This Committee Specification is being developed under the RF
on Limited Terms Mode of the OASIS IPR Policy,
the mode chosen when the Technical Committee was established.
For information on whether any patents have been disclosed
that may be essential to implementing this specification, and any offers of
patent licensing terms, please refer to the Intellectual Property Rights
section of the TC’s web page (https://www.oasis-open.org/committees/legaldocml/ipr.php).
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”,
“SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in
this document are to be interpreted as described in [RFC2119].
1.2 Normative
References
[RFC2119] Bradner, S.,
“Key words for use in RFCs to Indicate Requirement Levels”, BCP 14, RFC 2119, March
1997. http://www.ietf.org/rfc/rfc2119.txt.
[IRI] International
Resource Identifiers as per RFC 3987 (http://tools.ietf.org/html/rfc3987).
[ISO3166-1:2013] Codes for the representation of names of countries and their
subdivisions -- Part 1: Country codes (https://www.iso.org/obp/ui/#search/code/).
[ISO639-2:1998] Codes for the representation of names of languages -- Part 2: Alpha-3
code http://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=4767
[XML-SCHEMA-0] XML Schema Part 0: Primer Second Edition , D. C. Fallside, P. Walmsley,
Editors, W3C Recommendation, 28 October 2004, http://www.w3.org/TR/2004/REC-xmlschema-0-20041028/ . Latest version available at http://www.w3.org/TR/xmlschema-0/
1.3 Non-Normative
References
[RDF] Resource
Description Framework (http://www.w3.org/RDF/).
[FRBR] Functional
requirements for bibliographic records: final report / IFLA Study Group on the
Functional Requirements for Bibliographic Records. — München: K.G. Saur, 1998.
— viii, 136 p. — (UBCIM publications; new series, vol. 19). — ISBN
978-3-598-11382-6. http://www.ifla.org/files/assets/cataloguing/frbr/frbr_2008.pdf.
[AkomaNtosoNaming-v1.0] Akoma Ntoso Naming Convention Version 1.0.
Edited by Véronique
Parisse, Monica Palmirani, Fabio Vitali. OASIS
Committee Specification Draft 01. http://docs.oasis-open.org/legaldocml/akn-nc/v1.0/csd01/akn-nc-v1.0-csd01.html.
Latest version: http://docs.oasis-open.org/legaldocml/akn-nc/v1.0/akn-nc-v1.0.html.
The present document provides a presentation of the main
motivations, design principles, and the benefits of using Akoma Ntoso vocabulary
and approach. The document is non-normative material and it is thought for
presenting the main pillars of Akoma Ntoso to the stakeholders who need to take
decisions about how to manage the legal sources in a digital manner in a
Semantic Web society.
2
Overview (Non-Normative)
The LegalDocumentXML Specifications provide a common legal
document standard for the specification of parliamentary, legislative, and
judicial documents, for their interchange between institutions anywhere in the
world, and for the creation of a common data and metadata model that allows
experience, expertise, and tools to be shared and extended by all participating
peers, courts, Parliaments, Assemblies, Congresses, and administrative branches
of governments. The standard aims to provide a format for long-term storage of
and access to parliamentary, legislative and judicial documents that allows
search, interpretation, and visualization of documents.
The LegalDocumentXML Specifications aims to achieve the
following objectives:
·
To create a common legal document standard for the interchange of
parliamentary, legislative and judicial documents between institutions anywhere
in the world.
·
To provide a format both for long-term storage and for access to
parliamentary, legislative, and judicial documents that allows search,
interpretation, and visualization of documents.
·
To create a common data and metadata model so that experience,
expertise, and tools can be shared and extended by the participating peers -
whether they be courts, Parliaments, Assemblies, Congresses or administrative
branches of governments.
·
To create or reuse common mechanisms for naming and linking
resources (URI) so that documents produced by Parliaments and Courts can be
easily cited and cross-referenced by other Parliaments, Courts or individual
users.
·
To be self-explanatory - that is, to be able to provide any
information for its use and meaning through a simple examination of the schema
and/or example documents, without the aid of specialized software.
·
To be extensible - that is, to allow modifications to the models
within the Akoma Ntoso framework so that local customisation can be achieved
without sacrificing interoperability with other systems.
The specifications of the standard are based on the
experience of the Akoma Ntoso vocabulary as formalised in XML-schema. For this
reason, the specification keeps the name "Akoma Ntoso" and the root
of the XML-schema will be "akomaNtoso".
LegalDocML/Akoma Ntoso (hereafter referred to simply as
Akoma Ntoso) is an open standard meant to make the structure and meaning of
legal documents “machine readable.” The machine-readable descriptions of a
document enable content managers to add meaning to the content and to describe
the structure of the knowledge about that content. In this way, a computer can
analyse information using processes similar to human deductive reasoning and
inference, but in a massively faster way so that smart advanced services (such
as point-in-time consolidation of legislation) can be achieved.
Making documents machine readable occurs via “markup.”
Markup is the act of adding machine-readable annotation and labels to all the
parts of a document in order to allow computer-based processing to be carried
out (from publication to print to storage to technical analysis, etc. ). In
Akoma Ntoso, these annotations and labels consist of XML tags.
The next section describes the three main features that characterise Akoma Ntoso:
·
Descriptiveness;
·
Rich data models;
·
Separation of data and metadata.
The Akoma Ntoso standard distinguishes between concepts
regarding the description and identification of legal documents, their content,
and the context in which they are used.
Names are used to associate the document representations to
concepts so that documents can be “read/understood” by a machine, thus allowing
sophisticated services that are impossible to attain with documents containing
only typographical information, such as documents created in word-processing
applications.
To make documents machine-readable, every part with a
relevant meaning and role must have a “name” (or “tag”) that machines can read.
The content is marked up as precisely as possible according to the legal
analysis of the text. This requires precisely identifying the boundaries of the
different text segments, providing an element name that best describes the text
in each situation, and also providing a correct identifier to each labelled
fragment.
Tag names, formally known as element names, are the basic
vocabulary of the Akoma Ntoso language. The element name may be shared by many
text fragments of a document and reveals their structural or semantic role.
These include concepts such as preamble, section, paragraph, clause, reference,
etc. In Akoma Ntoso there are almost 310 different element names to select
from, covering a large majority of situations encountered in any legal
document.
Besides the very specific names, Akoma Ntoso provides many
generic names for those circumstances that are not precisely described by
specific names. It is of fundamental importance to use generic elements only
when no specific term is available in Akoma Ntoso.
In computer science, an ontology is a data model that
represents concepts within a single domain and relationships between those
concepts. Ontologies identify a number of classes of relevant concepts and the
properties and the relationships between those classes.
Akoma Ntoso uses ontologies to relate facts and statements
about the document and its content to concepts, things, individuals, and
organizations that are mentioned within, but not necessarily stored within, the
document being marked up.
For instance, the identification of a specific individual
acting as a “Deputy Minister” in a “Parliamentary Debate” requires not only
uniquely specifying the “name of the individual,” but also a mechanism to
reliably associate the debate to that specific individual (as opposed to any
other individual who might have the same name). This is done through ontologies
that allow enriching documents, not just with metadata, but also with
information that refers to clear, unambiguous and verifiable concepts.
The recording of information in this way also helps document
the workflow and the process used to create the document.
Akoma Ntoso makes an explicit and complete separation
between the role of authors (who take the responsibility for the content in
terms of sentences, words, and punctuation - e.g. sponsor of an act ) and that
of editors (who physically write the text on the mandate of the author - e.g.
attorney - and decide and organize the final layout and publication of the
document).
In the field of legal publishing, the concept of an author
may be somewhat abstract (e.g., a legislator offering an amendment), whose
content is the result of a formal action (e.g., a final vote of approval),
while editors may intervene at all stages of the publication process.
In this regard, distinguishing between the content and an
editorial addition is in many cases subtle and may be difficult to establish. A
rule of thumb is to try to determine the state of the document at the moment it
left the hands of the author and was taken in by the editors. For instance,
even publication in an Official Gazette does not clearly establish the
“official” content of a document. Some published data (such as the number of
the gazette itself) was not decided upon by the official authors and as such
should be considered metadata and not content.
Editors have two main tasks in the production process of
Akoma Ntoso documents:
·
To identify and label (i.e., mark up) the pieces of the original
content according to their role and structure;
·
To provide additional information about the document itself that
is not contained in the official text as created by the original author.
The main purpose of the Akoma Ntoso is to develop a number
of connected standards, vocabulary and guidelines for deliberative bodies, parliamentary,
legislative, executive, administrative and judiciary documents, and
specifically to:
·
Define a common document format;
·
Define a common model for document interchange;
·
Define a common data schema;
·
Define a common metadata schema and ontology;
·
Define a common model for citation and cross-referencing.
Deliberative bodies function through the medium of
documents. Debate in legislative chambers and court proceedings are recorded as
documents. Legislation is passed through the voting process via a combination
of documents, the proposed legislation itself, proposed amendments, committee
working papers, and so on.
Given that most of the processes are document-centric, the
key enabler of streamlined information technology in these bodies is the use of
open document formats for the principal types of documents. Such open document
formats allow easy exchange and aggregation of information – in addition to
reducing the time required to provide the information via different electronic
published media.
The IT industry has coalesced around a standard technology
for open data/document formats known as XML (eXtensible Markup Language). Akoma
Ntoso makes use of XML to define the structure and syntax of its open document
standards. It includes a set of XML-based parliamentary, legislative and
judiciary open document formats to cover:
·
Parliamentary and Committee records and reports;
·
Committee briefs;
·
Journals, Bulletins, Official Gazettes, etc.;
·
Legislation and regulation — covering the life-cycle of a piece
of legislation;
·
Judgments.
This specification defines a common MODEL for data
interchange and open access to the deliberative bodies’ documentation, such as
parliamentary, legislative, and judiciary texts.
Regardless of the processes that generate and use
parliamentary, legislative, and judiciary documents; regardless of the cultural
and historical factors that give shape and substance to these documents; and
regardless of the human languages in which these documents are written, there
are undeniable similarities that are shared by documents of the same type, of
different types, for different purposes, of different countries.
One of the main objectives of Akoma Ntoso is to be able to
capture and describe these similarities so as to unify and streamline, wherever
possible and as far as possible, the formats and software tools related to
parliamentary, legislative, and judiciary documentation, and to describe
processes in a similar way. This lends itself to reducing the need for local
investments in tools and systems, to helping open access, and to enhancing
cooperation and integration of governmental bodies both within the individual
countries and between them.
Akoma Ntoso defines a model for open access focused on the
following issues:
·
Generation of documents: it should be possible to use the same
tools for creating the documents, regardless of their type, country, language,
and generation process.
·
Presentation of documents: it should be possible to use the same
tools to display on screen and print on paper all documents, regardless of
their type, country, language, and generation process.
·
Accessibility of documents: it should be possible to reference
and access documents across types, languages, countries, etc., converting the
network of explicit references among texts into a web of hypertext links that
allow the reader to navigate easily and immediately across them.
·
Description of documents: it should be possible to describe all
documents, regardless of their types, languages, countries, etc., so as to make
it possible to create repositories, search engines, analysis tools, comparison
tools, etc.
At the same time, the Akoma Ntoso model considers the
differences that exist in individual document types, that are derived from
using different human languages, and that are implicit in the legislative
culture of each country. Therefore, the common open access model is designed to
be flexible, to support exceptions, and to allow extensions far enough to
provide support for all individual characteristics that can be found in a
complete document set covering different cultures and countries.
This specification defines a common parliamentary,
legislative and judiciary document-centric schema.
Parliaments and courts work with a number of distinct types
of documents such as legislation, debate records, parliamentary questions,
judiciary proceedings, judgments, etc.
Akoma Ntoso explicitly supports each major type of document
with specific provisions for individual characteristics. The definition takes
the form of human and machine-readable document models, according to the
specification tools made available by XML schema, the specification language
used by XML.
All document types share the same basic structures, provide
support for metadata, addressing and references, differentiate common
structure, and may accommodate national peculiarities.
All documents can be produced by the same set of tools
(although specialized tools may provide more detailed and specific help in
specific situations), need the same tools to be displayed or printed (although
specialized tools can provide more sophisticated and individual presentations),
can reference each other in an unambiguous and machine-processable way, and can
be described by a common set of metadata that assists in indexing, analysing
and storing all documents in long-term perspective.
This specification defines a common parliamentary,
legislative and judiciary METADATA schema and ontology.
Metadata is structured information about a resource.
Metadata records information about a document that is not actually part of its
content, but is necessary to examine in order to deal with the document itself
(for instance, information about its publication, lifecycle, etc.). Metadata
also enables a document to be found by indicating what the document is about
and how it can be accessed. Furthermore, metadata facilitates the discovery and
use of online resources by providing information that aids and increases the
ease with which information can be located by search engines that index
metadata. Metadata values are labelled and collected according to a common
ontology, i.e. an organized description of the metadata categories that
describe the resources. A shared ontology is fundamental to providing a way for
managing, organizing and comparing metadata.
The parliamentary, legislative and judiciary ontology is
concerned particularly with records management and document management, and
covers the core set of data elements needed for the effective management and
retrieval of official parliamentary, legislative, and judiciary information.
The aim of the parliamentary, legislative and judiciary ontology is to provide
a universal schema for all the information about a document that is available
to its owner, but does not belong to the document itself, and might be needed
for managing or searching the document. The Akoma Ntoso informal ontology
provides direct translation of some of its values into the corresponding
properties of the Dublin Core metadata schema (an international standard for
the description of electronic documents available online), and uses values and
terms drawn from the legal thesaurus by legal professionals to improve
searchability.
Nonetheless, the ontology is designed to be extensible so
that parliaments and courts with different, or more specific metadata needs may
add extra elements and qualifiers to meet their own requirements.
This specification defines a mechanism for citation and
cross referencing of data between documents.
The Akoma Ntoso naming convention and the corresponding
Akoma Ntoso reference mechanism are intended to enable a persistent,
location-independent, mechanism for resource identification and active
referencing. The adoption of a schema based on the naming convention allows the
full automation of access to documents in a fully distributed hypertext.
The Akoma Ntoso naming convention can provide for:
·
the direct access to the document being referred to, regardless
of type, jurisdiction, country, or emanating body.
·
the specification of the existence, at a certain time, of more
than one copy of the same document being referred to;
·
the possibility that references to resources not yet published on
the web are present.
Official documents, bills, laws, acts, and Judgment s
contain numerous references to other official documents -Judgments, bills,
laws, and acts. The whole parliamentary, legislative and judiciary corpus of
documents can be seen as a network, in which each document is a node linking,
and linked by, several other nodes through natural language expressions. The
adoption of a common naming convention and a reference mechanism to connect a
distributed document corpus, like the one embodied by the parliaments and
courts, will greatly enhance the accessibility and richness of cross
references. It will enable comprehensive cross referencing and hyper-linking,
so vital to any parliamentary, legislative and judiciary corpus, from:
·
debate record into legislation
·
section of legislation to section of legislation in the same act
·
section of legislation to section of legislation in another act
of the same Parliament or of an institution like the Pan African Parliament or
European Parliament;
·
from judgments to other judgments and acts.
Defining an XML language goes through four different
specifications:
·
The namespace, i.e., the official and unambiguous identifier
and name of the language (in Akoma Ntoso, that is http://docs.oasis-open.org/legaldocml/ns/akn/3.0).
·
The vocabulary, i.e., the set of reserved words that will
be used for the language. In XML the vocabulary is used to specify the name of
elements and attributes of the language. Currently, Akoma Ntoso defines 310
names for elements and 69 names for attributes and it uses the lower camel case
naming convention for both elements (e.g. mainBody, amendmentList) and for
attributes (e.g. showAs, refersTo).
·
The grammar, i.e., the rules that are used to build a
correct (or, in XML, valid) instance of a document in the XML language being
defined. The grammar is composed of rules that dictate what content is legal to
appear within any element (which is called the content model), both in terms of
other elements and characteristics of the text itself.
·
The semantics, i.e., the mapping between the vocabulary
and rules being used in a valid document, and the actual meaning inferable from
its markup. The semantic of an XML markup is absolutely dependent on the kind
of use the markup document is subject to (often called the downstream
application). For ensuring multiple different uses, both by humans and computer
applications, declarative semantics is preferred, where by declarative we refer
to the description of the element as declaring the content as it is in terms of
structure, role or purpose, rather than as it should be handled by any specific
downstream application.
This 4-part distinction is explicit in Akoma Ntoso, and is
used to ensure the long life and widespread usefulness of all documents
expressed in this language.
URIs/IRIs, or Uniform Resource Identifiers/Internationalized
Resource Identifier, are standard mechanisms for referring to documents,
languages and concepts on the World Wide Web. A good URI/IRI has either an
identification purpose (i.e., it provides a way to universally refer to that
resource in a manner that does not change with time, computer systems or
software versions) or a location purpose (i.e., it provides a way for a
software or a human to unambiguously and rapidly access the resources wherever
it is stored), or, on some situations, both.
Akoma Ntoso gives a lot of importance to URIs/IRIs, and
provides systematically specific URIs/IRIs for all documents, concepts of the
ontology, and even for the markup language itself. All such URIs/IRIs are
described in the Akoma Ntoso naming convention.
The Akoma Ntoso standard defines a number of referenceable
concepts that are used in many situations in the lifecycle of legal documents.
The purpose of this section is to provide a standard referencing mechanism to
these concepts through the use of URI/IRI references associated to classes and
instances of an ad hoc ontology. The referencing mechanism discussed in this
document is meant to be generic and evolving with the evolution of the
underlying ontology.
The most important concepts of the Akoma Ntoso informal
ontology are related to documents that have legal status. All discourse and all
description of legal sources can be characterized as referring to one of the
four levels of a document as introduced by IFLA FRBR (International Federation
of Library Associations (IFLA) - Functional Requirements for Bibliographic
Records (FRBR) http://www.ifla.org/VII/s13/frbr/frbr.pdf):
·
WORK: the abstract concept of the legal resource (e.g., act 3 of
2005).
·
EXPRESSION: any version of the WORK whose content is specified
and different from others for any reason: language, versions, etc. (e.g., act 3
of 2005 as in the version following the amendments entered into force on July
3rd, 2006).
·
MANIFESTATION - any electronic or physical format of the
EXPRESSION: MS Word, Open Office, XML, TIFF, PDF, etc (e.g., PDF representation
of act 3 of 2005 as in the version following the amendments entered into force
on July 3rd, 2006).
·
ITEM: the physical copy of any manifestation in the form of a
file stored somewhere in some computer on the net or disconnected (e.g., the
file called act32005.pdf on my computer containing a PDF representation of act
3, 2005).
In computer science, an ontology is an organized collection
of facts and assertions about a specific domain. Ontologies identify a number
of classes of relevant concepts and their properties and the relations between
these classes. In a properly organized ontology, through classes and properties
it is possible to derive (technically, infer) new properties relating instances
of the classes even if there are not explicitly present in the description of
the instances themselves.
Within the World Wide Web, the discipline of ontologies is
gaining visibility and widespread adoption, thanks to the initiative called the
Semantic Web by the W3C. Within this initiative, several languages have been
defined, including RDF [RDF], RDF Schema and OWL. Such languages allow specific
ontologies to be defined, mixed and interchanged for a wide number of purposes.
Akoma Ntoso allows multiple different ontologies to be
created about the document it describes. Rather than defining an ontology of
the legal matter being discussed in the legal documents (which could be overly
wide and all-encompassing, since the legal matter may be by itself rather wide
and all-encompassing), the Akoma Ntoso specification provides mechanisms to
define arbitrary ontologies and connect them to the various parts of the
document and of the text. Akoma Ntoso informal ontologyThe Akoma Ntoso informal
ontology is therefore centered on the concept of document, which is considered
in a very precise way through the specification of the FRBR conceptualization
of documents (about which see the next section). Besides the FRBR classes for
document, the Akoma Ntoso informal ontology also lists a number of supporting classes
(such as Person, Organization, Place or Event, that are used to provide further
meaning to the main classes of the ontology.
Patterns are the abstraction and distillation of past
experiences in designing and resolving design problems. They are general and
widely applicable guidelines for approaching and justifying design issues that
often occur in XML-based projects.
In Akoma Ntoso, patterns are used to create categories of
content models (and thus correspond to only those content models that have been
found to be actually useful) and, more generally, in schema design (and thus
correspond to guidelines on how to make the schema more modular, flexible, and
understandable to by users). Both approaches are well known and well established
in the literature, although by different experts in different ways.
Categories of content models is the term used within Akoma
Ntoso to refer to families of elements that share the same conceptual
organization of the internals. The Akoma Ntoso schema uses six categories of
content models. This means that all content models and complex types used in
the schema follow precisely the form of the relevant category, and all elements
can be simply described and treated according to their category rather than
individually.
These categories are:
The markers: markers are content-less elements that
are placed here and there in the document and are meaningful for their
position, their names and their attributes. Markers are also known as empty
elements or milestones. There are two main families of markers in the Akoma
Ntoso schema: placeholders in the text content (e.g., note references) that can
appear in any position that also has text, and metadata elements that only
appear in some subsection of the <meta>
section. In Akoma Ntoso, all metadata elements are markers, so that metadata
values are not part of the text content of a document, but rather become
attribute values.
The inlines: an inline element is an element placed
within a mixed model element to identify a text fragment as relevant for some
reason. There are both semantically relevant inlines and presentation oriented
inlines. There is but one content model using inlines (and markers), which
means that all mixed model elements (i.e., those that allow both text and
elements) also allow a repeatable selection of all inline elements. For a
discussion of why this is only a trade-off decision, and not the ideal
solution, see the discussion at the end of this section.
The blocks: a block is a container of text or inlines
and placeholders that is organized vertically on the display (i.e., has
paragraph breaks). Most blocks in Akoma Ntoso are based on the HTML language.
There is only one content model that uses blocks, and it allows a repeatable
selection of all available blocks. This means that wherever any block is
allowed, all blocks are allowed, as well: e.g., wherever a paragraph is
allowed, a table or a list is also allowed.
The subFlow: a subFlow element is an element placed
within a mixed model element to identify a completely separate context that,
for any reason, appears within the flow of the text, but does not belong to it
or does not follow its rules. subFlow elements are containers appearing in the
middle of sentences but containing full structures (with no direct containment
of text or inline elements).
The containers: containers are sequences of specific
elements, some of which can be optional. Containers are all different from each
other (since the actual list of contained elements vary), and so there is no
single container content model, but rather a number of content models that
share the same conceptual category. The shared characteristic of containers, is
that no text is allowed directly inside them, but only a collection of other
elements. Text therefore can only be placed within a block within the
container.
The hierarchy: a hierarchy is a set of sections
nested to an arbitrary depth, usually provided with title and numbering. Each
level of the nesting can contain either more nested sections or a container. No
text is allowed directly inside the hierarchy, but only within a block element
that is contained within a container element (not considering, of course,
titles and numbering). Akoma Ntoso uses only one hierarchy, with predefined
names and no constraints on their order or systematic layering.
There are two exceptions to the systematic use of patterns:
·
The <li> element allows both inlines and other nested lists
(<ul><ol><li>).
The pattern would require elements to contain only text, and nested lists to be
direct child of the main list. Since this goes against universal HTML practice,
we have decided against full pattern adherence and in favor of HTML tradition.
·
There are some inline elements that only make sense in the preface
and/or preamble of the document: for instance there are <docTitle> and,<docNumber>
, for numbered documents such as acts or bills, or , for judgments. They
are, in fact, part of the one inline content model and thus are available
everywhere in the document. There is no simple way to define blocks within <preamble> and <preface> to allow these
elements and blocks elsewhere to reject them, so it has been decided that it is
better to allow them everywhere rather than uselessly complicating the schema.
Design patterns are a distillation of common wisdom in
organizing the parts and the constraints of a schema. Some of them are listed
in http://www.xmlpatterns.com/. Whenever there has been a design choice to be
made that was not immediately obvious and naturally acceptable, a relevant
pattern has been sought and properly used. In fact, http://www.xmlpatterns.com/
also contain immediately obvious and naturally acceptable patterns that have
been used in Akoma Ntoso, but only the not-so-obvious and not-so-natural ones
have been explicitly mentioned and referred to. You can find the relevant
references in comments within the schema itself, and in the documentation.
Akoma Ntoso provides explicit support for many different
document structures within the context of parliamentary and judiciary
activities: legislative documents (e.g. bills, acts, etc.), amendment documents
(e.g. amendment), parliamentary documents (e.g. debates, hansard, report,
etc.), judiciary documents (e.g. judgments), collection documents (e.g.
Official Gazette, etc.), general document (e.g. annexes, memorandum, etc.).
The information organized within the documents corresponds
to various typologies of documents.
|
Akoma
Ntoso
Document
Types
|
Category
/
Legal Document
|
Definition
|
|
bill/act
|
Akoma
Ntoso type :
hierarchicalStructure
Legal
Document:
bill/act/ordinance/decree/subsidiary
legislation/executive orders/ normative standard/ administrative regulation/etc.
|
These
are deliberative documents produced by parliamentary activities or from other
empowered bodies (e.g. Committee). They are usually drawn up according to a
hierarchical structure in which the text is subdivided into sections or
chapters. These are subdivided into clauses or articles, sub-paragraphs, etc.
|
|
debate
|
Akoma
Ntoso type:
debateStructure
Legal
Document:
debate
record/Hansards/judicial verbatim
|
These
are texts resulting from the transcription of the any deliberative works. The
structure reflects the different section of the debates and alternation of
questions and answers that takes place during the parliamentary works. This
structure could be used, for instance, for parliamentary/judicial verbatim,
UN/FAO transcript of assembly or council, etc.
|
|
debateReport
|
Akoma
Ntoso type:
openStructure
Legal
Document:
committee
minutes/judicial minutes
|
These
are texts that are minutes or reports usually of the committee used to
describe official meeting sessions.
|
|
judgment
|
Akoma
Ntoso type judgmentStructure
Legal
Document:
judgments//case-law/precedents
|
These
are documents in which a court of law makes a formal decision or specific
determination following a lawsuit. The structure reflects a typical narrative
of sentences.
|
|
doc
|
Akoma
Ntoso type:
openStructure
Legal
Document:
any
other type of document/Executive SummaryMemorandum/etc annexes/table/judicial
documents
|
These
are texts that are legally valid but do not have any particular structure.
These include any parliamentary procedure document that has no particular
textual structure and is not a collection of other documents. An example
could be also the Report of the Amendments of a Bill, the Memorandum of a
Bill, Order of Business, Legal Notice, judicial documents, etc.
|
|
documentCollection
|
Akoma Ntoso type collectionStructure
Legal Document:
collection of documents
|
Used
to represent documents which are collections of other independent documents.
A typical example is the electronic folder related to a bill. This folder is
composed of several independent documents (committee reports, initiative,
bill, memorandum, etc.) and by different expressions over time such as
versions of the same bill. Another example is the U.S. Code: it is a
documentCollection composed of various Titles of positive and non-positive law.
In
European institutions, the committee report, for example, can be considered
as a document collection, as it includes documents like Resolutions,
Explanatory Memorandum or Opinions from other committees.
|
|
amendmentList
|
Akoma
Ntoso type collectionStructure
|
Used
to represent a special document that includes all the amendments, collected
and submitted to the official deliberative body for the discussion.
|
|
officialGazette
|
Akoma
Ntoso type collectionStructure
|
Used
to represent an issue of an official publication body such as Official
Gazette, Journal, Bulletin or Federal Register.
|
|
amendment
|
Akoma Ntoso type amendmentStructure
Legal Document:
Amendment document
|
Used
to describe specific amendment documents. It is a special document or a
component of an amendment list, presented by the member(s) of parliament to
the committee or to the assembly for discussion and vote.
|
|
statement
|
Akoma
Ntoso type
openStructure
Legal
Document:
US
resolution
|
Used
to represent those legal documents that may or may not be normative, but they
are fundamental for the life of an official institution. Often they have a
mixed structure (blocks and hcontainers): an example is a resolution issued
by the US Congress, or an UN resolution/declaration. Other examples are the
resolution or decision from European Parliament.
|
|
portion
|
Akoma Ntoso type
portionStructure
Legal Document:
chapter
of a document
|
Used
to represent a portion of any document at manifestation level.
|
Akoma Ntoso is designed for use in all applications that use
legal documents. This includes applications both inside and outside the
deliberating bodies that make the law. Akoma Ntoso includes, without being
limited to, support for:
·
the initial drafting of bills;
·
the legislative lifecycle including amendments, publication in
the official gazette, and the recording of debates;
·
the comparison between different version of the bill;
·
the enactment and consolidation of those bills to produce the
law;
·
the codification, recasting, coordination of the acts when some
changes are issued;
·
the publication of the law and comparison between two different
versions of the same law; and
·
applications that involve the research and tracking of laws and
legislation.
Akoma Ntoso also gives to the applications a representation
of case-law, precedents, and judgments including those produced by the
Constitutional Court that can affect the law.
Legal documents are
important to many different people and organizations. These range from the
people who originally request or propose new laws, the person tasked with
drafting the legislation, the legislators who sponsor and debate the
legislation, the people who want to alter that legislation, the person who
signs the legislation into law, and the people affected by the resulting law.
Akoma Ntoso provides support for this diverse group of actors involved in the
legislative process.
There are numerous processes that involve legal documents.
Some processes within governments or institutions involve the production and
issuance of legal documents. Other processes, by other government agencies or
external entities interested in following or conforming to the law, involve the
tracking and consumption of legal documents. Akoma Ntoso is designed to support
all the processes that involve legal documents, whether it be the initial
drafting of legislation, the process that results in the enactment of laws, or
the follow-on processes to track and comply with those laws.
Every country and every jurisdiction has unique
requirements. This is a simple consequence of separate development of legal
traditions around the world over time. However, upon further examination, it is
quickly apparent that all the varying traditions found around the world stem
from a relatively small set of legal traditions originating back in history.
Akoma Ntoso has been designed, through careful examination of the world's legal
practices, to take advantage of the common heritage found in all our legal
systems while also providing enough flexibility to adapt to all the variations.
It is important that a legal data model support not only the
future needs of legal information systems but also the past. Akoma Ntoso is
designed to anticipate the future needs made possible by a uniform standard for
legal documents while also being flexible enough to adapt to past practices,
allowing all the variances that have occurred in the past to be modeled in a
single document structure.
Dematerialized legal documents modeled and represented in
XML preserve their legal validity over time, maintaining a clear separation
between original content (as formalized in the enactment stage) and the
reworking of that text during the reporting process. This allows us to include
a digital signature in the XML document, thus freezing authenticated documents,
even digital ones, so that it can be represented in the future without
subsequent modifications.
It should be possible
to understand the markup of a legislative document without having to first
study and understand the associated schema or having to possess any knowledge
of any special theory behind the design. For this reason, the vocabulary
should adhere as close as possible to the legal domain terminology, while also
being as neutral as possible with respect to any legal-specific tradition.
A good legal XML schema must encapsulate knowledge in one
self-contained document without fragmentation in the logical schema of a
database or document processing application. This preserves a document’s
neutrality with respect to applications, platforms, and technological
developments. It also keeps intact the expressive power of the legal knowledge
contained in the document so that the document can move freely throughout the
network.
The first important point is the explicit and complete
separation between the role of authors (who decide and write the actual content
in terms of sentences, words, and punctuation) and of editors (who decide and
organize the final layout and publication of the document). We often say that
the author has created the content and the editors have created the metadata.
Another way to put it is that the author is the creator of the FRBR Expression,
and the editors are the creators of the FRBR Manifestation.
In the field of legal publishing, the author is often an
abstract concept (e.g., the legislator), whose content is the result of a
formal action (e.g., a final vote of approval for a highly discussed text),
while editors can be involved at all stages of the publication process. In this
regard, the identification of what constitutes the content and what is an
editorial addition is in many cases subtle and difficult to establish. A rule
of thumb is to try to determine the state of the document at the moment it left
the hands of the author and was taken in by the editors. For instance, even the
publication of the document on the official gazette does not determine clearly
the “official” content. Some published data (such as, for instance, the number
of the gazette itself) were not in the hand of the official authors and as such
should be considered metadata and not content.
This basic distinction generates, on the other hand, a few
secondary reflections that need to be discussed briefly.
Many types of legal documents have a “more important” form
of publication than others. We will call this the authoritative (or official)
form. More often than not, this is a version of the document printed on paper
and published within official channels (e.g., the official gazette) after a
number of well-known and highly controlled editorial steps. All conversions
into electronic formats, by their very nature, have an authoritative status
that is of lesser authoritativeness than the official form. Any doubt arising
about the correctness of its content should therefore be redeemed by comparing
the content of the electronic format with that of the authoritative form, which
remains the guarantee of the authorial intention.
Markup is the act of adding annotation and labels to the
fragments of a document in order to allow computer-based processes to be
carried out (from publication to print to storage to technical analysis, etc.).
The markup process is the process of actually adding these
annotations and labels to the original text according to a specific syntax that
is dictated by the computer environment (in the case of Akoma Ntoso, this means
adding XML tags around the text fragments that have been identified and
classified).
Of course this means adding to the original content, and in
this sense, according to the definitions above, it has to be considered an
editorial process and not an authorial process.
Akoma Ntoso defines a series of rules for giving a name
(technically, a URI/IRI) to all the electronic versions of the legislative
documents -the Akoma Ntoso naming convention. For these electronic versions to
work correctly within the applications that make use of the Akoma Ntoso
standards, it is necessary that the URIs/IRIs are correctly determined. These
URIs/IRIs are derived in many ways from the “official” or the “most used” names
of the documents, but do not necessarily look like them. Because they are
defined by the creators of the XML representation, they are considered
editorial in nature. Nonetheless, it is of the uttermost importance that they
are created correctly and precisely according to the Akoma Ntoso Naming
Convention or any other functionally equivalent naming convention.
Editors (i.e., the creators of the FRBR Manifestation) have
two main tasks in the production process of Akoma Ntoso documents: on the one
hand to identify and label (i.e., mark up) the fragments of the original
content according to their role and structure, and on the other, to provide
additional information about the document itself that is not contained in the
official text as created by the original author.
Collectively, this additional information is called
metadata. Since these are metadata elements, and since they are added at markup
time, their specification is an editorial process, and not an authorial
process, and come under the responsibility of the creator of the markup.
Another pillar of Akoma Ntoso is that it is both descriptive
and prescriptive. By descriptive we mean a standard that accurately describes
with tags the document’s various organizational functions (articles, chapters,
sections, headers, etc.), allowing an expert to read the document under the
guidance of the vocabulary used to enclose the text into sections.
A standard is descriptive when it uses a vocabulary of tags
representing the domain where it should be applied. The tags are selected by
domain experts, not by computer technicians, so that the tags enable the markup
to convey the true semantic meaning they contain.
A standard is prescriptive when it defines the tags’
coercive behavioral rules, thus determining not only the vocabulary but also
how it should be applied. In legal drafting, we usually deal with codes of
rules that define behaviors and conventions for the correct formation of laws:
in a prescriptive XML standard, these rules can be translated into technical
delimitations included in the standard itself to facilitate compliance with the
rules of legal drafting. For example, an XML document consisting of articles
could be set-up in such a way that articles will always have a unique number;
i.e. paragraphs are sequentially numbered and the structure is hierarchical.
Otherwise, the XML document will not be standard-compliant; hence it will not
be valid.
For example, a legislative official can open an XML document
marked in Akoma Ntoso and, without knowing anything about XML, guess the
function of each of the document’s parts that are referred to with tag names
which matter to the expert and not to the computer technician. On the other
hand, other standards have chosen to use technical terminology and vocabulary
where the item is not enclosed within tags such as <article>,
but are enclosed within more neutral terms such as <paragraph>
or <block>.
Secondly, Akoma Ntoso uses its own schema to provide a set
of rules for good regulations requiring a minimum set of quality links (e.g.,
numbering the articles). Thanks to this feature, tools can verify the correct
composition of legislative text.
Akoma Ntoso maintains four levels - clearly and strongly
separated for the representation and description of legal documents:
·
Content: what exactly is written in the document (e.g. the text);
·
Structure: how the content is organized (e.g. articles, chapters,
etc.);
·
Semantics: the conceptual framework of knowledge needed to
understand the document (e.g. for understanding what is the <def> you need to know what is a
definition in the juridical domain and to combine the term to an ontological
class);
·
Presentation: the typographical choices to present a document on
screen or on paper (e.g. right aligned, bold, italic).
Contrary to other XML-schemas, Akoma Ntoso separates the
levels for maintaining the independence of the content from the semantic and
from the presentation. In this way it is possible to semantically annotate the
same content fragment several times without forcing the user to mark-up the
document again. The same principle applies to the presentation: using the class
attribute it is possible to define the semantic approach to the presentation,
but the values of those parameters are defined externally to the XML file. This
permits changing the layout several times without intervening on the physical
XML document. Using XSLT and CSS it is possible to assign a proper presentation
to a defined class. For example, if we have <title
class="bigger right italic bold">, it is possible to define
the main characteristics of presentation of the content <title>, but the specific values of these
parameters are defined in a CSS (e.g. bigger means size 14, right means on
right aligned, and so). When a media needs to have a different presentation
only the CSS is properly adapted to the new needs.
A critical characteristic of a successful XML model is its
ability to evolve over time. This “evolvability” has been a key concern in the
creation of the Akoma Ntoso model. Thus, although the language is built to
change over time, the language can be customized at will for local needs and
purposes, and still be made compatible with the overall Akoma Ntoso
infrastructure and the general language.
Furthermore, the language is built to withstand changes even
regarding the number of actual functions provided: features such as the number
and type of metadata values, or the automatic generation of amended text, or
the activation of special analysis tools on the text that may require the
language to evolve in time. In these cases, it can be guaranteed that existing
documents already marked up according to initial versions of Akoma Ntoso will
be either immediately compatible with the new schemas, or easily convertible to
it via a single XSLT stylesheet that is provided.
Akoma Ntoso provides a flexible legal vocabulary for
reflecting all the legal tradition requirements. The <heading> element in each hContainer part could be before or after <num> or <subheading>. However in some legal tradition some
elements are located in a precise order and some customization of the grammar
is necessary. It is the case of Japan legislation or Scotland subsidiary
regulation where the <heading>
preceed the number of the article:
|
(Definitions)
Article 2 (1) The term "Insurance Business" as
used in this Act means the business of underwriting the risks listed in the
items of Article 3, paragraph (4) or the items…
|
For instance, the following example shows a Schematron
fragment verifying that the <heading>
appears before <num> in
the <article> element:
|
<xsd:appinfo>
<sch:pattern
id="article"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:rule context="article">
<sch:assert test="*[1][self::heading]">heading must be first
child of article</sch:assert>
<sch:report test="*[2][self::num]">num must be second child
of article</sch:report>
</sch:rule>
</sch:pattern>
</xsd:appinfo>
|
Finally in Akoma Ntoso exists some elements that permits to
include extra-elements:
1. in
metadata block we have: proprietary (see also 5.10.13.1), presentation (see
also 5.10.13.2), preservation (see also 5.9.1.1), and otherAnalysis (see also
5.10.9);
2. in the
content block we have: foreign (see also 5.14).
As we have seen, the seven document types differ mainly in
the way the “main content” of the document is structured. In the table below we
describe the main characteristics of the structure of the “main content” part
of the different document types.
|
Document type
|
Akoma Ntoso
main element
|
Description
|
|
bill/act
|
<body>
|
The body is used for bills and acts and presents an
explicit hierarchy of parts each part of which can be identified with a
meaningful name (such as section, tome, etc.) and possibly provided with
numbers and various types of headings.
Akoma Ntoso provides a large number of names for these
parts (title, book, tome, part, chapter, section, paragraph, article, clause,
division, level, list, subtitle, subpart, subchapter, subsection,
subparagraph, subclause, sublist, point, indent, alinea). Some legislative
traditions may use names which may not match the part names specified above –
for such use cases a generic container called an hcontainer' (i.e.
hierarchical container) is provided which can be identified with a name and
supports the same hierarchical structures provided by the named parts.
|
|
debate record
|
<debateBody>
|
The debateBody contain a hierarchy of subdivisions at the bottom
of which can be specified blocks of text or individual utterances of
individuals participating in the debate, as well as comments from the
drafters.
Subdivisions are explicitly listed (administrationOfOath,
declarationOfVote, communication, petitions, papers, noticesOfMotion,
questions, address, proceduralMotions, pointOfOrder, adjournment, rollCall,
prayers, oralStatements, writtenStatements, personalStatements,
ministerialStatements, resolutions, nationalInterest), plus a generic element
debateSection for all unnamed subdivisions and all those subdivisions whose
appropriate name is not listed here.
Within debateSection, individual text structures can be
marked up with one of eight containers, speechGroup, speech, question,
answer, scene, narrative, summary, and other.
It is worth noting that those containers that refer to
actual utterances (i.e. speech, question, answer) have a peculiar structure
which imposes the identification of a speaker through the from element (which
is displayed on the print version of the document) plus references to
individuals and roles expressed through the by, as, and to attributes,
specifying, respectively, the id of the individual uttering the speech, the
role (if any) the individual is assuming when uttering the speech, and the
addressee (if any) of the speech.
For this reason, these elements are enriched with special
attributes:
by: who is the speaker; as: the role of the speaker; to:
who is the addresser of the speech.
<question
by="#Smith" to="#deputyPresident" as="#member">
|
|
judgment
|
<judgmentBody>
|
The judgmentBody contains four sections (introduction,
background, motivation, and decision - the standard does not mandate an
order), that need to be present one or more times as needed. These sections
may contain basically any kind of substructure (containers, blocks,
hierarchical elements, etc.).
|
|
document,
debateReport, statement
|
<mainBody>
|
The mainContent element of an open structure is a generic
collector of all preceding structural elements in any order and number.
This kind of open structure is meant for collecting and
marking up those document types whose structure is too varied, or too
different from the norm, or not well standardized, or too full of exceptions
to be worth describing explicitly.
|
|
collections
|
<collectionBody>
|
The collectionContent is used for including multiple
documents that maintain their autonomy, but can be managed as a unique
container. It is thus possible to compose an issue of the Official Gazette as
a combination collection of several acts. The same for the Amendment List
document composed of a set of separate amendment documents.
This structure permits two different approaches:
1 to include directly
in the collectionBody element the other documents (bill, doc, debate, act,
etc.);
2 to include in the
collectionBody element references to the documents using the element <documentRef>. The documentRef
includes the attribute href that specifies the URI/IRI of the document. It is
possible to describe the cited document in the same file inside of the element
<component> or to link an external file using the URI/IRI convention.
<documentRef
eId="dRef_1" href="#bill" showAs="bill"/>
It is possible to associate with each sub document a num
and a heading.
A <documentRef> is a
work-level or expression-level reference to a document that has independent
existence, namely that it has a work-level or expression-level identifier,
and that it is hosted within a containing document.
|
|
amendment
|
<amendmentBody>
|
This element includes the body of the amendment that is composed
of several important parts: amendmentHeading, amendmentContent,
amendmentReference, and amendmentJustification.
|
|
portion
|
<portionBody>
|
This element permits including
a portion of any other document. It is possible to refer to the portion
inside of another Akoma Ntoso document using the <componentRef> element.
|
The document structures of Akoma Ntoso (bill/act, debate,
debateReport, judgment, amendment, statement, and document) have the same
external organization: a place for metadata elements, a cover page, a place for
the introductory matters (e.g. preface/ preamble or header for Judgments), the
main content part of the document (which is different in the four structures),
a place for conclusive remarks, and lastly, a place for listing the attachments
if any. The table below describes briefly the “text sequence” and their parts:
|
Text sequence
|
Akoma Ntoso
<elements>
|
Description
|
|
cover page
|
<coverPage>
|
Information intrinsic to the document such
as: name of the publisher, serial number, issuing authority, number of
committee, number of legislature, number of the session, etc.
|
|
information on the document
|
<metadata>
|
Information on the document that qualifies
and classifies the text as a whole or each fragment. An example is the
keywords for assigning the topic to the document (e.g. privacy, commercial
law, etc.)
|
|
introductory text
|
<preface> / <header>
|
Information related to the title of the
document, the proponent authority, the identification numbers, the date of
approval. In other word, the essential information for citing the document.
It can also contain the long title and a table
of contents.
|
|
justificatory text
|
<preamble> that can
include <formula>
<recitals> and <citations>
|
The introductory part of a document
stating its purpose, aims, and justification.
Introduction, motivations, purposes, legal
basis of a document, in formula, recitals and citations. Formula describes
the enacting sentences that, in many legal traditions, are regular and fixed
linguistic expressions.
Recitals block includes motivations and
justifications of the legal document.
Citation blocks include references to other
legal documents that are fundamental to the current text: legal basis,
preparatory acts as well as the legislative procedures.
|
|
main content
|
<body>: for bill/act
<debateBody>: for
debate record
<judgmentBody>: for
judgments
<mainBody>: for open
structure and for the debate report
<amendmentBody>: for the
amendment
<collectionBody>: for the
collection documents
<portionBody>: for the portion
of document
|
The main part of the document, the part that
is prescriptive or states a declaration (enacting terms). The text is
characterized by a structural complexity that can vary depending on the
document’s typology and purpose.
|
|
conclusions
|
<conclusions>
|
Part in which we may find closing formulas
date and signature.
|
|
authorial notes
|
<authorialNote>
|
Part dedicated to include the authorial notes
added by the author of the document.
|
|
attachments
|
<attachments>
|
Documents can also include attachments with the
precise functionality of completing and integrating the information of the
main text.
Attachments can be an annex (informative or
technical data which, for practical reasons, does not appear in the body).
Attachments or others types of Components can
also be another act or international agreement that is approved by this act.
Those documents are not annexed but attached to the act that approves them. Those
documents are not annexed but attached to the act that approves them.
|
|
components
|
<components>
|
Document can also include components that are
independent works, expressions, or manifestations.
Each component can have a num and/or an heading
before the document.
|
All elements in this schema fall under one of six content
models: hierarchical container, container, subFlow, block, inline and markerBesides
named elements, the schema also provides for a generic element for each of them
that can be used for markup and that fits the content models but can be
specified by a precise name that is not used in this schema. The 'name'
attribute must be used for naming the element. When required,
the attribute name gives a name to the element.
|
hcontainer
|
The hcontainer element is a generic element for a hierarchical
container. It can be placed in a hierarchy instead of any of the other
hierarchical containers. The attribute name is required and gives a name to
the element.
|
|
container
|
The container element is a generic element for a
container. It includes elements belonging to the block pattern.
|
|
subFlow
|
The subFlow element is a generic element for a sub-flow.
It includes elements belonging to the hcontainer, container and/or block
patterns.
|
|
block
|
The block element is a generic element for a container. It
can be placed in a container instead of any of the other blocks. The
attribute name is required and gives a name to the element.
|
|
blockContainer
|
The element blockContainer is used as a
container of many individual block elements in a block context.
|
|
tblock
|
The tblock element (titled block) is used
to specify a container for blocks introduced by heading elements, similarly
to a hierarchical structure
|
|
inline
|
The inline element is a generic element for an inline. It
can be placed inside a block instead of any of the other inlines. The
attribute name is required and gives a name to the element
|
|
marker
|
The marker element is a generic element for a marker. It
can be placed in a block instead of any of the other markers. The attribute
name is required and gives a name to the element.
|
Akoma Ntoso uses some elements that look like HTML but they
do not belong to the HTML namespace. Even though they are similar tags and have
similar meaning, they are not HTML elements. For this reason, they are reused
inside of Akoma Ntoso avoiding inventing new vocabulary. Sometimes the semantic
are identical (e.g. span) and sometimes it is different (e.g. div).
|
Name of the element
|
Group in Akoma Ntoso
|
Description
|
|
div
|
HTMLcontainers
|
The element div is an HTML element, but is NOT used in
Akoma Ntoso as in HTML. Instead of being used as a generic block, Akoma Ntoso
uses div as a generic container (as in common practice).
The div is used any time you need to define a container
not included in the regular vocabulary.
<div eId="div_1"
class="alignedRight"><p>Address: av.
Smith</p><p>Name: mr. Brown</p></div>
|
|
p
|
HTMLblock
|
The element p is an HTML element and is used in Akoma
Ntoso as in HTML, for the generic paragraph of text (a block)
|
|
ul/ol
|
HTMLblock
|
The elements ul/ol are HTML element for defining
unnumbered or numbered list.
|
|
li
|
HTMLblock
|
The element li is an HTML item of ul or ol.
|
|
table
|
HTMLblock
|
The element table is HTML element for defining a table.
|
|
th/tr/td/caption
|
HTMLblock
|
The elements th/tr/td/caption are HTML elements of the
table.
|
|
span
|
HTMLinline
|
The element span is an HTML element and is used in Akoma
Ntoso as in HTML, for the generic inline.
|
|
b
|
HTMLinline
|
The element b is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating bold style.
|
|
i
|
HTMLinline
|
The element i is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating italic style.
|
|
a
|
HTMLinline
|
The element a is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating a link to hypertext resources.
|
|
u
|
HTMLinline
|
The element u is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating underline style.
|
|
sub
|
HTMLinline
|
The element sub is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating text as subscripts.
|
|
sup
|
HTMLinline
|
The element sup is an HTML element and is used in Akoma
Ntoso as in HTML, for indicating text as superscripts.
|
|
abbr
|
HTMLinline
|
Sometime the act is named with an abbreviation. Akoma
Ntoso manages abbreviation using HTML element abbr (e.g. FOIA for the
"Freedom of Information Act").
|
|
br
|
HTMLmarker
|
It is the line break used in the HTML definition.
|
|
img
|
HTMLmarker
|
It is used as pointer for declaring the position where to
embed an image in the XML manifestation.
|
Other elements inline are shared by all the type of
documents:
|
date
|
The date element permits
marking up any date in the text and associating a particular meaning using
the refersTo attribute.
<date
date="2013-04-04" refersTo="#signatureDate">four April
2013</date>
or to specify the time and
zone
<date
date="2013-04-04T12:00:00"
refersTo="#signatureDate">four April 2013</date>
The
attribute date is used to give a normalized value for a date according to the
XSD syntax YYYY-MM-DD or a normalized value for a dateTime according to the
XSD syntax YYYY-MM-DDThh:mm:ss(zzzz)
|
|
time
|
The time element is an inline element to identify a time
expressed in the text and to propose a normalized representation in the time
attribute
|
|
person
|
The person element is an inline element to identify a
person expressed in the text and connect he/she to the ontological class
|
|
organization
|
The organization element is an inline element to identify
an organization expressed in the text and connect it to the ontological class
|
|
concept
|
The concept element is an inline element to identify a
concept expressed in the text and connect it to the ontological class
|
|
object
|
The object element is an inline element to identify an
object expressed in the text and to connect it to the ontological class
|
|
event
|
The event element is an inline element to identify an
event (e.g. Thanksgiving Day, Royal Assent) expressed in the text and to
connect it to the ontological class
|
|
location
|
The location element is an inline element to identify a
location (e.g. Montevideo, Senate Palace) expressed in the text and connect
it to the ontological class
|
|
process
|
The process element is an inline element to identify a
process (e.g. voting of the bill) expressed in the text and to connect it to
the ontological class
|
|
role
|
The role element is an inline element to identify a role
(e.g. member of assembly, secretary, president, judge, solicitor, etc.)
expressed in the text and connect it to the ontological class
|
|
term
|
The term element is an inline element to identify a term
(e.g. privacy, IPR, etc.) expressed in the text and to connect it to the
ontological class
|
|
quantity
|
The quantity element quantity is an inline element to
identify a quantity (e.g. 20 attendees, IPR, etc.) expressed in the text and
to connect it to the ontological class
|
|
Def
|
The def element is an inline element to identify a
definition (e.g. “stalking” is defined as.....) expressed in the text and to
connect it to the ontological class
|
|
Entity
|
The entity element is an inline element to identify a
entity expressed in the text and to connect it to the ontological class
|
Sometimes it is necessary to represent the text as it is
presented in the official publication. The page and line endings are often
fundamental parts of the official manifestation of the legal document.
For this reason, we have the elements <eol> as the end of line markers
and <eop> as the end of
page markers.
The following example shows a bill from South Africa where
each line is numbered to indicate the number of lines.
The corrispondent XML is showed below. Please notice the <span> for managing the “drop
cap” B with the attribute @class="dropCap" in order to provide the
appropriate instructions for the presentation processing. Secondly the line
numbering is managed using the attribute @numer in the <eol/> element.
|
<preamble>
<formula
name="enactingFormula">
<p><span
class="firstLetterCapital">BE</span> IT ENACTED by the
Parliament of the Republic of South Africa, as follows:-</p>
</formula>
</preamble>
<body>
<section
eId="sec_1">
<num>1.</num>
<heading>
<ref
eId="ref_1"
href="/akn/za/act1996-10-10/84/!main#sec_1">Amendment of section
1 of Act 84 of 1996</ref>, as amended by <ref eId="ref_2"
href="/akn/za/act1997-05-10/100/!main">section 1 of Act 100 of
1997</ref>,
<ref eId="ref_3"
href="/akn/za/act1999-05-10/48/!main#sec_6">section 6 of Act 48
of 1999</ref> and <ref eId="ref_4"
href="/akn/za/act2001-05-10/50/!main">section 1 of Act 50 of 2002</ref>
</heading>
<list
eId="sec_1__list_1">
<intro>
<p>
<ref
eId="ref_6"
href="/akn/za/act1996-10-10/84/!main#sec_1">Section 1 of the
South African Schools Act, 1996</ref>, is hereby amended by-<eol
class="numebring" number="5"/>
</p>
</intro>
<point
eId="sec_1__list_1__point_a">
<num>(a)</num>
<content>
<p>
<mod
eId="mod_1">the insertion after the definition of
“<quotedText
eId="mod_1__qstr_1">Minister</quotedText>”of the following
definitions:
“<quotedStructure
eId="mod_1__qstr_2">
<paragraph
eId="mod_1__qstr_2__para_1">
<content>
<p><ins>
<def>‘no
fee threshold’</def> means the level of funding per learner
contemplated
in the norms and
standards for school funding applicable to a public
school which
enables the Minister to declare a school a no fee school in
terms of this
Act;</ins><eol number="10"/>
</p>
|
Another example is the following fragment of Public Law US
(PUBLIC LAW 112–61—NOV. 29, 2011 ) where the syllabication interrupts the words
“America” and “management”.
Currently, the <eop> and <eol> are used to
identify the end of page (and respectively end of line) as markers-- by their
mere presence at a given position. Therefore, they are placed nearest to the
end of the page and line according to the reference copy in printed form. There
is the assumption that the corresponding beginning of page and line are
immediately after the previous <eop> and <eol> elements.
Additionally, the syntax of <eop>
and <eol> allow for the
adding of three attributes. The first attribute, @breakAt,
specifies the number of characters within the next word that the page (or line)
actually breaks at. This allows in-word breaks to happen even if the word is
not actually broken in the XML. The second parameter, @number, allows specifying a page number or line number
for the element, especially if we did not start at zero (which may happen if
the document belongs to a container, e.g. a gazette ). The third attribute, @breakWith, is for storing the
character used for the syllabication interruption (e.g., hyphen or M dash — or N dash
–).
|
<point eId="sec_2__list_1__point_2">
<num>(2) </num>
<content eId="sec_2__list_1__point_2__content">
<p>
<def refersTo="#americaCupRaceManagement" class="definition">America's cup race management.</def>--The term ``America<eol breakAt="4" breakWith="-"/>'s Cup
Race
Management'' means the entity established to provide for
independent, professional, and neutral race management of the
America's
Cup sailing competitions.
</p>
</content>
</point>
|
Akoma Ntoso includes a sophisticated mechanism to keep track
of the life cycle and evolution of a legal document. This is particularly
useful for acts that are amended and modified in time, while maintaining their
fundamental nature.
The management of the evolution of a document makes two
important assumptions:
§
Modifications and events in the life cycle of a document
(including original approval, final repeal and any other event affecting its
presence in the law system or its content) happen in precise moments in time
that can be determined objectively (albeit possibly with difficulty) and are
attributed to a specific date.
§
Modifications and events in the life cycle are due to the
enactment of a specific, individual document that can be objectively traced
back and identified with an IRI. If two different documents affect the same act
on the same date, then these must be counted as two different and separate
events on the amended act.
Handling events in Akoma Ntoso
centers around the <lifecycle> element in the <meta> section. The
<meta> section contains two containers, among the others,
<temporalData> and <references>, used to list the dates of all the
events affecting a document, and the references to the IRIs of all the
documents generating these events. Each reference is provided with a required
identifier, which is used by the event list to specify which document is
responsible for which events. These elements must appear in all documents that
have undergone two or more events (e.g., all acts except the ones that still
have no amendments).
Documents in Akoma Ntoso are organized in three main
categories, as specified in the @contains
attribute of the document type element:
§
originalVersion: this value reflects the fact that the
content on the document is exactly the content that has been formally and
explicitly approved by the relevant authority, with no amendments applied.
§
singleVersion: this value reflects the fact that the
content of the document is an editorially modified version of the original
document, according to one or more subsequent amendment documents. These
amendment documents and the enactment dates of the amendments must be
all mentioned in the <lifecycle>
element. Individual additions and deletions are not marked in the content.
§
multipleVersions: this value reflects the fact that the
content of the document is the juxtaposition of fragments belonging to two or
more different versions of the same document, each fragment marked as belonging
to one or many of these versions. Thus, in a multipleVersions act
there could be two or more copies of section 2, each associated to the date it
started enactment and ended enactment.
The <lifecycle> element is a
required element for all singleVersion and multipleVersion
documents, and must be complete up to the enactment date of the latest document
referenced in the <lifecycle> element (i.e.,
there can potentially exist subsequent amendments not included, but all
amendments preceding the document’s date must be correctly listed and
referenced, even if they play no part in the displayed content). OriginalVersion
documents need not have the <lifecycle> element,
but surely can have it if the editors decide so.
In case a multipleVersions
document is being generated, each element and text fragment may be associated
with an enactment specification through the means of the five attributes: @start, @end (for validity), @startEfficacy, @endEfficacy (for efficacy) and @status.
Each fragment (a whole element if appropriate, otherwise a newly inserted <span>
or <inline>
element for text fragments for which no exact containing element exists) must
use these attribute to specify its nature.
The @start
and @end attributes (and
similarly the @startEfficacy and @endEfficacy
attributes) contain a reference to the ID of the event that has marked the
beginning or the end of the enactment (or of the efficacy) of the fragment. A @start
attribute with no @end
attribute marks a fragment that has appeared in an amendment and still exists
in the latest recorded version of the document. An @end
attribute with no @start attribute mark a fragment
that was part of the original document but has been repealed before or at the
latest recorded version of the document. The @status attribute records the type
of amendment of the fragment. The value “omissis”
can only be used by non-authoritative publications that need to display only
part of the whole document: when status="omissis",
the structure must be complete as if all contents are present, but unrequired
parts of the actual content may be removed. Similarly, the value “editorial” can be used to
add fragments of text of an editorial nature (i.e., that are generated by editors
rather than authors). Examples include annotations and translated sentences.
For instance:
|
<span xml:lang="eng"
status="editorial">
|
<p
xml:lang="afr" eId="p_123">Partye wat deel wil vorm
van die proses van regering, is vol verligting. "Sien,'' sˆ die Nuwe NP,
"die ANC is nie magshonger nie!'' Ryke ironie, komende van waar die Nuwe
NP sit. <span xml:lang="eng" status="editorial">(Translation
of Afrikaans paragraph follows.)</span></p>
<p
xml:lang="eng" status="editorial" refersTo="p_123">[Parties
who want to form part of government are quite relieved. "You see'', says
the New NP, "the ANC is not power-hungry!'' Such irony, if one considers
where the New NP is sitting.]</p>
|
The part of the provision that includes the quoted text is
wrapped with <quotedText>
or <quotedStructure>
elements depending if the modification affects a portion of paragraph
(<quotedText) or a structured hierarchy (<quotedStrcture>).
Sometime the quoted text portion is not clearly
understandable because the quoted character is missing or simply this character
is repeated in each paragraph. It is the case of the US Amending acts. For this
purpose, we use the attribute @inlineQuote.
@inlineQuote is used for marking
the character showing continuation of a quote e.g. at the beginning of each
page or at the beginning of each line of the quote.
|
(a) DEFINITION OF DISABILITY.—Section 3 of the Americans
with Disabilities Act of 1990 (42 U.S.C. 12102) is amended to
read as follows:
‘‘SEC. 3. DEFINITION OF DISABILITY.
‘‘As used in this Act:
‘‘(1) DISABILITY.—The term ‘disability’ means, with respect
to an individual—
‘‘(A) a physical or mental impairment that substantially
limits one or more major life activities of such individual;
|
<point
eId="point_a">
<num>(a)</num>
<content>
<p>DEFINITION OF DISABILITY.—Section 3 of the
Americans <eol/>
with Disabilities Act of 1990 (42 U.S.C. 12102) is amended to <eol/>
read as follows:</p>
<p><mod eId="point_a__mod_1">‘‘
<quotedStructure inlineQuote="‘‘">
<section eId="point_a__mod_1__sec_3">
<num>SEC. 3.</num>
<heading>DEFINITION OF DISABILITY.</heading>
<list eId="point_a__mod_1__sec_3__list_1">
<intro eId="point_a__mod_1__sec_3__list_1__intro">
<p>As used in this Act:</p>
</intro>
<point eId="point_a__mod_1__sec_3__list_1__point_1">
<num>(1)</num>
<heading> DISABILITY.</heading>
<list>
<intro eId="point_a__mod_1__sec_3__list_1__point_1__list_1__intro">
<p>—The term ‘disability’ means, with respect<eol/>
to an individual—</p>
</intro>
<point eId="point_a__mod_1__sec_3__list_1__point_1__list_1__point_A">
<num>(A)</num>
<content>
<p> physical or mental impairment that
substantially<eol/>
limits one or more major life activities of such individual;</p>
</content>
</point>
</list>
</point>
</list>
</section>
</quotedStructure></mod></p>
</content>
</point>
|
Documents make references to external entities that need to
be identified with clarity and no ambiguity. The current release of Akoma Ntoso
includes a section where references to external concepts, people and places are
specified. These include references to other Akoma Ntoso documents, to other
non-Akoma Ntoso documents that are accessible through the net, or to individual
instances of classes specified in a local ontology.
All references to external concepts share the same
structure, in that they are empty elements in the references section provided with exactly four
attributes:
§
href:
the IRI reference describing the entity being referred to. This can be a whole
document (for instance, the act containing amendments to the current document),
or a fragment of a document (for instance, the identifier of the unique record
identifying precisely the person being referred to in the document).
§
id:
this is the string that identifies within the document the entity being
described. All internal references will thus use this id. For instance, every event in the document
lifecycle has a source
attribute containing a reference to the id
of the document affecting or being affected by the document.
§
showAs:
this is the string that can and must be used in displaying information about
this entity. For instance, this attribute contains the name of the speaker as
it must be displayed.
§
shortForm:
this optional attribute contains a secondary form of the display information of
the entity. For instance, in some reports it is necessary to provide the full
name of a person at the first utterance, and only the name in any further utterance
from the same person.
Akoma Ntoso provides a series of mechanisms for referring to
precise concepts in the documents being marked up. Regardless of whether the
textual content of the document is sufficiently explicit and unambiguous, the
marker of the document may and should provide additional disambiguating
information about individual pieces of fragment denoting precise concepts
through the aid of the appropriate attributes.
This disambiguation happens systematically as a two-step
process: first of all, a mention to the ontological concept is added to the references section and
provided with an id,
and then one or more attributes in the document elements are used to refer to
it.
For instance, every individual in a debate is associated via
the id to an
element TLCPerson in
the references
section: the by
attribute of the speech
element indicates the speaker (this must be a TLCperson), the as attribute specifies the role of the speaker
(which must ne a, if any (and it must be a TLCrole)
and the to
attribute indicates the addressee (this can either be a person or a role).
The following are the attributes used for this purpose:
§
refersTo:
points to any instance of a Top Level Class of the ontology. It is used to
notify the reader in a generic way to what specific concept is the element
referring to.
§
href:
contains the IRI of a instance of an FRBR document class or of a web page.
Furthermore, it signals the application that the reference must be considered
navigable, i.e., activatable by the user (e.g. via a link).
§
upTo:
for range references (e.g., rref
and rmod) this
specifies the IRI of the last, or highest, element of the range being referred
to.
§
by:
points to a person, i.e., an instance of the class TLCPerson in the references
section, relative to the person by which the content has been provided.
§
as:
points to a role, i.e., an instance of the class TLCRole in the references,
relative to the role held by the person when uttering the content.
§
to: points either to a role, a person or an
organization, relative to the kind of addressee of the content being provided.
Thus, any fragment in the text content of the document
referring to Events, Concepts, or other instances of the Top Level Classes need
to use the refersTo
attribute to point to the id
of the corresponding element in the references
section.
A few elements can be considered of some use:
§
The element entity
provides a standard mechanism to refer to mentions of instances of Top Level
Classes in the content of the document. Any instance of any class can be
referred to via an instance element.
§
ref, mref, and rref provide a mechanism to refer to other documents
in the Akoma Ntoso domain. These elements may use the refersTo attribute, but will
most frequently directly use the href
attribute to specify a navigable reference to the document they refer to. The
element ref
specifies a single reference, the element mref
a group of references (a list of individual ref
elements must be placed inside the mref
element, one for each reference) and the rref
element specifies a range of references delimited by the href and upTo attributes.
§
mod, mmod and
rmod
provide a mechanism to specify modifications to other documents. The mod
element contains one ref element identifying the destination of the
modification, and may contain as many quotedStructure and quotedText elements
as needed providing the textual modification (if any) in terms of either whole
structures or individual words. The element mod
specifies a single modification, the element mmod
a group of modifications (a list of individual mod elements must be placed inside the mmod element, one for each
modification) and the rmod
element specifies a range of modifications delimited by the href and upTo attributes.
|
mod
|
(3) In subsection (4) of that section, after “that person” insert
“(whether or not the person is in the United Kingdom)”.
<subsection
eId="sec_4__subsec_3">
<num>3</num>
<content>
<p>
<mod eId="sec_4__subsec_3__mod_1">In
<ref eId="ref_4"
href="/akn/uk/act/2000-07-28/!chapter23~sec_11__subsec_4">subsection
(4)</ref> of that section, after <quotedText
eId="sec_4__subsec_3__mod_1__qtext_1"
startQuote="“"
endQuote="“">that
person</quotedText> insert “<quotedText
eId="sec_4__subsec_3__mod_1__qtext_2">(whether
or not the person is in the United Kingdom)</quotedText>”.</mod>
</p>
</content>
</subsection>
|
include the attribute
@for in order to connect the
modification portion of the text with the related reference in another part of
the text.
|
@for
|
<subsection eId="sec_4__subsec_2">
<num>2</num>
<content>
<p>In <ref eId="ref_2"
href="/akn/uk/act/2000-07-28/!chapter23~sec_11__subsec_2">section 11 (implementation of interception
warrants), after subsection (2)</ref>
insert—</p>
<p
class="BlockAmendment">
<mod eId="sec_4__subsec_2__mod_1" for="#ref_2">
<quotedStructure eId="sec_4__subsec_2__mod_1__qstr_1" class="primary main"
startQuote="“" endQuote="”">
<subsection eId="sec_4__subsec_2__mod_1mod_1__qstr_1__subsec_2A">
<num>2A</num>
<content>
<p>A copy of a warrant may be served under
subsection (2) on a person outside the United Kingdom (and may relate to
conduct outside the United Kingdom).</p></content>
</subsection>
</quotedStructure>
</mod>
</p>
</content>
</subsection>
|
Another important situation where we use a combination of
metadata and semantic annotation in the content is the relationship of a
normative citation to a legal source using multiple naming convention (both
functionally equivalent and non-equivalent). If implementers want to use
multiple citation schemes in parallel, they can use the following markup
method, here exemplified with the Akoma Ntoso naming convention. :
|
<content>
<p><ref eId="ref_13"
href="/akn/uk/act/2000-07-28/chapter23/!main#sec_58">Section 58
of the Regulation of Investigatory Powers Act 2000
</ref>(reports by the Interception of Communications Commissioner) is
amended as follows.</p>
</content>
|
|
<analysis
source="#palmirani">
<otherReferences
source="#FV">
<alternativeReference
for="#ref_13" refersTo="#ELI"
href="http://www.legislation.gov.uk/id/ukpga/2000/23/section/58"/>
<implicitReference
for="#span_10" href="/akn/it/act/2014/123"/>
</otherReferences>
</analysis>
|
In the first XML snippet we have marked up the reference ref_13. In the second XML snippet we
have modelled the metadata <otherReference>using
<alternativeReference> and annotating the URI/IRI alternative syntax in
the @href attribute. Additionaly
using <implicitReference> we can express implicit reference expressed in
the @href attribute and connected with a specific location in the text linked
using @for.
Additionally the ELI/ECLI/URN:LEX reference can be assigned
to the legal source as an alias in the FRBR block as follows:
|
<FRBRWork>
<FRBRthis value="/akn/uk/act/2016-03-16/5/!main"/>
<FRBRuri
value="/akn/uk/act/2016-03-16/5"/>
<FRBRalias name="ELI" value="http://www.legislation.gov.uk/id/ukpga/2016/5/
<FRBRalias name="short title”
value=”Childcare Act 2016"/>
|
By definition, all metadata is editorial in nature, it is
not content, but statements about the content, and as such it is, in its
entirety, the responsibility of the editor who marks up the document to provide
them. So metadata are editorial additions, they are information and
values that are not in the original content of the document and that are
added to improve comprehension and classification of the document and are
essential to make a document “machine readable” since they are meant to
provide, together with the markup the understanding and legal knowledge of the
documents that “machine” can then use to “read/understand” the document.
Metadata are a way to provide an interpretation of a set of
information embedded into the document (objective interpretation) - e.g.
date of publication - or as an intellectual elaboration of the text (subjective
interpretation) - e.g. incomplete references. Even if, as a user, you will
never see any of the tags or the actual metadata section, it is important to
understand its articulation and what scope it serves so that its role can
better be appreciated.
At the metadata level Akoma Ntoso provides the
necessary mechanisms for annotating the text with enriched data collected in;
a separate block (metadata section) or
in place in the text (inline elements).
The Akoma Ntoso metadata section provides a separate place
for enriching a document with metadata, a place that is clearly identified as
such and is dated and authored differently than the content of the text itself.
The metadata elements of Akoma Ntoso are organized in a
block called <meta> and
inside we find few main sections:
|
identification:
|
containing
all relevant facts about document, dates and authors.
This
block also includes translation information when the document is derived by
other languages and properties such as the prescriptiveness of the document
and the authoritativeness.
|
|
publication:
|
publication
metadata
|
|
classification:
|
keyword
classification
|
|
lifecycle:
|
list
of the events that modify the document.
|
|
workflow:
|
list
of the procedural steps necessary for delivery of the document or that have
some role in the legislative process.
|
|
analysis:
|
list
of the qualification of the provisions and assertions on the text.
|
|
temporalData
|
list
of temporal parameters as a set of events (e.g. time intervals of enter into
force and time of efficacy).
|
|
references:
|
list
of the external resources connected with the document as well as of all
individuals, organizations, and concepts that are relevant to understanding
the content and the history of the document.
|
|
notes:
|
annotations
inserted by the editor or by the author to explain and detail the text
content of the document
|
|
proprietary:
|
local
and proprietary metadata
|
|
presentation
|
specifications
of metadata useful for assisting with the document rendering.
|
Akoma Ntoso, unlike everyday language, describes documents
according to the Functional Requirements for Bibliographic Records (FRBR)
model, a standard nomenclature by IFLA (International Federation of
Bibliographic Associations). FRBR is a conceptual entity-relationship model
that relates user tasks of retrieval and access in online library catalogues
and bibliographic databases from a user’s perspective. It represents a more
holistic approach to retrieval and access as the relationships between the
entities provide links to navigate through the hierarchy of relationships.
Since the most important concepts in Akoma Ntoso are
connected to documents, the main part of this section is devoted to detailing
the URIs/IRIs of document-related concepts, and in particular Works,
Expressions, and Manifestations. Items are, by definition, outside of the scope
of this standard, and are only briefly described. The final part of the section
provides a URI-based naming mechanism for non-document entities (as well as for
document entities when they are handled in a similar way to non-document
entities).
All documents at all levels can be composed of sub-elements,
that when combined form the whole document. These are called components and
abstractly represent the notion that several independent subdocuments form the
whole document as it appears to the reader (i.e., a main body possibly followed
by a number of attachments such as schedules and tables):
WorkComponents (e.g., main, schedule, table, etc) - the
WorkComponents are abstract entities that can be referenced to refer to
different ExpressionComponents in time.
ExpressionComponent (e.g., main, schedule, table, etc.) -
the ExpressionComponents represent the visible division of the document as
generated by the content author (Parliament, etc.)
ManifestationComponent (e.g., xml files, PDF files, TIFF
images, etc.) - the ManifestationComponents represent the division of the
document as generated by the manifestation author (e.g., the XML editor).
ItemComponent - the actual files corresponding to the
ManifestationComponents.
Other concepts dealt by the Akoma Ntoso informal ontology
also derive from the IFLA FRBR ontology, and include but are not limited to
individuals (Person), organizations (Corporate Body), actions and occurrences
(Event), locations (Place), ideas (Concept) and physical objects (Object). The
full list of such concepts is provided in section 4.11.1 of the Akoma Ntoso Naming
Convention Version 1.0.
The scope of the naming convention is to identify in a
unique way all Akoma Ntoso concepts and resources on the network and in general
all collections thereof. Some principles and characteristics should be
respected in the naming convention:
·
MEANINGFULNESS: the name is a meaningful and logical description
of the resource and not of its physical path
·
PERMANENCE: the name must be permanent and stable over time
·
INVARIANCE: the name must derive from invariant properties of the
resource so as to provide some degree of certainty in obtaining the same name
for the same resource regardless of process, tool and person.
·
FRBR concepts are used differently when taking about documents in
a variety of situations. In each cases it is important to use the URI/IRI for
the correct FRBR level of document. We describe here a few particularly
frequent situations:
1. Legislative references will most
probably refer to WORKs: acts referring to other acts do so regardless of the
actual version, and references must be to something independent of all possible
expressions, e.g., to the work.
2. The list of attachments and
schedules belong to a specific EXPRESSION, so references to
ExpressionComponents is specific of the expression level.
3. Yet the specific Manifestation
that is the Akoma Ntoso XML format uses an XML-based syntax to refer to
ExpressionComponents, and associate them to the corresponding
ManifestationComponents containing the appropriate content. Therefore, within
XML files the URI/IRI of the Manifestation must be used to refer to all
components, including the main document, all attachments and all schedules.
4. Multimedia fragments within an
XML manifestation (e.g., a drawing, a schema, a map, etc.) do not exist as
independent ExpressionComponents, as they are only a part of some
ExpressionComponents (even when they are the only part). In fact, they are only
ManifestationComponents, and as such are referred to in object and img elements
with the appropriate ManifestationComponents URI/IRI. Even if the same
multimedia content appears in different parts of the content of a
Manifestation, each instance of that content must correspond to a different
ManifestationComponent, and must be considered independently of the other.
5. It is an Item-level decision,
once ascertained that the content is exactly identical, to provide space-saving
policies by storing only one copy of the multimedia content. This Item-level
decision has no impact on references and names, which are still individually
different from each other.
6. Non-document concepts are
referred to within the metadata and content of Akoma Ntoso documents.
References are always performed in two steps: the first step ties the reference
point in the document to an item in the Reference section using internal (and
not standardized) IDs; the second step ties the item in the reference section
to the actual concept through the URI/IRI of the concept as specified in this
document.
The FRBR model offers an excellent framework to deal with
legal texts. In legal domain, we’ve a lot of derivations due to the constant
amendments of normative acts.
FRBR identifies four different abstractions about documents
that are carefully and clearly differentiated and that relate to each other:
|
|
Bibliographical
context
|
Legal
Context
|
|
work
|
“Work”
is a distinct intellectual or artistic creation at the conceptual level.
Qualifying
characteristics: identity
e.g.
Hamlet = work
Regardless
of versions, variants, revisions, data formats and location. Even if a “Work”
is translated in different languages that have no words in common with the
original, it is still the same document, the same “work”.
|
“Work”
refers to the original “content” of the legal document.
For
examples, the abstract concept of the legal resource;
e.g.
act 3 of 2005)
|
|
expression
|
“Expression”
is the specific intellectual or artistic form that a work takes each time it
is ‘realized.
Qualifying
characteristics: content
e.g.
Hamlet original version book = expression or Hamlet original
version video = expression
All
different editions of the same version of the document, all the different
data format in which the content of a document can be expressed, all are
unified by the fact that they express the same actual content.
|
“Expression”
refers to “form” of the legal document.
For
examples, any version of the “work” whose content is specified and different
from others for any reason: language, versions, etc.;
e.g.
act 3 of 2005 as in the version following the amendments entered into force
on July 3rd, 2006
|
|
manifestation
|
“Manifestation”
is the physical embodiment of an “expression” of a “work”. It is a specific
form that the document assumes once it takes a concrete representation.
Qualifying
characteristics: data format
e.g.
Hamlet original version book – hardback version
or
Hamlet original version video DVD version
For
physical documents, it could be a specific edition as published in a specific
choice of paper, binding, typographical characteristics, etc. For electronic
documents, it is the choice of a specific data format, process method, and so
on.
|
“Manifestation”
refers to the realization of the
publishing
work either on paper or in any electronic format.
For
examples, any electronic or physical format of the “expression” MS Word, Open
Office, XML, TIFF, PDF, etc.;
e.g.
PDF version of act 3 of 2005 as in the version following the amendments
entered into force on July 3rd, 2006.
|
|
item
|
“Item”
is one physical copy of a document in a concrete form of a “manifestation” of
an “expression” of a “work”.
Qualifying
characteristics: location
e.g.
Hamlet original version book – hardback version of the Shakespeare
Library, London
It
could be an individual volume in a bookshelf, or a specific file in a
specific directory of a specific computer.
Qualifying
Characteristic: positions or address
|
“Item”
refers to a univocally identified exemplar of a certain manifestation.
For
examples, the physical copy of any manifestation in the form of a file stored
somewhere in some computer on the net or disconnected;
e.g.
the file called act32005.pdf on my computer containing a PDF representation
of act 3, 2005
|
Akoma Ntoso makes careful use of the FRBR hierarchy of
document definitions: a legal document (such as an act), which may assume
different content after being revised and amended throughout its useful life,
is nonetheless a single work - which gets multiple expressions whenever some
specific content is generated (for instance, through an amendment). Each of
these expressions has the chance of then being expressed in some electronic
form (as a PDF document, or an HTML document, or, in our case, as a specific
XML document using vocabulary and grammar from the Akoma Ntoso markup language)
thereby generating at least one manifestation. Each physical file where the
manifestation is located is therefore an item.
Besides the FRBR levels, an identifier must conform to the
URI/IRI syntax and the Akoma Ntoso Naming Convention. While defining a URI/IRI
it is important to define
1. the country,
2. the type of the
document,
3. the date of the
document and, where applicable, also the version,
4. the main language, and
also
5. the different parts
like annexes, exhibits, table, etc.
In fact, all documents at all levels of the FRBR
classification be composed of sub-elements, that when combined form the whole
document. These are called components, they abstractly represent the notion
that several independent subdocuments form the whole document as it appears to
the reader (i.e., a main body possibly followed by a number of attachments such
as schedules and tables).
It is important, during the URI/IRI identification, to
analyse the structure of the parts of a document in order to separate the
logical organization coming from the author (parliament, judge) from the
physical organization of the content usually decided by some technical criteria.
In other words, the work URI/IRI should reflect the original logical structure
as organized by the author for preserving over time the original forms and
hierarchy of the annexes or of the other material composing the full document.
The physical organization can follow different criteria connected to the
application purposes or technical choices. So we can find in the URI/IRI of the
Work three components but in the Manifestation we can find a unique URI/IRI
component for managing document in any easier way.
The Akoma Ntoso language allows names for documents that are
free of restrictions and can be used everywhere (except in the markup of
references) instead of the corresponding URIs/IRIs. If desired, these names can
be specified to record “well-known” natural language names for the document, as
well as shortened names or even acronyms commonly used to refer to a document,
as in the example below.
|
identification
|
<identification
source="#oasis">
|
|
Work
Act
n. 10 of 22 November 2011.
It
is created on the same date by the parliament (author)
The
Work is composed by two parts: main document and one annex. ComponentInfo
details the composition of the package.
|
<FRBRWork>
<FRBRthis
value="/akn/un/act/2011-11-22/10/!main"/>
<FRBRuri
value="/akn/un/act/2011-11-22/10"/>
<FRBRalias name=”long name”
value=”Business Development Act no.10 of 22 November 2011”/>
<FRBRdate date="2011-11-22"
name="Generation"/>
<FRBRauthor
href="#parliament" as="#author"/>
<componentInfo>
<componentData eId="wmain" href="#emain"
name="main"
showAs="Main document"/>
<componentData eId="wannex" href="#eannex"
name="annex"
showAs="Provisions as to the conduct of business of the
board"/>
</componentInfo>
<FRBRcountry
value="us"/>
<FRBRnumber
value="395-2010"/>
<FRBRname
value="bill"/>
<FRBRprescriptive
value="true"/>
<FRBRauthoritative
value="true"/>
</FRBRWork>
|
|
Expression
Version
in force at 19 December 2013.
The
date is the date of the expression.
The
author is the parliament. This means version officially approved.
|
<FRBRExpression>
<FRBRthis
value="/akn/un/act/2011-11-22/10/eng@2013-12-19/!main"/>
<FRBRuri
value="/akn/un/act/2011-11-22/10/eng@2013-12-19"/>
<FRBRdate date="2013-12-19" name="Generation"/>
<FRBRauthor href="#palmirani" as="#editor"/>
<componentInfo>
<componentData eId="emain" href="#mmain"
name="main"
showAs="Main document"/>
<componentData eId="eannex" href="#mannex"
name="schedule"
showAs="Provisions as to the conduct of business of the
board"/>
</componentInfo>
<FRBRauthoritative value="true"/>
<FRBRlanguage language="eng"/>
</FRBRExpression>
|
|
Manifestation
The
date of creation is when the editor marks up the document: 2016-01-30.
|
<FRBRManifestation>
<FRBRthis value="/akn/un/act/2011-11-22/10/eng@2013-12-19/!main.xml"/>
<FRBRuri
value="/akn/un/act/2011-11-22/10/eng@2013-12-19.akn"/>
<FRBRdate date="2016-01-30"
name="Generation"/>
<FRBRauthor href="#palmirani"
as="#editor"/>
<FRBRauthor href="#vitali"
as="#editor"/>
<componentInfo>
<componentData eId="mmain"
href="main.xml" name="main"
showAs="Main document"/>
<componentData eId="mannex"
href="annex.xml"
name="annex" showAs="Provisions as to the conduct of
business of the board"/>
</componentInfo>
<FRBRformat value="xml"/>
</FRBRManifestation>
|
|
|
|
The expression also includes metadata for capturing the
linguistic aspects. In particular, FRBRlanguage and FRBRtranslation permit to creating a relationship among
expressions that are the outcome of a translation process. The following
example shows that the current document is a translation made by the Paliament
(by) from Swahili (fromLanguage), to English (FRBRlanguage), passing through
French (pivot).
<FRBRlanguage
language="eng"/>
<FRBRtranslation href="/akn/ke/act/1997-08-22/3/swa@"
fromLanguage="swa" by="ˆparliament"
pivot="fra"/>
|
It
is possible in some particular situations (e.g., internal legal drafting) to not
have the version date, but rather a version number. In order to capture this
number we can use the element <FRBRversionNumber>
|
<FRBRExpression>
<FRBRthis value="/akn/un/doc/2015-11-22/10/eng@v_3/!main"/>
<FRBRuri
value="/akn/un/ doc/2015-11-22/10/eng@v_3"/>
<FRBRdate
date="2015-11-22" name="Generation"/>
<FRBRauthor href="#palmirani" as="#editor"/>
<FRBRversionNumber value="3"/>
<FRBRlanguage
language="eng"/>
|
The element preservation is the FRBR metadata property
containing an arbitrary list of elements detailing the preservation actions
taken for the document is the respective level of the FRBR hierarchy. It is
fundamental for permitting to understand at each level (work, expression,
manifestation). The example below shows the Public Law 112-61
of US Government Printing Office package in MODS
representation embedded inside of the Akoma Ntoso FRBRManifestation block.
|
<FRBRManifestation>
<FRBRthis
value="/akn/us/act/2011-11-29/112-61/eng@/main.xml"/>
<FRBRuri value="/akn/us/act/2011-11-29/112-61/eng@.akn"/>
<FRBRdate
date="2012-05-09" name="Generation"/>
<FRBRauthor
href="#palmirani" as="#editor"/>
<preservation
xmlns:my="http://my">
<my:mods ID="P0b002ee183eb812a"
version="3.3" xsi:schemaLocation="http://www.loc.gov/mods/v3
http://www.loc.gov/standards/mods/v3/mods-3-3.xsd"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.loc.gov/mods/v3">
<my:name
type="corporate">
<namePart>United
States Government Printing Office</namePart>
</my:name>
<my:name
type="corporate">
<my:namePart>United
States</namePart>
<my:namePart> National Archives and
Records Administration</namePart> <my:namePart> Office of the Federal
Register</namePart>
<my:description>Government
Organization</description>
</my:name>
<my:typeOfResource>text</typeOfResource>
<my:genre
authority="marcgt">government publication</genre>
<my:titleInfo type=”alternative”>
<my:title>An act to facilitate the
hosting in the United States of the 34th America's Cup by authorizing certain
eligible vessels to participate in activities related to the competition, and
for other purposes</title>
</my:titleInfo>
<my: titleInfo type=”alternative”>
<my:title>America's Cup Act of 2011</title>
</my:titleInfo>
<my:titleInfo>
<my:title>Public Law 112-61</title>
</my:titleInfo> <my:physicalDescription>
<my:note
type="source content type">deposited</note>
<my:digitalOrigin>born
digital</digitalOrigin>
<my:extent>3
p.</extent>
</my:physicalDescription>
</my:mods>
</my:preservation>
</FRBRManifestation>
|
The publication is a part of the meta block and captures the
metadata concerning the official publication process. The name of the source
(Official Journal), the date (in normal format), the label for the presentation
(showAs), the number of the source of publication (number). The publication is
mandatory for the act type but not for the bill type of document.
|
publication
|
<publication name="Official Journal"
date="1980-01-01" showAs="Official Journal of UN"
number="234"/>
|
The classification section is dedicated to assigning
keywords to the document or fragment of the document, on the base of the topic
treated in the legal content. The content of the keyword is stored in the
attribute value, the dictionary attribute stores the name of the vocabulary
used. It is possible to use a different vocabulary and to use href for
connecting the keyword to the external ontology. The kewords are connected with
the text using @refersTo value
(e.g., "#k_ familyLaw") and the element <term>. Keyword can be connected using @refersTo value with TLC <references> part.
|
classification
|
<classification
source="#oasis">
<keyword eId="k_humanRight" value="humanRight"
showAs="Human Right" dictionary="EuroVOC"
href="/EuroVoc/Law/ humanRight" refersTo=”#TLCConcept_humanRight”/>
<keyword eId="k_ familyLaw" value="familyLaw"
showAs="Family Law" dictionary="EuroVOC"
href="/EuroVoc/Law/familyLaw" refersTo=”#TLCConcept_familyLaw”/>
</classification>
<p>The
<term refersTo="#k_ familyLaw">Family Law</term> is
applied
to the following situations</p>
|
|
|
<term refersTo="#copyright">license</term>
<keyword value="copyright "
dictionary="http://sinatra.cirsfid.unibo.it/rdf/IPR/ copyright " refersTo="#IPR"/>
<TLCConcept
href="/ontology/concept/ipr" eId="IPR" showAs="IPR
"/>
|
The lifecycle lists all the events that are involved within
the chain of modifications of the document. These events modify the expression.
|
lifecycle
|
<lifecycle
source="#oasis">
<eventRef
eId="eventRef_1" date="1997-08-29" source="#ro_1"
type="generation"/>
<eventRef
eId="eventRef_2" date="2003-12-19" source="#rp_1"
type="amendment"/>
</lifecycle>
|
The workflow blocks list the events that are involved with
the legislative or judiciary or parliament process. A workflow step does not
necessarily change the expression. However, when a new expression occurs, we
record all the workflow steps connected to it. The following example lists
three workflow steps: firstReading, secondReading, thirdReading. In this case,
the firstReading did not modify the expression. The secondReading and the
thirdReading are connected to their correspondent expression by href (uk/bill/1345/eng@2004-12-15–
bill URI). We notice that the proprietary tags include local specifications
that support the workflow management system import/export of the data.
|
workflow
|
<workflow source="#editor">
<step date="2005-01-01"
as="#legislator" href="/uk/bill/1345/eng@2004-12-15"
eId="step_1" outcome="#firstReading"
by="#parliament">
<myTags:proprietary
xmlns:myTags="http://myTags.xsd" source="#editor">
<myWorkFlowTags />
</myTags:proprietary>
</step>
<step date="2005-04-01"
as="#legislator" href="/uk/bill/1345/eng@2005-04-01/main"
eId="step_2" outcome="#secondReading"
by="#parliament" />
</workflow>
|
The block Analysis includes all the
juridical metadata coming from a specific interpretation of the legal source. The
Analysis block describes information concerning modifications, restrictions of
the normative effects e.g. by jurisdiction limitation, judgment result,
qualification of the judgment’s citations, parliamentary voting, mapping
history concerning the original wId and the current eId.
|
activeModifications:
|
Block
of metadata for managing the modifications made by the current document to
another document.
|
|
passiveModifications:
|
Block of metadata for managing the modifications arrived
to the current document.
|
|
restrictions:
|
Block of metadata for managing the limitation of the
normative effect, in particular this block permits defining the jurisdiction
restrictions.
|
|
judicial:
|
Block
of metadata for managing the judiciary metadata such as the qualification of
the case-law references and the result of the decision.
|
|
parliamentary:
|
Block
of metadata for managing the parliamentary metadata such as the quorum
information, the voting results, and the recall data.
|
|
mappings:
|
Block
of metadata for managing the changes of ids when a renumbering occurs and also
whenever this expression is not the master expression of the document (e.g.
linguistic variants with different numbering of the partitions imposed by the
translation process).
|
|
otherReferences
|
Used
to specify a number of <otherRef> elements that are
meant to specify implicit references associated with fragments of the
document (identified through a source element).
|
|
otherAnalysis
|
Any
other proprietary metadata.
|
In all of the
document types it is possible to model the modificatory
provisions. Especially in the amendment (official document for proposing
modifications to a bill), bill, act, debate (e.g. oral amendment) and doc (e.g.
veto of the executive) the modificatory provision is a legal normative
statement that disposes modifications to another legal document. In the legal
text we model the textual elements (e.g. quotedText, quotedStructure, ref,
etc.) and in the meta block activeModification we provide the semantic
information like: source of modification, destination of the modification,
position where to apply the modification in the destination, action of the
modification, temporal parameters, conditions or limitation of the
modification, other peculiar parameters for managing special modifications
(e.g. renumbering).
The following table provides some examples
of textual modifications: repeal, substitution, insertion, split, join, renumbering.
<textualMod>: it provides the type of modification to
apply. The attribute @incomplete permits specifying the
incompleteness of the information for applying in an automatic
manner the modification action (e.g. lack of precision concerning the destination).
The attribute @exclusion (values true or false) is a boolean data that
indicates that exists exception avoiding an automatic consolidation.
<source>: it provides the reference to the fragment
or portion of the legal text where the modification is expressed;
<destination>: it provides the IRI where the modification
should be applied. @pos in the destination element permits specifying some information concerning the precise location where to apply the
modification: after, before, end, start, inside, unspecified.
<old>: it provides the reference to the quotedText or
quotedStructure where to find the old text that should be modified
<new>: it provides the reference to the quotedText or quotedStructure
where to find the new text involved in the modifications;
<previous>: it provides the
reference to the eId of the element affected by renumbering as located in the
structure in the previous version/expression.
|
repeal
|
<textualMod
type="repeal" eId="textualMod_1"
incomplete="true" exclusion="true">
<source href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18 #art_16"/>
<old
href="#mod_1__qtext_1"/>
</textualMod>
The previous XML
fragment means: in the bill n. 1055, at 2008-02-25 article 16, it is repealed
the word “male” (referenced to the text pointed out by the element
<old>) but there are exceptions (the exception is expressed in the
@exclusion=”true” and so also the @incomplete=”true”).
|
|
substitution
|
<textualMod
type="substitution" eId="activeModifications__textualMod_2">
<source
href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18~art_16"/>
<old
href="#mod_1__qstr_1"/>
<new href="#mod_1__qstr_2"/>
</textualMod>
The previous XML
fragment means: in the bill n. 1055, at 2008-02-25, art. 16, the old text
specified in mod_1_qstr_1 is substituted by the text defined in the
mod_1__qstr_2.
|
|
insertion
|
<textualMod
type="insertion" eId="activeModifications__textualMod_3">
<source
href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/!main~art_16"
pos="before"/>
<old
href="#mod_1__qtext_1"/>
<new
href="#mod_1__qtext_2"/>
</textualMod>
The previous XML
fragment means: Insert the new text contained in mod_1__qtext_2 in the art.
16 before the text specified by the href attribute of <old>
<textualMod
type="insertion" eId="activeModifications__textualMod_3">
<source
href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/!main~art_16"
pos="before"/>
<new
href="#mod_1__qstr_1"/>
</textualMod>
The previous XML
fragment means: insert a new structure (mod_1__qstr_1) before the art. 16.
|
|
join
|
<textualMod
type="join" eId="activeModifications__textualMod_4">
<source href="#mod_1"/>
<destination
href="/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/~art_16__para_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/~art_16__para_2"/>
<new
href="#mod_1__qstr_2"/>
</textualMod>
The previous XML
fragment means: take the paragraph 1 and the paragraph 2 of the art. 16 and
join in the unique element as defined in “new”.. For example “new” can
contain the number of the new joined partition.
|
|
split
|
<textualMod
type="split" eId="activeModifications__textualMod_5">
<source
href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/~art_16__para_1"/>
<new
href="#mod_1__qstr_2"/>
</textualMod>
The previous XML
fragment means: take the paragraph 1 of the art. 16 and split it following
the structure defined in “new” element. For example “new” can contain the
number of the new splitted partition.
|
|
renumbering
|
<textualMod
type="renumbering" eId="activeModifications__textualMod_6">
<source href="#mod_1"/>
<destination
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/~art_23"/>
<previous
href=“/akn/uy/bill/camera/2008-02-25/carpeta1055-2008/esp@2009-08-18/~art_16"
eId="activeModifications__textualMod_6_previous"/>
</textualMod>
The previous XML
fragment means: renumber the art. 16 in art. 23.
|
|
|
</activeModifications>
|
The passiveModifications block records the
modifications received from other legal documents or the changes applied to the
current version of the document. The passiveModifications provides relevant
information to permit the reverse engineering of the changes applied.
|
passiveModifications
|
|
|
repeal
|
<textualMod
eId="passiveModifications__textualMod_1"
type="repeal" period="#tmpg_1">
<source
href="/akn/uy/amendment/senate/2009-09-25/34/"/>
<destination href="#art_10__para_1__list_1__point_1"/>
<old>
<uy:text>por
el incumplimiento injustificado de las contrapartidas a que refiere el
artículo 8º.</uy:text>
</old>
</textualMod>
In
this passive modification the Uruguay Parliament added a proprietary element
(uy:text) for storing the old text that is repealed in the current version of
the document.
.
|
|
substitution
|
<textualMod
eId="passiveModifications__textualMod_2"
type="substitution" period="#cmp_1__tmpg_4">
<source
href="/akn/uy/amendment/senate/2009-09-25/34/"/>
<destination
href="#cmp_1__docType_1"/>
<old>
<uy:text>TEXTO APROBADO </uy:text>
</old>
<new
href="#cmp_1__docType_1__ins_1"/>
</textualMod>
This passive
modification models the substitution of the old text in the new text, with
particular regard to the modification in the <preface> of the type of
document.
|
|
insertion
|
<textualMod
eId="passiveModifications__textualMod_3"
type="insertion" period="#tmpg_4">
<source
href="/akn/uy/amendment/senate/2009-09-25/34"/>
<destination href="#art_7__para_3"/>
</textualMod>
Insertion of the
paragraph 3 in the new versioned document.
|
|
join
|
<textualMod
eId="passiveModifications__textualMod_4"
type="join" period="#tmpg_4">
<source
href="/akn/uy/amendment/senate/2009-09-25/34"/>
<destination
href="#art_6__para_1"/>
<old
href="/uy/bill/ejecutivo/carpeta/2005-04-04/137-2005/esp@2005-05-02T24:00:00-03:00/!main~art_6__para_2"/>
<old
href="/uy/bill/ejecutivo/carpeta/2005-04-04/137-2005/esp@2005-05-02T24:00:00-03:00/!main~art_6_para_3"/>
<new
href="#art_6__del_1"/>
</textualMod>
This fragment
models the join effect on the current document.
The destination
is the current point in the text where the join was applied.
The two old
elements provide two original elements that are joined.
The new indicates
the point where was deleted the disjunction between the two elements. We use
<del/> for indicating where was applied the conjunction.
|
|
split
|
<textualMod
eId="passiveModifications__textualMod_5"
type="split" period="#tmpg_3">
<source
href="/akn/uy/amendment/senate/2009-09-25/34"/>
<destination href="#art_6__ins_1"/>
<destination
href="#art_6_ins_3"/>
<old
href="#art_6__para_1"/>
<new
href="#art_6_ins_2"/>
</textualMod>
This fragment
models the result of a split modification.
Two destinations
are pointed out to the results of the split, in this case two element
<ins> that delimitates the result of the divisions.
The old
represents the partition involved by the subdivision. The new indicates where
the split is done (art_6__ins_2).
|
|
renumbering
|
<textualMod
eId="passiveModifications__textualMod_6"
type="renumbering" period="#tmpg_3">
<source
href="/akn/uy/amendment/senate/2009-09-25/34"/>
<destination
href="#art7__para_2"/>
<previous
href=“/akn/uy/bill/ejecutivo/2005-04-04/carpeta137-2005/esp@2005-05-02/!main~art7__para_3" showAs="previous"
eId="previous_1"/>
</textualMod>
This markup shows
the effect of the renumbering on the destination document. The source says
where the renumbering come from; destination says the partition affected by
the renumbering in the current document; previous describes the previous
partition expression ID.
|
<restrictions> block contains <restriction> elements that describe
jurisdiction specifications and other types of restrictions of normative
effectively. Each restriction element associates a TLCConcept identified by a @refersTo
attribute to a fragment of the document identified by an href attribute. In the
following example we have @href attribute hosting multiple references: art. 12, art. 32, art. 56
for avoiding the redundancy. At the moment only one type of restriction is
possible, namely jurisdiction. Other types of restrictions may be specified in
future by adding values to the new type restrictionType. This can be used to
specify jurisdiction restrictions (frequent, e.g., in UK legislation) to
individual fragments of the legislation.
|
restrictions
|
<restrictions
source="#fv">
<restriction
type="jurisdiction" eId="restriction_1"
refersTo="#gb-eaw" href="#art_12"/>
<restriction
type="jurisdiction" eId="restriction_2"
refersTo="#gb-eaw" href="#art_32"/>
<restriction
type="jurisdiction" eId="restriction_3"
refersTo="#gb-eaw" href="#art_56"/>
</restrictions>
<restrictions
source="#palmirani">
<restriction
type="juridiction" eId="restriction_1"
refersTo#="#jurisdictionEnglandWales" href="#art_12/>
<restriction
type="juridiction" eId="restriction_2"
refersTo#="#jurisdictionEnglandWales" href="#art_32"/>
<restriction
type="juridiction" eId="restriction_3"
refersTo#="#jurisdictionEnglandWales" href="#art_56"/>
</restrictions>
And in the
<references> block we have also this specification:
<references source=”…”>
<TLCLocation eId="england.wales" href="..." showAs="England
and Wales" />
</references>
|
In a judgment document type it is possible
to qualify the citation made by the judge supporting his/her thesis and final
decision. In the following example, the reference ref_1 supports the judge
thesis and it is accessible in the href /it/judgment/2000/123.
The result element expresses the final
outcome of the case-law, using the attribute type (in our case approve). The
complete list of result is:
·
deny
·
dismiss
·
uphold
·
revert
·
replaceOrder
·
remit
·
decide
·
approve.
The list of the qualifications for
classifying the citations are:
·
<supports>: The element supports is a metadata element specifying a reference
to a source supported by the argument being described
·
<isAnalogTo>: The element isAnalogTo is a metadata
element specifying a reference to a source analog to the argument being
described
·
<applies>: The element applies is a metadata element
specifying a reference to a source applied by the argument being described
·
<extends>: The element extends is a metadata element specifying a reference to
a source extended by the argument being described.
·
<restricts>: The element restricts is a metadata
element specifying a reference to a source restricted by the argument being
described
·
<derogates>: The element derogates is a metadata
element specifying a reference to a source derogated by the argument being
described
·
<contrasts>: The element contrasts is a metadata
element specifying a reference to a source contrasted by the argument being
described.
·
<overrules>: The element overrules is a metadata
element specifying a reference to a source overruled by the argument being
described
·
<dissentsFrom>: The element dissentsFrom is a metadata element specifying a
reference to a source dissented from the argument being described
·
<putsInQuestion>: The element putsInQuestions is a metadata element specifying a
reference to a source questioned by the argument being described.
·
<distinguishes>: The element distinguishes is a metadata element specifying a
reference to a source being distinguished by the argument being described.
|
judicial
|
<judicial>
<result
type="approve"/>
<supports>
<source
href="#ref_1"/>
<destination
href="akn/it/judgment/2000/123"/>
</supports>
</judicial>
|
In an analysis it is possible to track the
metadata connected to the parliamentary events recorded in the debate such as
the call of quorum, recount of quorum, voting recount, voting.
The following fragment presents a simple
example where it is possible to connect the analysis annotation with the text
using href attribute and the semantic meaning of the annotation with refersTo
attribute.
For example, the voting is recorded in a
fragment of text in the debate called <summary>. Inside of the summary we have
marked up <quantity> and inside of the <voting> metadata we connect the quantities with the respective legal
meaning inside of the voting event: 72 votes are “ayes” and 34 votes are “noes”
using the @refersTo attribute connected with a TLConcept. Before the voting event the
<quorum> was checked. Because we have different graduation of quorum,
refersTo expresses the type of quorum defined in the TLConcept (e.g. majority).
After the voting a recount occurred and the positive votes are 76.
|
parliamentary
|
<parliamentary>
<quorumVerification>
<quorum
eId="quorum_1" refersTo="#majority" value="80"/>
<count
eId="count_1" refersTo="#present"
href="#quantity_1" value="110"/>
</quorumVerification>
<voting
eId="voting_1" href="#summary_1" refersTo="#voting" outcome="#approved">
<quorum
eId="voting_1__quorum_1" refersTo="#majority"
value="80"/>
<count
eId="voting_1__count_2" refersTo="#ayes"
href="#quantity_2" value="72"/>
<count
eId="voting_1__count_3" refersTo="#noes"
href="#quantity_3" value="34"/>
</voting>
<recount
eId="recount_1" href="#dbsect_2"
refersTo="#recount" outcome="#approved">
<count
eId="recount_1__count_1" refersTo="#ayes"
href="#quantity_4" value="76"/>
</recount>
</parliamentary>
--- in the text ---
<debateSection
eId=”dbsect_2” name=”…”>
<summary eId="summary_1">(Question
carried by <quantity eId="quantity_2" normalized="72"
refersTo="#ayes">72</quantity>
to <quantity normalized="34" eId ="quantity_3"
refersTo="#noes"> 34</quantity> votes)</summary>
</debateSection>
|
The mappings block records the history of
the modifications of the original id over time. <mappings> supplies a
place where to record the fact that changes in ids do not happen only when a
renumbering occurs, but also whenever this expression is not the master expression
of the document, i.e., whenever eIds and wIds diverge. The attribute @original
stores the first wId, @current stores the eId. The attributes @start and @end link
the temporal data.
|
mappings
|
<mappings
source="#palmirani">
<mapping
eId="mapping_1" original="#art_1" current="#art_4"
start="#t_1"
end="#t_3"/>
<mapping
eId="mapping_2" original="#art_1"
current="#art_7" start="#_t4" end="#t_7"/>
</mappings>
|
5.10.8 otherReferences
Sometime there is the need to annotate
implicit references that connect one part of the text with other legal sources,
including other fragments of text within the same document. For example, a
semantic implicit reference is used between the recital and the body of a
European Directive. In order to capture this relationship, we use the <otherReferences> element.Content model of <otherReferences> in the <analysis>
section of the metadata contains <implicitReference> and <alternativeReference> elements, to stress that they can be used for expressing either a
legal reference not explicitly mentioned in the text, or alternative syntaxes
for the URI specified in the actual reference.
|
otherReferences
|
<otherReferences
source="#FV-MP">
<alternativeReference
for="#ref12" refersTo="#ELI" href=" http://www.legislation.gov.uk/id/ukpga/2014/27/enacted/"/>
<implicitReference
for="#ref_10" href="/akn/uk/act/2000-07-28/chapter23/main#sec_12__subsec_7"/>
</otherReferences>
|
Sometimes there is the need to express another legal
analysis not yet included in Akoma Ntoso. Each institution can use this
container for defining this additional legal metadata. The following examples,
coming from the Library of Congress of Chile, show the metadata used for
classifying specific RDF classes.
|
otherAnalysis
|
<otherAnalysis
source="#bcnMetadata">
<bcn:MetadataBCN>
<bcn:Materia
eId="met1" refParteDocumento="#ds1-pap1-com1"
rdfLabelMateria="Renuncia"
uriMateria="/recurso/materias/renuncia"/>
<bcn:Materia
refParteDocumento="#ds1-pap2-ws5"
rdfLabelMateria="Cultura" uriMateria="/recurso/materias/cultura"/>
<bcn:Materia
refParteDocumento="#ds1-pap2-ws5"
rdfLabelMateria="Patrimonio"
uriMateria="/recurso/materias/patrimonio"/>
<bcn:TerminosLibres
refParteDocumento="#ds1-pap1-com1" valor="renuncia al cargo de
Primer Vicepresidente"/>
<bcn:TerminosLibres
refParteDocumento="#ds1-pap2-ws5" valor="petroglifos
norte"/>
<bcn:TerminosLibres
refParteDocumento="ds9-h1" valor="homenaje para EX DIPUTADO
DON FÉLIX ERNESTO IGLESIAS "/>
<bcn:AtributosDiarioSesiones
bcn:uriResultadoSesion="#Exitosa"/>
</bcn:MetadataBCN>
</otherAnalysis>
|
The temporalData describes all the events
grouped together in order to model intervals. In the following example we find
the <temporalGroup> that models the interval of enter into force and the interval of
efficacy. The @refersTo attribute connects the temporal parameters with the
TLConcept defined in the references block.
|
temporalData
|
<temporalData
source="#oasis">
<temporalGroup
eId="temporalGroup_1">
<timeInterval
refersTo="#inforce"
start="eef_1" end="eref_2"/>
<timeInterval refersTo="#efficacy"
start="#ef_1" end="#ef_2"/>
</temporalGroup>
<temporalGroup eId="temporalGroup_2">
<timeInterval refersTo="#inforce"
start="#ref_2"/>
<timeInterval refersTo="#efficacy"
start="#ref_2"/>
</temporalGroup>
</temporalData>
|
The note is a block where we record
non-authorial notes. For the authorial notes we use <authorialNote>
element which is an inline element. The authorial notes are provided by the
author of the document and it is placed in the text An example of authorial
note is the side note (approved by the Assembly) or any note of the Parliament.
The attribute @placement speficies
where to place the note (bottom,inline, left, right, side).
The attribute @marker specifies the
simple for marking the note.
The attribute @placementBase
provides a mechanism to specify exactly the placement of the note with regards
to other elements of the document using a local href (i.e. a #id reference) to
the element near which the note should be placed.
|
authorialNote
|
<paragraph><content><p><authorialNote
marker="2" placement="side"
placementBase="#sec_1__para_1"><p>this is a authorial note
approved by the Parliament</p></authorialNote>
</paragraph>
|
Any other editorial annotation is included
in the tag <note> in the <meta> block.
|
notes
|
<notes
source="#palmirani">
<note
eId="note_1">
<p> Some
footnotes from editors. Non authorial note.</p>
</note>
</notes>
|
The reference block models all the references with other
documents or with ontology classes (Top Level Classes – TLC). The active
references are the normative modifications from the current document to
external documents, while the passive references are the external documents
that point out the current document because they modify the current document.
<original>:
it is the original expression of the Work;
<activeRef>:
it is any external document that is modified by the current document;
<passiveRef>:
it is any external document that affects the current document;
<attachmentOf>:
it is the reference to the main document where the current document is the
attachment
<hasAttachment>:
it is the reference to any attachment of the current document;
<jurisprudence>:
it is any reference to relevant case-law;
<TLCreference>:
it is any reference to an ontological class;
<otherReference>:
it is an implicite reference.
|
references
|
<references
source="#palmirani">
<original
eId="original_1" href="/akn/cl/bill/2005-03-14/315-352/esp@!main"
showAs="Original "/>
<activeRef
eId ="activeRef_1" href="/akn/cl/act/2010/cp/!main~art12"
showAs="Código Penal"/>
<passiveRef
eId ="passiveRef_1" href="/akn/cl/act/2010/cp/main#art19"
showAs="Código Penal"/>
<attachmentOf
eId="attachmentOf_1" href="/akn/cl/bill/2005-03-14/315-352/esp@.akn"
showAs="Complete Collection of Gazette 2005 March"/>
<hasAttachment
eId="hasAttachment_1" href="/akn/cl/bill/2005-03-14/315-352/esp@!annex_A"
showAs="Annex A"/>
<jurisprudence
eId="jurisprudence_1" href="/akn/cl/judgment/2005-01-10/2124"
showAs="case-law"/>
<TLCOrganization
eId ="executivo" href="/akn/ontology/organizations/akn/executivo"
showAs="Executivo"/>
<TLCRole
eId ="pdlr" href="/akn/ontology/roles/akn/presidenteRepublica"
showAs="Presidente de la República"/>
<TLCRole eId
="author" href="/akn/ontology/roles/akn/author"
showAs="Author of Document"/>
<TLCRole
eId ="editor" href="/akn/ontology/roles/akn/editor"
showAs="Editor of Document"/>
<TLCPerson
eId="lagos" href="/akn/ontology/persons/akn/ricardoLagosEscobar"
showAs="RICARDO LAGOS ESCOBAR"/>
<TLCLocation
i eId="TCL" href="/akn/ontology/location/akn/santiago"
showAs="Santiago"/>
<TLCReference
eId="TLCReference_1" href="/akn/cl/doc/2004/commentOfCivilCode/"
showAs="Comment of the Civil Code of Chile" name="book"/>
</references>
|
The proprietary block allows for the
addition of any other local tags which are useful for managing legacy systems.
|
proprietary
|
<proprietary
source="#oasis">
<my:tag>
any tag useful for the local document management</my:tag>
</proprietary>
|
Akoma Ntoso makes no restriction as to the vocabulary
or containment constraints of the content within the proprietary block. The
only requirement (as shown by the compliant fragment) is that all elements
belong to namespaces different than that of Akoma Ntoso. This guarantees the
immediate identification of the new elements.
Proprietary elements can still use existing core Akoma Ntoso
attributes and, whenever possible, should.
In particular, the following attributes should be used
whenever possible:
• @eId:
an identification word unique within the whole document
• @refersTo:
the id of an ontological concept, person, organization, location etc. defined
in the reference section of the metadata.
• @href:
the address of another document, or the id of a section of the document
referenced by the individual metadata element.
• @source:
the id of a person or organization (placed in the reference section) providing
the metadata element.
|
<meta>
<identification source="#au1">
... </identification>
<publication … />
<lifecycle source="#au1">
... </lifecycle>
<analysis source="#au1"> ...
</analysis>
<references source="#au1">
... </references>
<proprietary source="#au1"
xmlns:cirsfid="http://www.cirsfid.unibo.it/proprietary">
<cirsfid:MissingInfo>
<cirsfid:mActDate>1992-12-28</cirsfid:mActDate>
</cirsfid:MissingInfo>
</proprietary>
</meta>
|
The presentation block allows for tags and
specifications that facilitate the visual rendering of the document (e.g.
specifications on the paper format, or the numbering of the lines, etc.). For
an advanced specifications see also 5.6 and 5.7.
|
presentation
|
Example from UK
<presentation
source="#palmirani">
<my:oddPageHeading>
<my:left
class="normal"> Legislation Publication
Ordinance</my:left>
<my:right
class="normal"> CAP. 614 </my:right>
</my:oddPageHeading>
<my:oddPageFooter>
<my:left
class="normal"> Authorized Loose-left and Printed and Published
</my:left>
<my:right
class="normal"> Issue 47</my:right>
</my:oddPageFooter>
</presentation>
Example from Federal
Chancellor of Switzerland:
<proprietary
source="#palmirani">
<ch:evenPageHeading>
<ch:left
class="two-third">Iniziativa popolare «Basta con la costruzione
sfrenata di abitazioni secondarie!» DF</ch:left>
<ch:right
class="one-third">RU 2012</ch:right>
</ch:evenPageHeading>
</proprietary>
|
One of the main problems in the rendering of an XML file is
preserving the format over time by providing enough information to process the
document in the future in a similar manner. In the following example we specify
the URL where to get the CSS as well as the hash code of the CSS in order to be
sure that the CSS is not modified over time.
|
presentation
|
<presentation
source="#palmirani">
<uy:myCssForRendering>http://europe.eu/akomantoso30.css</uy:myCssForPreservation>
<uy:myCssHash>d7402662a7a744c0b3689dc863e91761</uy:myCssHash>
</presentation>
|
The following Indian example shows an example where it is
necessary specific presentation instructions:
|
5[12. Cognizance and trial of offences. -- (1) No court inferior to that of a Metropolitan
Magistrate or a Judicial Magistrate of the first class
shall try any offence punishable
under this Act.
(2) No court shall take cognizance of an offence
punishable under this Act except upon—
(a) its own knowledge or upon a complaint made by the
appropriate Government or
an officer authorized by it in this behalf; or
(b) a complaint made by the person aggrieved by the
offence or by any recognized
welfare institution or organization.
Explanation. –For the
purposes of this sub-section “recognized welfare institution or
organization” means a social welfare organization or
institution recognized in this behalf
by the Central or State Government.]
5. Substituted by Act 49 of 1987, S.4.
|
The fragment of the following XML snippet shows how to
manage the situation using CSS instructions: :
|
<akomaNtoso xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0/WD16"
xmlns:x="http://www.fabioVitali.com">
<presentation
source="#FV">
<x:css>
.removed::before {
content:
"[";
}
.removed::after {
content:
"]" ;
}
noteRef {
vertical-align: super;
font-size:
80%;
}
</x:css>
</presentation>
|
This XML fragment shows the <presentation> block where
a x namespace is defined and an element <x:css> is defined for including
css presentation instructions. In particular, this fragment of css wraps the
text between two square brackets.
A table can be included in any type of document. A table
element uses the same element children of the HTML table model. It includes
also the attribute: border, width, cellpadding, cellspacing, title. Caption
element is possible and the content model of the <td>
element permits including blocks elements such as block, blockContainer,
blockList, tblock. This permits modeling particular tables, like the following
example, where the amendments are included directly in the table.
The corresponding XML code is following:
|
<table eId="table_1"
cellpadding="10" border="1" cellspacing="0"
width="100" title="LAWS AMENDED OR REPEALED" >
<caption>LAWS AMENDED OR REPEALED</caption>
<tr>
<th>
<p>No. and year of law</p>
</th>
<th>
<p>Short title</p>
</th>
<th>
<p>Extent of amendment or repeal</p>
</th>
</tr>
<tr>
<td>
<p>Act No. 153 of 1993</p>
</td>
<td>
<p>Independent Broadcasting Act,
1993</p>
</td>
<td>
<td>
<blockList
eId="table_1__list_1">
<item eId="table_1__list_1__item_1">
<num>1.</num>
<blockList
eId="table_1__list_1__item_1__list_1">
<listIntroduction
eId="table_1__list_1__item_1__list_1__intro">The amendment of
section 1 by the substitution for the definitions of ‘‘Authority’’,
‘‘chairperson’’, ‘‘Council’’ and ‘‘councillor’’ of the following definitions,
respectively:</listIntroduction>
<item
eId="table_1__list_1__item_1__list_1__item_a">
<num>(a)</num>
<p>‘‘<mod
eId="table_1__list_1__item_1__list_1__item_a__mod_1">
<quotedStructure
eId="table_1__list_1__item_1__list_1__item_a__mod_1__qstr_1">
<point
eId="table_1__list_1__item_1__list_1__item_a__mod_1__qstr_1__point_a">
<content>
<p>‘Authority’
means the Independent Communications Authority of South Africa established by
section 3 of the Independent Communications Authority of
South Africa Act, 2000;</p>
</content>
</point>
</quotedStructure>’’;</mod></p></item>
<blockList>
</item>
</blockList>
</td>
</tr>
</table>
|
Another use for the table is the application form, where
some parts are dedicated to filling parts of the form. Sometime these
application forms are schedules of law, regulations, or bills, like the
following example.
It is possible with Akoma Ntoso to capture the blank part
that permits an easy transformation of the template in an online web
application form.
|
<table eId="table_1">
<tr>
<td><p>At</p></td>
<td><p><fillin>............................</fillin></p></td>
<td><p>on this</p></td>
<td><p><fillin>............................</fillin></p></td>
<td><p>day of</p></td>
<td><p><fillin>............................</fillin></p></td>
<td><p>19</p></td>
<td><p><fillin>............................</fillin></p></td>
</tr>
<tr>
<td><p>G.H.,Magistrate.</p></td>
</tr>
</table>
|
It is also possible to model very complex tables that
includes images or irregular cells. We use colspan attribute with the same
meaning of HTML.
|
<paragraph
eId="sec_2-5-7__para_4">
<content
eId="sec_2-5-7__para_4__content">
<table
eId="table_1" border="1">
<caption
eId="table_1__caption">Thermoplastic rooflights and light
fittings with diffusers</caption>
<tr>
<th>
<p>
</p>
</th>
<th>
<p>
Protected
zone or fire-fighting shaft
</p>
</th>
<th
colspan="2">
<p>Unprotected
zone or protected enclosure</p>
</th>
<th
colspan="2">
<p>Room</p>
</th>
</tr>
<tr>
<th>
<p>
Classification
of lower surface
</p>
</th>
<th>
<p>
Any
thermoplastic
</p>
</th>
<th>
<p>TP(a)
rigid</p>
</th>
<th>
<p>TP(a)
flexible and TP(b)</p>
</th>
<th>
<p>TP(a)
rigid</p>
</th>
<th>
<p>TP(a)
flexible and TP(b)</p>
</th>
</tr>
</table>
</content>
</paragraph>
|
Or including forms and images:
|
<preface>
<p
class="heading">
<docTitle>Form XV
Public Service Vehicle Licence original REPUBLIC OF KENYA THE TRAFFIC
ACT</docTitle>
</p>
</preface>
<mainBody>
<container
eId="container_1" class="table"
name="table">
<p>(Section 97
(1))</p>
<table
eId="container_1 table_1">
<tr>
<td>
<p>
<img
src="signalxv.jpg"/>
</p>
</td>
<td>
<p>
<fillIn>Cheque No.............................</fillIn>
<fillIn>Cash
................................</fillIn>
</p>
</td>
</tr>
<tr>
<td>
<p>STATION .........................................................................</p>
<p>ISSUING OFFICER
.....................................................</p>
</td>
</tr>
|
Finally
if you need to use structured caption the following XML fragment provides a
correct solution for including it in table element:
|
<table>
<caption>
<span
class="autoNum">Table 1</span> -
<subFlow
name="structuredCaption">
<p>First line</p>
<p>Second line</p>
</subFlow>
</caption>
<tr>
<th><p>Head 1</p></th>
<th><p>Head
2</p></th>
</tr>
<tr>
<td><p>Data 1</p></td>
<td><p>Data 2</p></td>
</tr>
</table>
|
5.12 Akoma Ntoso alternative to represent a list
Three models can be used to represent a list
1. a list as a hierarchical container
• the list is marked
using the <list> element;
• the list introduction
is marked using <intro>
and the list conclusion is marked using the <wrapUp>
element.
Each item of the list is a hierarchical container (for
example, point or indent)
Example :
|
<list
eId="...__list_1" >
<intro
eId="...__list_1__intro" wId="2013-619260-2">
<p>The Decisions referred to in Article 13(1) shall not impede the
free
movement in the Union and the production, manufacture,
making available on the market including importation to the
Union, transport, and exportation from the Union of new
psychoactive substances:</p>
</intro>
<point
eId="...__list_1__point_a" wId="2013-619261">
<num>(a)</num>
<content eId="...__list_1__point_a__content"
wId="2013-619261-1">
<p>for scientific research and development purposes;</p>
</content>
</point>
<point
eId="...__list_1__point_b" wId="2013-619262">
<num>(b)</num>
<content eId="...__list_1__point_b__content"
wId="2013-619262-1">
<p>for uses authorised under Union legislation;</p>
</content>
</point>
</list>
|
2. a list as a block
• the list is marked
using the <blockList>
• the list introduction
is marked using the <listIntroduction>
element and the list conclusion is marked using the <listWrapUp> element.
Each item of the list is marked using the <item> element.
Example:
|
<blockList
eId="...__list_1">
<listIntroduction eId="...__list_1__intro">The
Commission conducted an impact assessment of policy
alternatives, taking into account the consultation of interested
parties
and the results of external studies. The impact
assessment concluded that the following solution would be
preferred:</listIntroduction>
<item
eId="...__list_1__item_1">
<num>–</num>
<p>a more graduated and better targeted set of restriction
measures on new psychoactive substances, which should not
hinder the industrial use of substances.</p>
</item>
<item
eId="...__list_1__item_2">
<num>–</num>
<p>restriction measures should be introduced earlier and
substances suspected to pose immediate public health risks
should be subjected to temporary restrictions.</p>
</item>
<listWrapUp eId="...__list_1__wrapup">finally we have
…</listWrapUp>
</blockList>
|
3. a list as an HTML element
• the list is marked using the <ol> element for ordered list or
<ul> for unordered list
• Each item of the list is marked using the <li> element.
Example:
|
<ul
eId="...__ul_1">
<li eId="...__ul_1__li_1">
<p>a more graduated and better targeted set of restriction
measures on new psychoactive substances, which should not
hinder
the industrial use of substances.</p>
</li>
<li eId="...__ul_1__li_2">
<p>restriction measures should be introduced earlier and
substances suspected to pose immediate public health risks
should be subjected to temporary restrictions.</p>
</li>
</ul>
|
Two models can be used to represent a set of provisions
1. as a hierarchical container
This is the model for the set of sections in the body of an
act or a bill.
Example:
|
<chapter
eId=",,,__chp_I">
<num>CHAPTER I</num>
<heading eId=",,,__chp_I__heading">Subject matter -
Scope -
Definitions</heading>
<article
eId="art_1">
<num>Article 1</num>
<heading eId="art_1__heading">Subject matter and
scope</heading>
<paragraph eId="art_1__para_1">
<num>1.</num>
<content eId="art_1__para_1__content">
<p>This Regulation establishes rules for restrictions to the
free
movement of new psychoactive substances in the internal
market. For that purpose it sets up a mechanism for
information exchange on, risk assessment and submission to
market restriction measures of new psychoactive substances
at Union level.</p>
</content>
</paragraph>
...
</article>
...
</chapter>
|
2. as a block
This is used for documents without a well defined
structures.
Example:
|
<tblock
eId="...__tblock_3">
<num>3.</num>
<heading
eId="...__tblock_3__heading">LEGAL ELEMENTS OF THE
PROPOSAL</heading>
<tblock
eId="...__tblock_3.1">
<num>3.1.</num>
<heading eId="...__tblock_3.1__heading">The legal
base</heading>
<p>The proposal aims at ensuring that trade in new psychoactive
substances having industrial and commercial uses is not hindered and
that
the functioning of this market is improved, while the health
and
safety of individuals are protected from harmful substances,
which
cause concern at the EU level.</p>
</tblock>
</tblock>
|
Akoma Ntoso does not provide markup for situations
that are very specific and for which better suited vocabularies already exist .
For instance, mathematical formulas and drawings have well-known standard XML vocabularies
that should be used rather than inventing new ones. For these situations, the
<foreign> element can be used to specify fragments of content that correspond
to structures and data that are not currently managed by Akoma Ntoso.
For instance, the following is a valid
Akoma Ntoso fragment to show the equation ax2+bx+c:
|
<foreign>
<math xmlns="http://www.w3.org/1998/Math/MathML">
mrow>
<mi>a</mi>
<mo>⁢</mo>
<msup>
<mi>x</mi>
<mn>2</mn>
</msup>
<mo>+</mo>
<mi>b</mi>
<mo>⁢</mo>
<mi>x</mi>
<mo>+</mo>
<mi>c</mi>
</mrow>
</math>
</foreign>
|
The <foreign> element is a
block-level element. This means that it is presumed that its content appears in
a vertically isolated block. Furthermore, only fully qualified XML fragments can
appear within the <foreign> element, and they must belong to different namespaces
than Akoma Ntoso’s. Finally, it should be noted that <foreign> should only
be used when Akoma Ntoso does not provide support for the notation rather than to
simply include XML fragments from other vocabularies. Thus, it is not appropriate
to place HTML fragments within a <foreign> element as there is no feature
of HTML that cannot be expressed in Akoma Ntoso. In general, you cannot use
elements from a foreign namespace for elements for which a correspondence in
Akoma Ntoso exists.
Akoma Ntoso manages seven main document
types, grouped for function, organization, or role in the legal domain:
·
Collection Structure
·
Hierarchical Structure
·
Debate Structure
·
Amendment Structure
·
Judgment Structure
·
Open Structure
·
Portion Structure
A particular attention is devoted to the
table, attachments, components that could be included in any type of document.
Composite documents are containers of other
documents that have their own identity, lifecycle, workflow, and other
metadata. An example is the Official Journal or Official Gazette volume where
many bills, acts, minutes, reports are collected. Each document is autonomous
with its FRBR identification package, metadata, modifications, and temporal information.
Nevertheless, the volume of the Journal is an independent work that is composed
of other works.
A collection structure is any folder (such
as one that contains a bill) that is usually composed of several documents
(cover, motivations, commission report, amendments, first draft of a bill,
amended bill, etc.).
In this way, it is possible to represent a
document composed of different autonomous parts (work or expressions). The
following example shows a documentCollection, with the bill (proyecto de ley)
and the explanatory part (motivos).
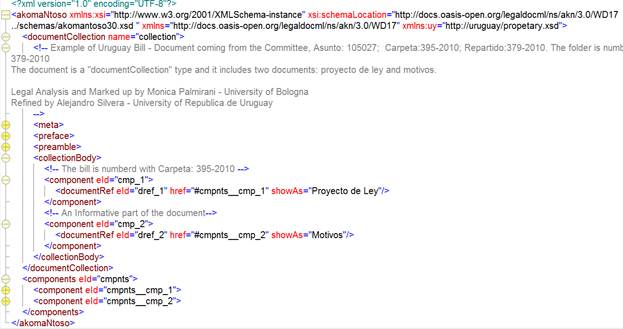
We have several documents that belongs to the collection structure. Certain types of
documents, such as amendmentLists and officialGazettes, are usually made of
several distinct and autonomous documents.
|
Name
|
Definition
|
Structure
|
|
DOCUMENT COLLECTION
|
The type documentCollection is a generic document type for
representing any kind of collection container.
|
Complex structure composed by different works or by
different expressions (e.g. different versions of the same bill: one
presented in the Chamber of Deputies and another presented in the Senate)
A document collection can also be used, for example, to
represent an EP committee's report on a bill, containing a Resolution
(possibly with an amendments list annexed), a Explanatory memorandum Opinions
of other committees.
|
|
AMENDMENT LIST
|
An amendment list is a document listing a series of
amendments.
|
Complex structure including amendments and parts of the
text by which an amendment is introduced.
|
|
OFFICIAL GAZETTE
|
An Official Gazette or Official Bulletin
|
Official publishing source of law composed of an
assortment of legal documents (laws, decrees, orders, legal notices, etc.).
|
The different documents included in the documentCollection
can be represented in three different ways:
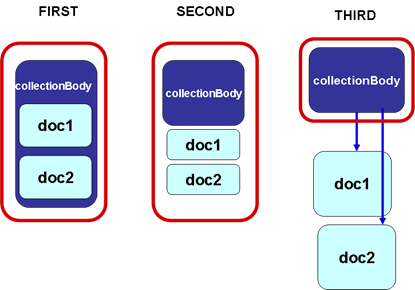
1. The documents are embedded in the collectionBody of the
documentCollection:
|
<?xml
version="1.0" encoding="UTF-8"?>
<akomaNtoso
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://docs.oasis-open.org/legaldocml/ns/akn/3.0
../schemas/akomantoso30.xsd"
xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0">
<documentCollection name="billPackage">
<meta>
...
</meta>
<coverPage>
...
</coverPage>
<collectionBody>
<component eId="cmp_1">
<bill name="bill">
<meta>,,, </meta>
<preface>
<p><docTitle>THE KENYA INFORMATION AND COMMUNICATIONS BILL
2006</docTitle></p>
<p><docNumber>No.8 of 2006</docNumber></p>
<longTitle>
<p>AN ACT of Parliament to promote and develop in an orderly manner the
carriage and content of communications (including broadcasting, multimedia,
telecommunications and postal), for the establishment of a commission to
regulate all forms of communications, for the establishment of an appeals
tribunal and for connected purposes.
</p>
</longTitle>
</preface>
<body>
<section id="sec_1">
<num>1.</num>
<heading>Short title and commencement</heading>
<content>
<p>This
Act may be cited as the <shortTitle>Kenya Information and
Communications Act, 2006</shortTitle> and shall come into operation on
such date as the Minister may, by notice in the Gazette, appoint and
different dates may be appointed for different provisions.</p>
</content>
</section> </body>
</bill>
</component>
<component eId="cmp_2">
<interstitial
eId="cmp_2__interstitial">
<p>Any text is in the collection but belongs to no individual
document</p>
</interstitial>
</component>
<component eId="cmp_3">
<doc
name="memorandum">
<meta> ...the metadata of the second document... </meta>
<preface> ...the preface of the second document... </preface>
<mainBody> ...the body of the second document... </mainBody>
</doc>
</component>
</collectionBody>
</documentCollection>
</akomaNtoso>
|
2. The documents are modelled in the components part of the
documentCollection:
|
<?xml
version="1.0" encoding="UTF-8"?>
<akomaNtoso
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://docs.oasis-open.org/legaldocml/ns/akn/3.0
./akomantoso30.xsd"
xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0">
<documentCollection
name="billPackage">
<meta>
....
</meta>
<coverPage>
</coverPage>
<collectionBody>
<component eId="cmp_1">
<documentRef eId="cmp_1__dref_1" href="#bill"
showAs="BILL"/>
</component>
<component eId="cmp_2">
<interstitial eId="cmp_2__interstitial">
<p>Any text is in the collection but belongs to no indi-vidual
document</p>
</interstitial>
</component>
<component eId="cmp_3">
<documentRef eId="cmp_3__dref_1" href="#memorandum"
showAs="MEMORANDUM"/>
</component>
</collectionBody>
</documentCollection>
<components>
<component
eId="cmpnts__cmp_1">
<bill name="bill">
<meta>,,, </meta>
<preface>
<longTitle eId="cmpnts__cmp_1__longTitle">
The
title of the bill
</longTitle>
</preface>
<body>
,,,
</body>
</bill>
</component>
<component
eId="cmpnts__cmp_2">
<doc
name="memorandum">
<meta> ...the metadata of the second document... </meta>
<preface> ...the preface of the second document... </preface>
<mainBody>
...the body of the second document... </mainBody>
</doc>
</component>
</components>
</akomaNtoso>
|
3. The documentCollection includes only the <documentRef> specification to
external documents that are modeled and represented in separated XML files.
|
<?xml
version="1.0" encoding="UTF-8"?>
<akomaNtoso
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://docs.oasis-open.org/legaldocml/ns/akn/3.0
./akomantoso30.xsd"
xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0">
<documentCollection
name="billPackage">
<meta>
....
</meta>
<coverPage>
</coverPage>
<collectionBody>
<component eId="cmp_1">
<documentRef eId="cmp_1__dref_1"
href=“/akn/uy/bill/2013-02-10/450!bill" showAs="BILL"/>
</component>
<component eId="cmp_2">
<interstitial eId="cmp_2__interstitial">
<p>Any text is in the collection but belongs to no individual
document</p>
</interstitial>
</component>
<component eId="cmp_3">
<documentRef eId="cmp_3__dref_1"
href="/akn/doc/2013-02-10/450!memorandum"
showAs="MEMORANDUM"/>
</component>
</collectionBody>
</documentCollection>
</akomaNtoso>
|
It is also possible to have a component in the same position
as the attachment, at the end of the main document. This permits recursive
definition inside of the documentCollection.
The following case shows the usage of this construct.
|
<?xml
version="1.0" encoding="UTF-8"?>
<akomaNtoso xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://docs.oasis-open.org/legaldocml/ns/akn/3.0
./akomantoso30.xsd "
xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0"
xmlns:uy="http://uruguay/propetary.xsd">
<documentCollection
name="billPackage">
<meta>
FRBR
block information
</meta>
<preface>
Preface
of the documentCollection
</preface>
<preamble>
Preamble
of the documentCollection
</preamble>
<collectionBody>
<component
eId="cmp_1">
<documentRef eId="dref_1" href="#cmpnts_cmp_1"
showAs="INFORME EN MAYORÍA Y PROYECTO DE LEY - FRENTE AMPLIO"/>
</component>
<component eId="cmp_2">
<documentRef eId="dref_2" href="#cmpnts__cmp_2"
showAs="INFORME EN MINORÍA Y PROYECTO DE RESOLUCIÓN - PARTIDO
NACIONAL"/>
</component>
</collectionBody>
</documentCollection>
<components>
<component
eId="cmpnts__cmp_1">
<documentCollection
name="informeDeMayoria" contains="originalVersion">
<meta>
....
</meta>
<collectionBody>
<component
eId="cmpnts__cmp_1__cmp_1">
<documentRef
eId="cmpnts_cmp1_dref_1" href="#cmpnts_cmp_1__cmpnts__cmp_1"
showAs="Informe"/>
</component>
<component
eId=" cmpnts__cmp_1__cmp_2">
<documentRef
eId=" cmpnts_cmp1_dref_2" href="#cmpnts_cmp_1__cmpnts__cmp_2"
showAs="Bill"/>
</component>
</collectionBody>
<components>
<component
eId="cmpnts__cmp_1__cmpnts__cmp_1">
<doc
name="reporteInformeEnMayoria">
...
</doc>
</component>
<component
eId="cmpnts__cmp_1__cmpnts__cmp_2">
<bill
name="bill">
...
</bill>
</component>
</components>
</documentCollection>
</component>
<component
eId="cmpnts__cmp_2">
<documentCollection
name="informeMinoriaNacional" contains="originalVersion">
<meta>
...
</meta>
<collectionBody>
<component
eId=" cmpnts__cmp_2__cmp_1">
<documentRef
eId=" cmpnts_cmp2_dref_1" href="#cmpnts_cmp_2__cmpnts__cmp_1"
showAs="Informe"/>
</component>
<component
eId=" cmpnts__cmp_2__cmp_2">
<documentRef
eId="cmpnts_cmp2_dref_2" href="#cmpnts_cmp_2__cmpnts__cmp_2"
showAs="Resolucion"/>
</component>
</collectionBody>
<components>
<component
eId="cmpnts__cmp_2__cmpnts__cmp_1">
<doc
name="reportInformeMinoriaNational">
...
</doc>
</component>
<component
eId=" cmpnts__cmp_2__cmpnts__cmp_2">
<statement name="PROYECTO DE RESOLUCIÓN">
...
</statement>
</component>
</components>
</documentCollection>
</component>
</components>
</akomaNtoso>
|
6.2.3 Components and
<componentRef>
There are use-cases where an
authonomous work, emitted by an authority with its FRBR block, incudes another
document that is not autonomous (e.g., draft bill incuded in a verbatim,
resolution included in a report). In these cases we can model the embedded
document using <component> part for favouring
the markup and we use <componentRef> for
referring to this component.
A <componentRef>
is a manifestation-level reference to an XML sub-structure that for practical
purpose has been extracted from the main structure. The XML substructure does
not have independent identity outside of the hosting document, and may be
extracted because of length or size considerations, or to better organize the
delivery of the requested structures. Being manifestation-level, such
structures do not have autonomous legal identity or existence, and should be
considered for all purposes as parts directly contained inside the host
document. Of course, manifestations of whole documents may be referred to using
<componentRef>, as long as this approach is
fully equivalent in all purposes to simply inserting the whole document
manifestation in place of the reference.
<componentRef>
is admissible in the following position:
|
Inside of the container like
<preface><preamble><recital><citation><conclusions>
<header> etc.
|
<blockContainer>
<componentRef showAs="" src=""/>
</blockContainer>
|
|
Inside of any hcontainer
|
<hcontainer eId="hcontainer_1" name="hcontainerName">
<componentRef showAs="" src=""/>
</hcontainer>
<article eId="art_1">
<componentRef showAs="" src=""/>
</article>
|
|
Inside of any subflow like
<embeddedStructure><quotedStructure><authorialNote> etc.
|
<embeddedStructure>
<componentRef showAs="" src=""/>
</embeddedStructure>
<quotedStructure>
<componentRef showAs="" src=""/>
</quotedStructure>
|
Any document with a hierarchical structure belongs to this
family of documents.
For hierarchical structure we mean a structure organized
with higher levels that group basic units, basic units (article, section, etc.)
and lower levels inside of the basic unit.
The Akoma Ntoso standard is neutral with respect to the
legal drafting techniques of the different legal traditions, providing most of
the hierarchical elements for modeling the body structure: book, tome, part,
subpart, title, subtitle, chapter, subchapter, section, subsection, clause,
subclause, paragraph, subparagraph, division, point, indent, alinea, list,
sublist.
For these reasons, the main requirements of structuring
legal text are covered.
The following table shows an example how to use of
hierarchical elements:
|
|
Anglophone tradition
|
French
tradition
|
Portuguese tradition
|
Italian
tradition
|
Spanish
tradition
|
EU tradition
(here,only English, French, Spanish)
|
AKOMA NOTOSO
|
|
Higher Division
|
|
Tome
|
|
|
Tome
|
|
tome
|
|
Part
|
Partie (codes)
|
Parte (codes)
|
Parte
|
Parte
|
Part/
Partie
parte
|
part
|
|
|
Livre (codes)
|
Livro (codes)
|
Libro
|
Libro
|
|
book
|
|
Title
|
Titre
|
Título
|
Titolo
|
Título
|
Title/
Titre/
Titulo
|
title
|
|
Chapter
|
Chapitre
|
Capítulo
|
Capitolo
|
Capítulo
|
Chapter/
Chapitre
Capitulo
|
chapter
|
|
Subchapter
Article (US)
|
Section (codes)
|
Secção
|
Sezione
|
Sección o Párrafo
|
Section/
section/
Sección
|
section
|
|
|
Subsection (code)
|
SubSeçcão
|
Subsezione
|
|
Subsection/
Sous-Section/
Subsección
|
subsection
|
|
|
level
|
|
|
|
|
|
level
|
|
Basic Unit
|
Section
Rule
|
Article
|
Artigo
|
Articolo
|
Artículo
|
Article (rule)/
article/
articulo/
|
article/
section/
rule
|
|
Subdivision
|
Subsection
Clause (in US Constitution)
|
Alinéa
|
Alineas
|
Comma
|
Inciso
|
unnumbered paragraph/
alinéa /
Párrafo
|
subsection
aliena
clause
|
|
Paragraph
|
Paragraphe
|
Paragrafo
|
Paragrafo
|
|
paragraph
paragraphe
Apartado
|
paragraph
|
|
Proviso
|
|
|
|
|
|
proviso
|
|
Subparagraph
|
|
|
|
|
Subparagraph/
sous paragraphe/
Párrafo
|
subparagraph
|
|
|
|
|
|
|
|
division
|
|
|
|
|
Lettera
|
letra
|
Point/
point/
Letra
|
point/item
|
|
|
|
|
Numero
|
número
|
Point/
point/
punto
|
point/item
|
|
Latin number
|
|
|
|
|
Point/
point
Inciso
|
point/item
|
|
|
|
|
|
|
Indent/
tiret
guion
|
point/item
|
The list of the hierarchical partitions included in Akoma
Ntoso are the following, listed in alphabetic order:
·
alinea
·
article
·
book
·
chapter
·
clause
·
division
·
indent
·
level
·
list
·
paragraph
·
part
·
point
·
proviso
·
rule
·
subrule
·
section
·
subchapter
·
subclause
·
subdivision
·
sublist
·
subparagraph
·
subpart
·
subrule
·
subsection
·
subtitle
·
title
·
tome
·
transitional.
Each hierarchical element has some relevant optional
children that characterize the hierarchy pattern:
- <num>:
the element <num>
marks up the number of the partition, including letters in case of points
(e.g., the point (a) is <num>(a)
</num>);
- <heading>:
the element <heading>
marks up the title of the partition;
- <subheading>:
the element <subheading>
marks up the subtitle of the partition;
- <crossheading>:
the element <crossheading>
marks up an intermediate container.
The debate structure is dedicated to parliamentary documents
such as report of committees, transcript record of the parliament or assembly,
Hansard, debates, voting report, roll calling, etc. In particular, to these documents
is the unstructured format and the fact that they describe a narrative, similar
to a script or a screenplay. For these reasons the debateStructure includes
particular structures that permits this modeling.
Debate record is similar to a screenplay and so it is mostly
composed by sections according with the main topics or actions admitted in the
rules of procedure in the assembly:
·
administrationOfOath
·
rollCall
·
prayers
·
oralStatements
·
writtenStatements
·
personalStatements
·
ministerialStatements
·
resolutions
·
nationalInterest
·
declarationOfVote
·
communication
·
petitions
·
papers
·
noticesOfMotion
·
questions
·
address
·
proceduralMotions
·
pointOfOrder
·
adjournment
·
debateSection.
Each of these container can include the following elements:
·
speechGroup: group of speeches in the dialogue;
·
speech: speech dialogue;
·
question: question dialogue;
·
answer: answer dialogue;
·
other: other dialogue;
·
scene: description of some action performed inside of the
assembly like applause, shouting, crying, etc.;
·
narrative: narrative part of what happened in the assembly;
·
summary: summary of an event like the result of a voting.
In case it is necessary we have also inline element
<remark> for making up the type of annotation: “sceneDescription” (e.g.
the minority party leaves the room shouting out), “phenomenon” (e.g. raining),
“caption”, “translation” (e.g. [Bab’ uNkwinti, are you going to say it in
Afrikaans?]).
An example of fragment of debate is blow presented.
|
<debate
name="record">
<meta>...</meta>
<coverPage>...</coverPage>
<preface>...</preface>
<debateBody>
<debateSection
eId="dbsect_1" name="Preliminary">
<rollCall
eId="dbsect_1__rollCall_1">...</rollCall>
<prayers
eId="dbsect_1__prayers_1">...</prayers>
</debateSection>
<debateSection
eId="dbsect_2" name="Actas">
<speech
eId="dbsect_2__speech_1" by="#Ascencio">
<from>El señor ASCENCIO (Presidente).- </from>
<p> El
señor Secretario dará lectura a los pareos.
<remark
type="sceneDescription">(Aplausos)</remark>.</p>
.....
</speech>
<narrative
eId="dbsect_2__narrative_1" >-Con posterioridad, la Sala se
pronunció sobre el proyecto en los siguientes términos:</narrative>
<summary
eId="dbsect_2__summary_1" >
<outcome
refersTo="#seAbstiene"> -Se abstuvieron los diputados señores:
<vote
by="#persona">
<person
eId="p3517" refersTo="#GalileaVidaurreJoseAntonio">Galilea
Vidaurre José Antonio;</person>
</vote>
</outcome>
</summary>
<scene
eId="dbsect_2__scene_1" >-Aplausos.</scene>
</debateSection>
<debateBody>
</debate>
|
The amendment structure is dedicated to modeling particular
official documents that provide instructions or proposals for modifications to
a bill.
Example: amendment of the European Parliament on a proposal
from the Commission can be marked as following.
|
<amendment
name="amendment">
<meta>
<identification source=""> ... </identification>
<analysis
source="http://www.europarl.europa.eu/">
<activeModifications>
<textualMod
eId="textualMod_1" type="substitution">
<source href="#mod_1__qstr_2__rec_3"/>
<destination href="uri:COM
proposal/bill(Expression)]#rec_3"/>
</textualMod>
</activeModifications>
</analysis>
<references source="http://www.europarl.europa.eu/">
<TLCConcept eId="concept-content-current"
href="/concept/content/current"
showAs="original version of amended fragment"/>
<TLCConcept eId="concept-content-proposed"
href="/concept/content/proposed"
showAs="proposed version of amended fragment"/>
<TLCPerson eId="codict_person-id-96835"
href="eu.europa.europarl.codict:person/id=96835"
showAs="Traian Ungureanu"/>
<TLCPerson
eId="codict_person-id-96832"
href="eu.europa.europarl.codict:person/id=96832"
showAs="Pascale Gruny"/>
</references>
</meta>
<preface>
<container eId="preface__container_1"
name="mainDoc">
<p
xml:space="preserve"><docIntroducer><person
eId="preface__container_1__person_1"
refersTo="#codict_person-id-96835">Traian
Ungureanu</person> and <person eId="preface__container_1__person_2"
refersTo="#codict_person-id-96832">Pascale
Gruny</person></docIntroducer></p>
</container>
</preface>
<amendmentBody>
<amendmentHeading>
<block
name="amendedAct"
xml:space="preserve"><docType>Proposal for a
decision</docType> - amending act</block>
<block name="amendedAct"
xml:space="preserve"><inline
name="AMposition">Recital 3</inline></block>
</amendmentHeading>
<amendmentContent>
<block
name="versionTitle"
refersTo="#concept-content-current">Text proposed by the
Commission</block>
<block
name="versionTitle"
refersTo="#concept-content-proposed">Amendment</block>
<block
name="changeBlock">
<mod
eId="mod_1" refersTo="#textualMod_1">
<quotedStructure
eId="mod_1__qstr_1" refersTo="#concept-content-current">
<recital eId="mod_1__qstr_1__rec_3">
<num>(3)</num>
<p xml:space="preserve">In line with the Inter-institutional
agreement of <date date="2006-05-17">17 May 2006</date>
between the European Parliament, the Council and the Commission on budgetary
discipline and sound financial management, <change>EUR 100 million
needs to be reallocated from the existing budget to finance</change>
the new European microfinance facility <change>for employment and
social inclusion – Progress</change></p>
</recital>
</quotedStructure>
<quotedStructure eId="mod_1__qstr_2"
refersTo="#concept-content-proposed">
<recital eId="mod_1__qstr_2__rec_3">
<num>(3)</num>
<p xml:space="preserve">In line with the Inter-institutional
agreement of <date date="2006-05-17">17 May 2006</date>
between the European Parliament, the Council and the Commission on budgetary
discipline and sound financial management, <change>in the event that no
additional appropriations are allocated, then</change> the new European
microfinance facility <change>should be financed by reallocating
resources from other budgetary sources.</change></p>
</recital>
</quotedStructure>
</mod>
</block>
</amendmentContent>
<amendmentJustification>
<block
name="justificationHeading">Justification</block>
<p xml:space="preserve">Due
to the present financial situation there is a clear need to find the best
financil solution for the new instrument. From this poin of view, there
should be furtherconsultations to find the optimal solution in order for the
facility to deliver to its aims.</p>
</amendmentJustification>
</amendmentBody>
</amendment>
|
6.6 Judgment Structure
The Judgment structure is dedicated to case-law, precedents,
and judiciary decisions.
The structure of those documents varies greatly without a
common template, especially the metadata are complex and with a great diversity
in each legal tradition and judicial system.
The main legal part of the judgment <judgmentBody> and
it is divided in <background>, <introduction>, <motivation>,
<decision> containers.
We have also particular inline elements used in the
judiciary system:
·
<docJurisdiction></docJurisdiction>
for marking up the jurisdiction of the case-law;
·
<docketNumber></docketNumber>
for marking up number of the trial;
·
<neutralCitation>
for marking up the number assigned by the number used for hamonized the
citations in a given judiciaty system (e.g. [2008] ZASCA 134);
·
<party
refersTo=""></party> for marking up the party;
·
<lawyer
refersTo=""></lawyer> for
marking up the laywer;
·
<judge
refersTo=""></judge> for
marking up the judge;
·
<opinion>
for marking up the opinion of each judge;
·
<argument></argument>
for marking up the argument sentences for supporting the judge’s legal
argumentation and reasoning.
Some relevant metadata are included in the <judicial>
metadata block for modeling citations to other legal sources and result of the
judgment.
An example of fragment of judgment is blow presented.
|
<judgment
name="decision">
<meta>
<identification
source="#somebody"></identification>
<publication
date="2008-11-30" name="Law Report" showAs="Law
Report Office Journal" number="555"/>
<classification
source="#somebody"></classification>
<lifecycle
source="#somebody">
<eventRef
date="2008-11-26" eId="eref_1" source="ro1"
type="generation"/>
</lifecycle>
<workflow
source="#somebody">
<step
date="2007-08-23" eId="step_1"
outcome="#outcome_1" by="#chamber "/>
<step
date="2008-11-05" eId=" step_2"
outcome="#outcome_1" by="# senate"/>
</workflow>
<analysis
source="#somebody">
<judicial>
<result
type="deny"/>
<applies
eId="applies_1">
<source href="#ref_11"/>
<destination
href="/za/judgment/SA491/eng@!main.xml"/>
</applies>
<supports
eId="supports_1">
<source
href="#ref_12"/>
<destination
href="/za/judgment/SA490/eng@/!main.xml~par12"/>
</supports>
</judicial>
</analysis>
<references
source="#somebody"></references>
</meta>
<header>
<p>
<party
refersTo=""></party>
<lawyer
refersTo=""></lawyer>
<judge
refersTo=""></judge>
</p>
</header>
<judgmentBody>
<background></background>
<introduction></introduction>
<motivation></motivation>
<decision></decision>
</judgmentBody>
<conclusions></conclusions>
</judgment>
</akomaNtoso>
|
A document is text devoid of any specific structure.
Examples include annexes, tables, schedules, informative material, letters, and
memorandums.
|
Name
|
Definition
|
Structure
|
|
DOCUMENT
|
A
document is any valid text for which there is no specific structure or
document type.
|
Texts
having an open structure.
The
main body of the text is the main content.
|
An example of usage of the general document is presented
below. It is an annex that has no particular structure.
|
Appendix
1
OFFICIALS
FROM THE DEPARTMENT OF DEFENCE
Mr.
January (Secretary of Defence and Director General of the Department)
Mr.
February (Deputy Director General and Chief Director of Policy and Planning)
Lieutenant
General March (SANDF Chief: Corporate Staff)
|
<preface>
<p class="heading">
<docType>APPENDIX 1</docType>
<docTitle>OFFICIALS FROM THE DEPARTMENT OF DEFENCE
</docTitle>
</p>
</preface>
<mainBody>
<container eId="container_1" name="members"
class="memberslist">
<ol eId="container_1__ol_1">
<li eId="container_1__ol_1__li_1> Mr January (Secretary for
Defence and Director General of the Department)</li>
<li eId="container_1__ol_1__li_2>Mr Feruray (Deputy Director
General and Chief Director Policy and Planning)</li>
<li eId="container_1__ol_1__li_3>Lieutenant General March
</span>(SANDF Chief: Corporate Staff)</li>
</ol>
</container>
|
|
1.
Introduction
The
Portfolio Committee on Defence considered the 2007/2008 Budget of the
Department of Defence on 22–23 March 2007 as part of its oversight function
over the Department of Defence. The report is based on both the budget
hearings held on 22 March 2007 as well as the committee deliberations held on
23 March 2007.
|
<hcontainer
eId="hcontainer_1" name="issue">
<num>1. </num>
<heading>Introduction</heading>
<paragraph
eId="hcontainer_1__para_1">
<content>
<p>The Portfolio Committee on Defence
considered the 2007/2008 Budget of the Department of Defence on 22 -23 March
2007, as part of its oversight function over the Department of Defence. The
report is based on both the budget hearings held on 22 March 2007 as well as
the committee deliberations on 23 March 2007.
</p>
</content>
</paragraph>
</hcontainer>
</mainBody>
|
6.8 Portion Structure
The Portion Structure is a particular template which permits
modeling a portion of the normative part of a document, at the level of the
manifestation. It is a pure technical split. Once modeled, it is possible to
refer to the portion inside of another Akoma Ntoso document using the <componentRef> element. This is
useful for fragmenting a very long document and for facilitating legal drafting
and document management.
A typical example could be the US Code composed by different
titles that are autonomous works. For the code, we could define this:
|
<collectionBody>
<component><documentRef
href="uri/title1.xml" /></component>
<component><documentRef
href="uri/title2.xml" /></component>
<component><documentRef
href="uri/title3.xml" /></component>
</collectionBody>
|
|
|
Each title is composed by several
long chapters. We can use <componentRef>
combined with <portion> for better managing the
length of the whole document.
|
<act>
….<meta>…</meta>
….<body>
….….….<componentRef showAs=""
src="/akn/us/usc/title_9/eng@2013-07-26/!main ~chp_1.xml"/>
….….….<componentRef showAs=""
src="/akn/us/usc/ title_9/eng@2013-07-26/!main ~chp_2.xml"/>
….….….<componentRef showAs=""
src="/akn/us/usc/title_9/eng@2013-07-26/!main ~chp_3.xml"/>
omissis
….</body>
</act>
|
|
|
In this case, the chapter 3
content is outside the document containing the title 9. The chapter has its own
meta data block (FRBRManifestation only inside of the FRBR block because the
rest FRBRWork and FRBRExpression are the same of the title_9 document) but it
is not necessary to have a preface, preamble, or annexes, only <portionBody>. Note that the name of the Manifestation
is <FRBRuri
value="/akn/us/usc/title_9/eng@2013-07-26/!main~chp_3.xml"/>
and in the FRBRManifestation block it is possible to specify also the portion
with <FRBRportion from="chp_3" />. In
case of interval, (e.g. from chapter 3 to chapter 5) we also use the attribute
upTo=”chp_5” to specify the end of the interval.
|
<portion
includedIn="/akn/us/act/title_9">
<meta>
<identification source="#vergottini">
<FRBRWork>
<FRBRthis value="/akn/us/usc/title_9/!main"/>
<FRBRuri value="/akn/us/usc/title_9"/>
<FRBRdate date="1947-07-30" name="Title 9"/>
<FRBRauthor
href="#olrc" as="#author"/>
<FRBRcountry value="us"/>
<FRBRsubtype value="title"/>
<FRBRnumber value="title_9"/>
<FRBRname value="title"/>
<FRBRprescriptive value="false"/>
<FRBRauthoritative value="true"/>
</FRBRWork>
<FRBRExpression>
<FRBRthis value="/akn/us/usc/eng@2013-07-26/title_9/!main"/>
<FRBRuri value="/akn/us/usc/eng@2013-07-26/title_9"/>
<FRBRdate date="2013-07-26" name="Chapter 3 of Title
9 (July 26, 2013)"/>
<FRBRauthor href="#olrc" as="#editor"/>
<FRBRlanguage language="eng"/>
</FRBRExpression>
<FRBRManifestation>
<FRBRthis value="/akn/us/usc/ title_9/eng@2013-07-26/!main
~chp_3.xml"/>
<FRBRuri value="/ akn/us/usc/ title_9/eng@2013-07-26/!main~chp_3.akn"/>
<FRBRdate date="2014-10-07" name="Chapter 3 of Title
9 (July 26, 2013) -- XML Markup"/>
<FRBRauthor href="#vergottini" as="generator"/>
<FRBRportion from="#chp_3" />
</FRBRManifestation>
</identification>
<references source="#vergottini">
<original eId="title_9"
href="/akn/us/usc/title_9" showAs="Title 9"/>
<TLCRole eId="sevretaryOfState" href="/akn/us/ontology/role/secretaryOfState"
showAs="Secretary of State"/>
<TLCRole eId="drafter"
href="/akn/us/ontology/role/drafter"
showAs="Drafter"/>
<TLCRole eId="editor"
href="/akn/us/ontology/role/editor" showAs="Editor"/>
<TLCRole
eId="generator" href="/akn/us/ontology/role/generator"
showAs="Generator"/>
<TLCOrganization
href="/akn/us/ontology/organization/interAmericanCommercialArbitationCommission"
showAs="Inter-American Commercial Arbitration Commission"/>
<TLCOrganization eId="house"
href="/akn/us/ontology/organization/house" showAs="U.S. House
of Representatives"/>
<TLCOrganization eId="olrc"
href="/akn/us/ontology/organization/olrc" showAs="Office of
the Law Revision Counsel"/>
<TLCPerson eId="vergottini"
href="/akn/us/ontology/person/somebody" showAs="Grant
Vergottini"/>
</references>
</meta>
<portionBody>
<chapter GUID="idd1d2ae15-f639-11e2-8470-abc29ba29c4d"
eId="chp_3">
<num>CHAPTER 3—</num>
<heading>INTER-AMERICAN CONVENTION ON INTERNATIONAL COMMERCIAL
ARBITRATION</heading>
<intro>
<toc>
<tocItem href="" level="1">
<span>Sec.</span>
</tocItem>
<tocItem href="#sec_301" level="1">
<span>301.</span>
<span>Enforcement of Convention.</span>
</tocItem>
<tocItem href="#sec_302" level="1">
<span>302.</span>
<span>Incorporation by reference.</span>
</tocItem>
<tocItem
href="#sec_303" level="1">
<span>303.</span>
<span>Order to compel arbitration; appointment of arbitrators;
locale.</span>
</tocItem>
<tocItem href="#sec_304" level="1">
<span>304.</span>
<span>Recognition and enforcement of foreign arbitral decisions and
awards; reciprocity.</span>
</tocItem>
<tocItem
href="#sec_305" level="1">
<span>305.</span>
<span> Relationship between the <ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American
Convention</ref> and the <ref href="/akn/un/act/1958NYConvention/eng@1958-06-10">Convention
on the Recognition and Enforcement of Foreign Arbitral Awards of June 10,
1958</ref>. </span>
</tocItem>
<tocItem href="#sec_306" level="1">
<span>306.</span>
<span>Applicable rules of <organization
refersTo="#interAmericanCommercialArbitationCommission">Inter-American
Commercial Arbitration Commission</organization>.</span>
</tocItem>
<tocItem href="#sec_307" level="1">
<span>307.</span>
<span>Chapter 1; residual application.</span>
</tocItem>
</toc>
</intro>
<section GUID="idd1d2d527-f639-11e2-8470-abc29ba29c4d"
eId="sec_301">
<num>§ 301.</num>
<heading> Enforcement of Convention</heading>
<content>
<p> The <ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American
Convention on International Commercial Arbitration of January 30,
1975</ref>, shall be enforced in United States courts in accordance
with this
<ref href="#chp_3">chapter</ref>. </p>
<block name="sourceCredit">(Added <ref href="/akn/us/act/pl_101/369/eng@1990-08-15/~sec_1">Pub.
L. 101–369, § 1 , Aug.
15, 1990</ref> , <ref
href="/akn/us/act/stat_104/448">104 Stat. 448</ref> .)
</block>
</content>
</section>
<section GUID="idd1d2d52a-f639-11e2-8470-abc29ba29c4d"
eId="sec_302">
<num>§ 302.</num>
<heading> Incorporation by reference</heading>
<content>
<p><mref>Sections <ref href="/akn/us/act/title_9/!main
~sec_202">202</ref>, <ref
href="/akn/us/act/title_9/!main ~sec_203">203</ref>,
<ref href="/akn/us/act/title_9/!main
~sec_204">204</ref>, <ref
href="/akn/us/act/title_9/~sec_205">205</ref>, and <ref
href="/akn/us/act/title_9/!main ~sec_207">207</ref> of
this title</mref> shall apply to this chapter as if specifically set
forth herein, except that for the purposes of this chapter “the Convention”
shall mean the Inter-American
Convention.</p>
<block name="sourceCredit"> (Added <ref
href="/akn/us/act/pl_101/369/eng@1990-08-15/!main ~sec_1">Pub.
L. 101–369, § 1 , Aug.
15, 1990</ref> , <ref
href="/akn/us/act/stat_104/448">104 Stat. 448</ref> .)
</block>
</content>
</section>
<section GUID="idd1d2fc3c-f639-11e2-8470-abc29ba29c4d"
eId="sec_303">
<num>§ 303.</num>
<heading> Order to compel arbitration; appointment of arbitrators;
locale</heading>
<subsection GUID="idd1d2fc3d-f639-11e2-8470-abc29ba29c4d"
eId="sec_303__subsec_a">
<num >(a)</num>
<content>
<p> A court having jurisdiction under this chapter may direct that
arbitration be held in accordance with the agreement at any place therein
provided for, whether that place is within or without the United States. The
court may also appoint
arbitrators in accordance with the provisions of the agreement.</p>
</content>
</subsection>
<subsection GUID="idd1d2fc3e-f639-11e2-8470-abc29ba29c4d"
eId="sec_303__subsec_b">
<num >(b)</num>
<content>
<p> In the event the agreement does not make provision for the place of
arbitration or the appointment of arbitrators, the court shall direct that
the arbitration shall be held and the arbitrators be appointed in accordance
with <ref href="/akn/us/act/1975__b_35/eng@1975-01-30/!main
~art_3">Article 3 of the
Inter-American Convention</ref>.</p>
</content>
</subsection>
</section>
<section GUID="idd1d2fc40-f639-11e2-8470-abc29ba29c4d"
eId="sec_304">
<num>§ 304.</num>
<heading> Recognition and enforcement of foreign arbitral decisions and
awards; reciprocity</heading>
<content>
<p>Arbitral decisions or awards made in the territory of a foreign
State shall, on the basis of reciprocity, be recognized and enforced under
this chapter only if that State has ratified or acceded to the
<ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American Convention</ref>.</p>
<block name="sourceCredit"> (Added <ref
href="/akn/us/act/pl_101/369/eng@1990-08-15/!main ~sec_1">Pub.
L. 101–369, § 1 , Aug.
15, 1990</ref> , <ref
href="/akn/us/act/stat_104/449">104 Stat. 449</ref> .)
</block>
</content>
</section>
<section GUID="idd1d32352-f639-11e2-8470-abc29ba29c4d"
eId="sec_305">
<num>§ 305.</num>
<heading>Relationship between the <ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American
Convention</ref> and the <ref href="/akn/un/act/1958NYConvention/eng@1958-06-10">Convention
on the Recognition and Enforcement of Foreign Arbitral Awards of June 10,
1958</ref>
</heading>
<intro>
<p> When the requirements for application of both the <ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American
Convention</ref> and the <ref
href="/akn/un/act/1958NYConvention/eng@1958-06-10">Convention on
the Recognition and Enforcement of Foreign Arbitral Awards of June 10,
1958</ref>, are met,
determination
as to which Convention applies shall, unless otherwise expressly agreed, be
made as follows: </p>
</intro>
<paragraph GUID="idd1d32353-f639-11e2-8470-abc29ba29c4d"
eId="sec_305__para_1">
<num>(1)</num>
<content>
<p> If a majority of the parties to the arbitration agreement are
citizens of a State or States that have ratified or acceded to the
Inter-American Convention and are member States of the Organization of
American States, the Inter-American
Convention shall apply.</p>
</content>
</paragraph>
<paragraph GUID="idd1d32354-f639-11e2-8470-abc29ba29c4d"
eId="sec_305__para_2">
<num>(2)</num>
<content>
<p> In all other cases the <ref
href="/akn/un/act/1958NYConvention/eng@1958-06-10">Convention on
the Recognition and Enforcement of Foreign Arbitral Awards of June 10,
1958</ref>, shall apply. </p>
</content>
</paragraph>
</section>
<section GUID="idd1d32356-f639-11e2-8470-abc29ba29c4d"
eId="sec_306">
<num>§ 306.</num>
<heading> Applicable rules of <organization
refersTo="#interAmericanCommercialArbitationCommission">Inter-American
Commercial Arbitration Commission</organization></heading>
<subsection GUID="idd1d34a67-f639-11e2-8470-abc29ba29c4d"
eId="sec_306__subsec_a">
<num >(a)</num>
<content>
<p> For the purposes of this <ref
href="#chp_3">chapter</ref> the rules of procedure of the
<organization
refersTo="#interAmericanCommercialArbitationCommission">Inter-American
Commercial Arbitration Commission</organization> referred to in <ref
href="/akn/us/act/1975__b_35/!main~art_3">Article 3 of the
Inter-American Convention</ref> shall, subject to <ref
href="#sec_306__subsec_b">subsection (b) of this
section</ref>, be those rules as
promulgated by the <organization
refersTo="#interAmericanCommercialArbitationCommission">Commission</organization>
on <date date="1988-07-01">July 1, 1988</date> .
</p>
</content>
</subsection>
<subsection GUID="idd1d34a68-f639-11e2-8470-abc29ba29c4d"
eId="sec_306__subsec_b">
<num >(b)</num>
<content>
<p> In the event the rules of procedure of the <organization
refersTo="#interAmericanCommercialArbitationCommission">Inter-American
Commercial Arbitration Commission</organization> are modified or amended
in accordance with the procedures for amendment of the rules of that
Commission, the <role refersTo="#secretaryOfState">Secretary
of State</role>, by regulation in
accordance with <ref href="/akn/us/act/title_5/!main ~sec_553">section
553 of title 5</ref>, consistent with the aims and purposes of this
Convention, may prescribe that such modifications or amendments shall be
effective for purposes of this <ref
href="#chp_3">chapter</ref>. </p>
</content>
</subsection>
</section>
<section GUID="idd1d34a6a-f639-11e2-8470-abc29ba29c4d"
eId="sec_307">
<num>§ 307.</num>
<heading> <ref href="/akn/us/act/title_9/!main
~chp_1">Chapter 1</ref>; residual application</heading>
<content>
<p><ref href="/akn/us/act/title_9/!main ~chp_1">Chapter
1</ref> applies to actions and proceedings brought under this <ref
href="/akn/us/act/title_9/~chp_3">chapter</ref> to the
extent <ref href="/akn/us/act/title_9/!main ~chp_1">chapter
1</ref> is not in conflict with this <ref href="/akn/us/act/title_9/!main
~chp_3">chapter</ref> or the <ref
href="/akn/us/act/1975__b_35/eng@1975-01-30">Inter-American
Convention</ref> as ratified by the United States.</p>
<block name="sourceCredit"> (Added <ref
href="/akn/us/act/pl_101/369/eng@1990-08-15/~sec_1">Pub. L.
101–369, § 1 , Aug.
15, 1990</ref>, <ref
href="/akn/us/act/stat_104/449">104 Stat. 449</ref> .)
</block>
</content>
</section>
</chapter>
</portionBody>
</portion>
|
Akoma Ntoso is a rich standard so it is possible to apply it
at different levels of compliance.
|
Structure and URIs/IRIs
|
sublevel A
|
Sublevel B
|
Sublevel C
|
Sublevel D
|
|
Level 1 uses the document structure
defined in the Akoma Ntoso specifications (e.g., preface, preamble, body,
conclusion, annexes) for the source as defined in the chapter 8 of this
document (conformance).
|
basic metadata are added
|
normative references are used
|
advanced metadata are added
|
semantic elements are added
|
|
Level 2 uses the document structure and naming convention
of URI/IRI (FRBR metadata) and the IDs according to the AKN naming convention
as defined in Akoma Ntoso Naming Convention Version 1.0, chapter 4 and 5, or
any functionally-equivalent Naming Convention as defined in Akoma Ntoso
Naming Convention Version 1.0, section 4.12.
|
basic metadata are added
|
normative references are used
|
advanced metadata are added
|
semantic elements are added
|
To help bodies find the most suitable subset of the Akoma
Ntoso XML schema for their needs and requirements, a web service has been
created to generate custom sub-schema, that can be accessed from http://akn.web.cs.unibo.it/aknssg/aknssg.html.
Basic metadata correspond to sections:
1. <identification> part with the
FRBR;
2. <publication> part where it
makes sense;
3. Normative
references correspond to all elements using attributes href.
Advanced metadata correspond to elements:
- <lifecycle>
part;
- <analysis>
part;
- <workflow>
part;
- <references>
part.
Semantic elements are to elements:
<date><time>
<person> <organization> <concept> <object>
<event> <location> <process> <role> <term><
quantity> <def><remark> <recordedTime> <vote> <outcome>
<ins> <del> <omissis> <placeholder> <fillIn
<decoration> <docType> <docTitle> <docNumber
<docProponent> <docDate> <legislature> <session>
<shortTitle> <docAuthority> <docPurpose> <docCommittee>
<docIntroducer> <docStage> <docStatus> <docJurisdiction>
<docketNumber> <courtType> <neutralCitation> <party>
<judge> <lawyer> <signature> <opinion> <argument>
Conformance clauses for Akoma Ntoso Version 1.0 can be found
in Akoma Ntoso Version 1.0. Part 2: Specifications, Section 3 Conformance.
(THIS IS INTENDED IN PART 2)
This chapter defines
Akoma Ntoso conformance clauses.
1.
an XML source is compliant with the Akoma Ntoso specifications in
level 1 if
1.
The XML source IS valid against the XML schema: http://docs.oasis-open.org/legaldocml/ns/akn/3.0/xxx;
2.
an XML source is compliant with the Akoma Ntoso specifications in
level 2 if it is compliant at level 1 and if
1.
The values of the eId and wId attributes follows the Akoma Ntoso
naming convention as formulated in chapters 4 and 5 of this document;
2.
The values of the FRBRuri and FBRRthis elements follows the
specification detailed in chapter 4 of the Akoma Ntoso Naming Convention
Version 1.0 or any functionally equivalent naming convention as detailed in
chapter 4.12 of the Akoma Ntoso Naming Convention Version 1.0;
3.
The values of the href and src attributes in ALL elements (except
<a>) follows the specifications detailed in chapter 4 and 5 of the Akoma
Ntoso Naming Convention Version 1.0 or any functionally equivalent naming
convention as detailed in chapter 4.12 of the Akoma Ntoso Naming Convention
Version 1.0.
The following individuals have participated in the creation
of this specification and are gratefully acknowledged:
Participants:
Aisenberg, Michael, Mitre Corporation
Arocena, María de la Paz, Uruguay Parliament
Barysheva, Nataliya, LexisNexis a Division of
Reed Elsevier
Bbaale, Fred, Uganda Parliament
Beatch, Richard, Bloomberg
Finance L.P.
Bennett, Daniel, Individual Member
Briotti, Giuseppe, Senato della
Repubblica d’Italia
Bruce, Tom, Cornell Law School,
Legal Information Institute
Cabral, James, MTG Management
Consultants, LLC.
Dohaini, Bassel, Lebanese Parliament
Dunning, John, LexisNexis a
Division of Reed Elsevier
Fabiani, Claudio, EU Parliament
Ferguson, Kimberly, Library of
Congress
Ferreira, Daniel, Uruguay
Parliament
Fiagome, Shirley-Ann, Ghana
Parliament
Gheen, Tina, Library of
Congress
Greenwood, Dazza, M.I.T.
Hardjono, Thoma, M.I.T.
Hariharan, Ashok, Africa
i-Parliaments Action Plan (UN/DESA)
Harris, Jim, National Center
for State Courts
Joergensen, John, Cornell Law
School, Legal Information Institute
Junge, Peter, Beijing Sursen
Electronic Technology Co, Ltd.
Khamis, Mr. Maan, LexisNexis a
Division of Reed Elsevier
Marchetti, Carlo, Senato della
Repubblica d’Italia
Mattocks, Carl, Individual
Member
Murungi, Michael, Kenya
National Council for Law Reporting
Otto Eridan, Biblioteca del
Congreso Nacional de Chile
Palmirani, Monica, University of
Bologna
Parisse, Véronique, Aubay S.A.
Petri, Steve, LexisNexis a
Division of Reed Elsevier
Pham, Kim, US Military Health
Services
Ramsahye-Rakha, Saseeta, Mauritius
National Assembly
Sandoval, Alvaro, Biblioteca
del Congreso Nacional de Chile
Shifrin, Laurel, LexisNexis a
Division of Reed Elsevier
Sifaqui, Christian, Biblioteca
del Congreso Nacional de Chile
Sosa, Raquel, Uruguay
Parliament
Sperberg, Roger, LexisNexis a
Division of Reed Elsevier
Tosar Piaggio, Sylvia, Uruguay
Parliament
Vergottini, Grant, Xcential Group,
LLC.
Vitali, Fabio, University of Bologna
Waldt, Dale, LexisNexis a
Division of Reed Elsevier
Weber, Andrew, Library of
Congress
Wemer, Jason, Wells Fargo
Wintermann, John, Bloomberg
Finance L.P.
Zeni, Flavio, Africa i-Parliaments
Action Plan (UN/DESA)
|
Revision
|
Date
|
Editor
|
Changes Made
|
|
[01]
|
[06 February 2013]
|
[Monica Palmirani]
|
[Editing of the first
version]
|
|
[02]
|
[22 March 2013]
|
[Roger Sperberg]
|
[English revision]
|
|
[03]
|
[30 October 2013]
|
[Grant Vergottini]
|
[Inclusion of the sessions
2]
|
|
[04]
|
[20 May 2014]
|
[Veronique Parisse]
|
[Inclusion of the sessions
7]
|
|
[05]
|
[27 August 2014]
|
[Monica Palmirani]
|
[Formatting and inclusion of
sessions 5.7]
|
|
[06]
|
[4 September 2014]
|
[Grant Vergottini]
|
[English revision]
|
|
[07]
|
[5 September 2014]
|
[Veronique Parisse]
|
[Revision of the content and
some additional editing]
|
|
[08]
|
[5 September 2014]
|
[Monica Palmirani]
|
[Inclusion of examples 6.4
and 6.6, some other information concerning the structure of the partitions.]
|
|
[09]
|
[9 September 2014]
|
[Monica Palmirani]
|
[Inclusion of some comments
from the Summer School LEX2014 brain storming.]
|
|
[10]
|
[17 September 2014]
|
[Veronique Parisse]
|
[Minor errors in the syntax
examples]
|
|
[11]
|
[22 December 2014]
|
[Monica Palmirani]
|
[Updating of the number of
the CSD11 into CSD12 and the date]
|
|
[12]
|
[08 January 2015]
|
[Monica Palmirani]
|
[Updating the content
according with the CSD13]
|
|
[13]
|
[12 January 2015]
|
[Grant Vergottini]
|
[English revision paragraph
6.7]
|
|
[14]
|
[13 January 2015]
|
[Veronique Parisse
|
[some typos in the eId and
some inclusion of tilde syntax in the internal and external uri]
|
|
[15]
|
[14 January 2015]
|
[Jeason Wemer]
|
[editorial revision]
|
|
[16]
|
[14 January 2015]
|
[Monica Palmirani]
|
[consolidation of all the
revisions]
|
|
[17]
|
[02 July 2015]
|
[Monica Palmirani]
|
[consolidation of some
comments]
|
|
[18]
|
[17 December 2015]
|
[Monica Palmirani]
|
|
|
[19]
|
[23 December 2015]
|
[Grant Vergottini]
|
[English revision of latest
edits]
|
|
[20]
|
[31 March 2016]
|
[Monica Palmirani]
|
[New part related
presentation, proprietary, preservation, foreign, ELI/ECLI/URN:LEX]
|
|
[21]
|
[22 September 2016]
|
[Monica Palmirani]
|
Conformance Rules
|
|
[22]
|
[9 October 2016]
|
[Ashok Hariharan]
|
Linguistic revision
|
|
[23]
|
[11 January 2017]
|
[Monica Palmirani]
|
Final revision
|
|
[24]
|
[18 January 2017]
|
[Monica Palmirani]
|
Inclusion of comments coming
from Flavio Zeni (UN), Maria Kardami (European OP), Veronique Parisse,
Pascalina Psyrra (European Dynamics SA)
|
|
[25]
|
[1 February 2017]
|
[Monica Palmirani]
|
Inclusion of comments coming
from Veronique Parisse, Thomas Uttenthaler (European Dynamics SA), Anders R.
Thorbeck (Knowit)
|
|
[26]
|
[24 March 2017]
|
[Monica Palmirani, Fabio
Vitali]
|
Inclusion of better
definitions of <documentRef> and <componentRef>, correction of
typos in <lifecycle> definition. Comments coming from
Ashok Heriharan, Monica Palmirani, Fabio Vitali, Flavio Zeni (UN).
|
|
[27]
|
[4 April 2017]
|
[Veronique Parisse, Monica
Palmirani]
|
Modification of this
sentence "Attachments can also be another act or international agreement
that is approved by this act." into the following
"Attachments or others
types of Components can also be another act or international agreement that
is approved by this act."
|
|
[28]
|
[17 May 2017]
|
[Monica Palmirani]
|
Modification of 4.3.3 for a
typos.
Modification of 5.6 for a
typos.
Modified the namespace http://docs.oasis-open.org/legaldocml/ns/akn/3.0
|


