OPTIONAL
attributes. It is not mandatory to have instance level metadata, but having it
allows an instance to disambiguate a code value that might be the same value
from two different lists. An application interpreting a given information item
that has different values from different lists MAY need the user to specify
some or the entire list metadata from which the value is found, especially if
the value is ambiguous.
Four types
metadata attributes are used in Option 2 entity schema attributes that
reference code lists and they are:
·
Ref – corresponds
to genericode <ShortName> reference
·
Ver – corresponds
to genericode <Version> version of the file
·
URI – corresponds
to genericode <CanonicalUri> abstract identifier for all versions of the
code list
·
VerURI – corresponds to genericode <CanonicalVersionUri>
abstract identifier for this version of the code list
For detailed explanation of
metadata information, read CVA
document (http://www.oasis-open.org/committees/document.php?document_id=21324)
The figure below
shows “PersonName” element in Option 1 (using xNL-types.xsd for all Name
entity associated code lists) of xNL.xsd:
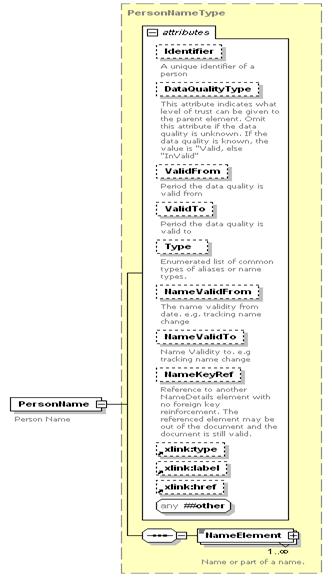
The figure below shows PersonName
element in Option 2 (using genericode for Name entity associated code lists) of
xNL.xsd with metadata information for genericode based code lists:
Metadata Information for “Type” attribute that refers to
genericode “PersonNameEnumeration.gc” file
|
|


Metadata Information for “DataQualityType” attribute
that refers to genericode “DataQualityEnumeration.gc” file
|
|
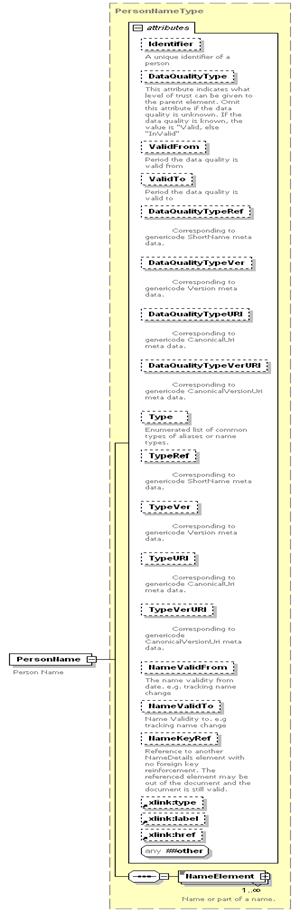
XML document instances that
conform to CIQ XML schemas of Option 1 SHOULD validate against the CIQ XML
schemas of Option 2 without any changes to the XML document. This MAY not true
vice versa as Option 2 CIQ XML schemas provide “metadata attributes” to support
genericode and these attributes MAY be defined in the XML document instance. If
these attributes are not defined in the XML document instance, then validation
of the XML document instance against the CIQ XML Schemas of Option 1 SHOULD be
successful.
User MUST use Option 1 or Option
2, but MUST NOT use both at the same time. The choice of the Option to use is
entirely dependent on user specific requirements.
OASIS CIQ TC
defines data/information interoperability as follows:
“Getting the right
data to the right place at the right time in the right
format and in the right context”
It is the view
of the CIQ committee that to enable interoperability of data/information
between parties, the best solution is to parse the data elements into its
atomic elements thereby preserving the semantics and quality of data. By this
way the parties involved in data exchange will be in the best position to
understand the semantics and quality of data thereby minimising interoperability
issues. How the data will be exchanged between parties, whether in parsed or
unparsed structure, must be negotiated between the parties to enable
interoperability.
One cannot
expect interoperability to occur automatically without some sort of negotiation
between parties (e.g. Information Exchange Agreement, whether internal or
external to an organisation) involved in data exchange. Once information
exchange agreements between parties are in place, then the data/information
exchange process can be automated. Moreover, the entire information exchange
and interoperability process SHOULD be managed through an effective governance
process which SHOULD involve all the parties involved in the information
exchange process. This enables effective and efficient management of any change
to the information exchange process in the future.
We at OASIS CIQ TC strongly believe in the
following “Data Interoperability Success Formula”:
Data Interoperability = Open Data Architecture + Data Integration
+ Data Quality + Data Standards + Data Semantics + Data Governance
All components on the right hand
side of the above formula are important for successful data interoperability.
The term “Open” used here indicates artifacts that are independent of any
proprietary solution (e.g. open industry artifacts or artifacts that are open
within an enterprise).
To ensure interoperability of CIQ represented
data/information between applications/business systems (whether internal to the
organisation or external to the organisation) it is strongly advised that an
information exchange agreement/specification for CIQ SHOULD is in place. This
agreement/specification SHOULD outline in detail the customisation of CIQ specifications.
Following are the features of CIQ specifications that
assist in customisation of the specifications to meet specific application or
data exchange requirements, and the details of customisation SHOULD be
documented and agreed (if involving more than one party in data exchange) at
application/system design time to enable automating interoperability of
information/data represented using CIQ specifications at application/system run
time:
·
List of all elements of CIQ XML Schemas that SHOULD be used in
the exchange. This includes details of which elements are mandatory and which
elements are OPTIONAL
·
List of all attributes of CIQ XML Schemas that SHOULD be used in
the exchange. This includes details of which attributes are mandatory and which
attributes are OPTIONAL
·
The approach that will be used for Code Lists (Option 1 or Option
2)
·
The code list values that SHOULD be used for each CIQ code lists.
This includes updating the default XML Schemas for code lists (Option 1) with
the values to be used and updating the default genericode based code lists
(Option 2) with the values to be used. These code list files SHOULD then be
implemented by all applications/systems involved in data exchange. If
genericode based code list approach (Option 2) is used, then the XSLTs for
value validation SHOULD be generated and implemented by all
applications/systems involved in data exchange.
·
Whether xLink or Key Reference SHOULD be used to reference party,
name or address, and the details
·
Whether XML schema SHOULD be extended by using new
attributes from a non-target namespace and if so, details of the additional
attributes
·
Whether business rules SHOULD be defined to constrain the CIQ XML
schemas and if so, details of the business rules that SHOULD be implemented
consistently by all applications/systems involved in data exchange
Once the agreement is implemented, it is vital that the agreement SHOULD be
governed through a governance process to manage change effectively and
efficiently. All parties involved in the data exchange process SHOULD be key
stakeholders of the governance process.
The keywords "MUST", "MUST NOT", "SHOULD",
"SHOULD NOT", “MAY” and "OPTIONAL" interpreted as described
in [RFC2119] are used as the conformance clauses throughout this document.
Implementation
of CIQ Specifications namely the XML Schemas (xNL.xsd, xAL.xsd, xNAL.xsd,
and xPIL.xsd) MUST conform to the specifications if the implementation
conforms to as stated in section 3.12.
Implementation
of CIQ Specifications namely the XML Schemas (xNL.xsd, xAL.xsd, xNAL.xsd,
and xPIL.xsd) by extending them MUST conform as stated in section 3.9.
Customisation of
the Code List XML Schemas (xNL-types.xsd, xAL-types.xsd, xNAL-types.xsd,
and xPIL-types.xsd) using Option 1 MUST be well formed. Changes to the
default values provided as part of the specifications is OPTIONAL and MAY be
modified by the user.
Implementation
of CIQ Specifications between two or more applications/systems or parties helps
achieve interoperability if the implementation conforms to using the agreed
conformance clauses as defined in sections 9.1.3.1, 9.1.3.2, 9.1.3.3, 9.1.3.4, 9.1.3.5, and 9.1.3.6.
Implementation
of elements and attributes of CIQ XML Schema enables interoperability if the
following conditions are agreed by two or more parties involved in data
exchange and are met:
1.
The OPTIONAL elements in the XML Schema that
SHOULD be used for implementation and the OPTIONAL elements in the XML Schema
that SHOULD be ignored. See section 8.2.
2.
The OPTIONAL attributes in the XML Schema that
SHOULD be used for implementation and the OPTIONAL attributes in the XML Schema
that SHOULD be ignored. See section 8.2 .
Implementation
of the CIQ schema by extending it SHOULD be agreed and managed between two or
more parties involved in the data exchange and MUST be conformed to in order to
achieve interoperability as stated in section 3.9.
Implementation
of a Code List approach SHOULD be agreed and conformance to the selected
approach between two or more parties involved in the data exchange MUST be
achieved in order to ensure interoperability and this is stated in section 3.4.
Implementation
of the Code List values SHOULD be agreed between two or more parties involved
in the data exchange and MUST be conformed to as agreed in order to ensure
interoperability as stated in section 3.4.
Customisation of the schema SHOULD be
achieved by the following ways:
1.
Using Code List values
2.
Defining new business rules to constraint the
schema
Implementation
of the above approaches SHOULD be agreed between two or more parties involved
in the data exchange and MUST be conformed to in order to achieve
interoperability as stated in section 3.13.
Implementation
and conformance of the implementation to the agreed Data/Information Exchange
Agreement between two or more parties involved in the data exchange MUST be
achieved to ensure interoperability as stated in section 8.2.
Although, all
schema files are fully documented using XML Schema annotations it is not always
convenient to browse the schema itself. This specification is accompanied by a
set of HTML files auto generated by XML Spy. Note that not all information
captured in the schema annotation tags is in the HTML documentation.
Several examples
of instance XML documents for name, address and party schemas are provided as
XML files. The examples are informative and demonstrate the application of this
Technical Specification.
The example
files and their content are being constantly improved and updated on no
particular schedule.
OASIS CIQ TC is
open in the way it conducts its business. We welcome contributions from public in
any form. Please, use “Send A Comment” feature on CIQ TC home page (http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=ciq)
to tell us about:
·
errors, omissions, misspellings in this
specification, schemas or examples
·
your opinion in the form of criticisms,
suggestions, comments, etc
·
willingness to contribute to the work of CIQ TC
by becoming a member of the TC
·
willingness to contribute indirectly to the work
of CIQ TC
·
provision of sample data that can be used to
test the specifications
·
implementation experience
·
etc.
The major change to this specification from
its earlier release in November 2007 is fix to xAL V3.0 schema. Details about
the issue and changes to the xAL schema are explained in the following document
that is provided as part of this release package:
Document Name: “CIQ Specification V3.0 – Address
Schema (xAL.xsd) Changes”, 19 March 2008
File Name: ciq-xal-errata (file ypes: html,
pdf or doc)
The following individuals have
participated in the creation of version 3.0 of CIQ specifications and are
gratefully acknowledged:
Participants:
|
George Farkas
|
XBI Software, Inc
|
Member, CIQ TC
|
|
John Glaubitz
|
Vertex, Inc
|
Voting Member, CIQ TC
|
|
Hidajet Hasimbegovic
|
Individual
|
Voting Member, CIQ TC
|
|
Robert James
|
Individual
|
Former Member, CIQ TC
|
|
Ram Kumar
|
Individual
|
Chair and Voting Member, CIQ TC
|
|
Graham Lobsey
|
Individual
|
Voting Member, CIQ TC
|
|
Joe Lubenow
|
Individual
|
Voting Member, CIQ TC
|
|
Mark Meadows
|
Microsoft Corporation
|
Former Member, CIQ TC
|
|
John Putman
|
Individual
|
Former Member, CIQ TC
|
|
Michael Roytman
|
Vertex, Inc
|
Voting Member, CIQ TC
|
|
Colin Wallis
|
New Zealand
Government
|
Voting Member, CIQ TC
|
|
David Webber
|
Individual
|
Voting Member, CIQ TC
|
|
Fulton Wilcox
|
Colts
Neck Solutions LLC
|
Member, CIQ TC
|
|
Max Voskob
|
Individual
|
Former Member, CIQ TC
|
OASIS CIQ Technical Committee
(TC) sincerely thanks the public (this includes other standard groups, organisations
and end users) for their continuous feedback and support that helps the TC to work
toward improving the CIQ specifications.
Special thanks to Mr.Ken Holman,
Chair of OASIS Code List TC (http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=codelist)
for his support, guidance and genericode implementation assistance to the TC in
releasing the OASIS Code List version of CIQ V3.0 XML Schemas.
Special thanks to Mr.Hugh Wallis,
Director of Standards Development of extensible Business Reporting Language
(xBRL) International Standards Group (http://www.xbrl.org)
for working closely with the CIQ TC in jointly implementing W3C xLink
specification that is now used by both xBRL and CIQ Specifications to enable
interoperability between the two specifications.
Special thanks to Mr.Carl Reed,
Chief Technology Officer of Open Geospatial Consortium (OGC – http://www.opengeospatial.org) for
his guidance and assistance to the TC in referencing the work of OGC on GeoRSS
and Geo-Coordinates for addresses/locations as part of CIQ Address Specifications.
OASIS CIQ TC also acknowledges
the contributions from other former members of the TC since its inception in
2000.
CIQ TC
Specifications (includes documents, schemas and examples1 and 2) are free of any Intellectual
Property Rights, Patents, Licenses or Royalties. Public is free to download and
implement the specifications free of charge.
1xAL-AustralianAddresses.xml
Address examples come from AS/NZ
4819:2003 standard of Standards Australia and are subject to copyright
2xAL-InternationalAddresses.xml
Address examples come from a variety of
sources including Universal Postal Union (UPU) website and the UPU address
examples are subject to copyright.
xLink-2003-12-31.xsd
This schema
was provided by the xBRL group in December 2006.
|
Revision
|
Date
|
Editor
|
Changes Made
|
|
V3.0 PRD 01
|
13 April 2006
|
Ram Kumar and Max Voskob
|
Prepared 60 days public review draft from Committee Draft
01
|
|
V3.0 PRD 02
|
15 June 2007
|
Ram Kumar
|
Prepared second round of 60
days public review draft from Committee Draft 02 by including all public
review comments from PRD 01. Also included is implementation of OASIS Code
list specification
|
|
V3.0 PRD 02 R1
|
18 September 2007
|
Ram Kumar
|
Inclusion of comments from
Public Review 02
|
|
V3.0 CS
|
15 November
2007
|
Ram Kumar
|
TC Approved Committee
Specification
|
|
V3.0 CD 02
|
18 March 2008
|
Ram Kumar
|
Inclusion of the xAL Schema
Errata
|
|
V3.0 PRD 03
|
08 April 2008
|
Ram Kumar
|
Public Review Draft for 15 days
review
|

