
Open Document Format for Office Applications (OpenDocument) Version 1.2
Part 2: Recalculated Formula (OpenFormula) Format
Committee Specification Draft 06
2 December 2010
Specification URIs:
This Version:
http://docs.oasis-open.org/office/v1.2/csd06/OpenDocument-v1.2-csd06-part2.odt (Authoritative)
http://docs.oasis-open.org/office/v1.2/csd06/OpenDocument-v1.2-csd06-part2.pdf
http://docs.oasis-open.org/office/v1.2/csd06/OpenDocument-v1.2-csd06-part2.html
Previous Version:
http://docs.oasis-open.org/office/v1.2/cd05/OpenDocument-v1.2-cd05-part2.odt (Authoritative)
http://docs.oasis-open.org/office/v1.2/cd05/OpenDocument-v1.2-cd05-part2.pdf
http://docs.oasis-open.org/office/v1.2/cd05/OpenDocument-v1.2-cd05-part2.html
Latest Version:
http://docs.oasis-open.org/office/v1.2/OpenDocument-v1.2-part2.odt
http://docs.oasis-open.org/office/v1.2/OpenDocument-v1.2-part2.pdf
http://docs.oasis-open.org/office/v1.2/OpenDocument-v1.2-part2.html
Technical Committee:
OASIS Open Document Format for Office Applications (OpenDocument) TC
Chairs:
Robert Weir, IBM
Michael Brauer, Oracle Corporation
Editors:
David A. Wheeler <dwheeler@dwheeler.com>,
Patrick Durusau <patrick@durusau.net>
Eike Rathke, Oracle Corporation <erack@sun.com>
Robert Weir, IBM <robert_weir@us.ibm.com>
Related Work:
This document is part of the OASIS Open Document Format for Office Applications (OpenDocument) Version 1.2 specification.
The OpenDocument v1.2 specification has these parts:
OpenDocument v1.2 part 1: OpenDocument Schema
OpenDocument v1.2 part 2 (this part): Recalculated Formula (OpenFormula) Format
OpenDocument v1.2 part 3: Packages
Declared XML Namespaces:
None.
Abstract:
This document is part of the Open Document Format for Office Applications (OpenDocument) Version 1.2 specification.
It defines a formula language to be used in OpenDocument documents.
Status:
This document was last revised or approved by the OASIS Open Document Format for Office Applications (OpenDocument) Technical Committee on the above date. The level of approval is also listed above. Check the current location noted above for possible later revisions of this document. This document is updated periodically on no particular schedule.
Technical Committee members should send comments on this specification to the Technical Committee's email list. Others should send comments to the Technical Committee by using the "Send A Comment" button on the Technical Committee's web page at www.oasis-open.org/committees/office.
For information on whether any patents have been disclosed that may be essential to implementing this specification, and any offers of patent licensing terms, please refer to the Intellectual Property Rights section of the Technical Committee web page (www.oasis-open.org/committees/office/ipr.php).
Notices
Copyright © OASIS® 2002–2010. All Rights Reserved.
All capitalized terms in the following text have the meanings assigned to them in the OASIS Intellectual Property Rights Policy (the "OASIS IPR Policy"). The full Policy may be found at the OASIS website.
This document and translations of it may be copied and furnished to others, and derivative works that comment on or otherwise explain it or assist in its implementation may be prepared, copied, published, and distributed, in whole or in part, without restriction of any kind, provided that the above copyright notice and this section are included on all such copies and derivative works. However, this document itself may not be modified in any way, including by removing the copyright notice or references to OASIS, except as needed for the purpose of developing any document or deliverable produced by an OASIS Technical Committee (in which case the rules applicable to copyrights, as set forth in the OASIS IPR Policy, must be followed) or as required to translate it into languages other than English.
The limited permissions granted above are perpetual and will not be revoked by OASIS or its successors or assigns.
This document and the information contained herein is provided on an "AS IS" basis and OASIS DISCLAIMS ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT INFRINGE ANY OWNERSHIP RIGHTS OR ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE.
OASIS requests that any OASIS Party or any other party that believes it has patent claims that would necessarily be infringed by implementations of this OASIS Committee Specification or OASIS Standard, to notify OASIS TC Administrator and provide an indication of its willingness to grant patent licenses to such patent claims in a manner consistent with the IPR Mode of the OASIS Technical Committee that produced this specification.
OASIS invites any party to contact the OASIS TC Administrator if it is aware of a claim of ownership of any patent claims that would necessarily be infringed by implementations of this specification by a patent holder that is not willing to provide a license to such patent claims in a manner consistent with the IPR Mode of the OASIS Technical Committee that produced this specification. OASIS may include such claims on its website, but disclaims any obligation to do so.
OASIS takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on OASIS' procedures with respect to rights in any document or deliverable produced by an OASIS Technical Committee can be found on the OASIS website. Copies of claims of rights made available for publication and any assurances of licenses to be made available, or the result of an attempt made to obtain a general license or permission for the use of such proprietary rights by implementers or users of this OASIS Committee Specification or OASIS Standard, can be obtained from the OASIS TC Administrator. OASIS makes no representation that any information or list of intellectual property rights will at any time be complete, or that any claims in such list are, in fact, Essential Claims.
The names "OASIS", “OpenDocument”, “Open Document Format” and “ODF” are trademarks of OASIS, the owner and developer of this specification, and should be used only to refer to the organization and its official outputs. OASIS welcomes reference to, and implementation and use of, specifications, while reserving the right to enforce its marks against misleading uses. Please see http://www.oasis-open.org/who/trademark.php for above guidance.
Table of Contents
This document is part of the Open Document Format for Office Applications (OpenDocument) Version 1.2 specification. It defines a formula language for OpenDocument documents, which is also called OpenFormula.
OpenFormula is a specification of an open format for exchanging recalculated formulas between office applications, in particular, formulas in spreadsheet documents. OpenFormula defines data types, syntax, and semantics for recalculated formulas, including predefined functions and operations.
Using OpenFormula allows document creators to change the office application they use, exchange formulas with others (who may use a different application), and access formulas far in the future, with confidence that the recalculated formulas in their documents will produce equivalent results if given equivalent inputs.
OpenFormula is intended to be a supporting document to the Open Document Format for Office Applications (OpenDocument) format, particularly for defining its attributes table:formula and text:formula. It can also be used in other circumstances where a simple, easy-to-read infix text notation is desired for exchanging recalculated formulas.
All text is normative unless otherwise labeled.
Within the normative text of this specification, the terms "shall", "shall not", "should", "should not", "may" and “need not” are to be interpreted as described in Annex H of [ISO/IEC Directives].
OpenFormula defines:
1.data types
2.syntax
3.semantics
for recalculated formulas.
OpenFormula also defines functions.
OpenFormula does not define:
1.a user interface
2.a general notation for mathematical expressions
[CharModel] Character Model for the World Wide Web 1.0: Fundamentals, http://www.w3.org/TR/2005/REC-charmod-20050215/, W3C, 2005. |
[ISO/IEC Directives] Rules for the structure and drafting of International Standards, International Organization for Standardization and International Electrotechnical Commission, 2004. |
[ISO4217] Codes for the representation of currencies and funds, International Organization for Standardization and International Electrotechnical Commission, 2008. |
[ISO8601] Data elements and interchange formats -- Information interchange -- Representation of dates and times, International Organization for Standardization and International Electrotechnical Commission, 2004. |
[RFC3987] Internationalized Resource Identifiers (IRIs), http://www.ietf.org/rfc/rfc3987.txt, IETF, 2005. |
[UNICODE] The Unicode Standard, Version 5.2 (Mountain View, CA, The Unicode Consortium, 2009. ISBN 978-1-936213-00-9). (http://www.unicode.org/versions/Unicode5.2.0/). |
[UTR15] Mark Davis, Martin Dürst, Unicode Normalization Forms, Unicode Technical Report #15, http://www.unicode.org/reports/tr15/tr15-25.html, 2005. |
[XML1.0] Extensible Markup Language (XML) 1.0 (Fourth Edition), http://www.w3.org/TR/2006/REC-xml-20060816/, W3C, 2006. |
[JISX0201] JIS X 0201 (1976) to Unicode 1.1 Table, 1994, http://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0201.TXT. |
[JISX0208] JIS X 0208 (1990) to Unicode, 1994, http://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT. |
[UAX11] Asmus Freytag, East Asian Width, Unicode Standard Annex #11, http://www.unicode.org/reports/tr11/tr11-19.html, 2009. |
The OpenDocument specification defines conformance for formula expressions and evaluators. For evaluators, there are three groups of features that an evaluator may support. This chapter defines the basic requirements for the individual conformance targets.
An OpenDocument formula expression shall adhere to the expression syntax defined in chapter 4. It may use subsets or supersets of OpenFormula.
An OpenDocument Formula Evaluator is a program that can parse and recalculate OpenDocument formula expressions, and that meets the following additional requirements:
A)It may implement subsets or supersets of this specification.
B)It shall conform to one of: (C16) OpenDocument Formula Small Group Evaluator, (C17) OpenDocument Formula Medium Group Evaluator or (C18) OpenDocument Formula Large Group Evaluator
C)It may implement additional functions beyond those defined in this specification. It may further implement additional formula syntax, additional operations, additional optional parameters for functions, or may consider function parameters to be optional when they are required by this specification.
D)Applications should clearly document their extensions in their user documentation, both online and paper, in a manner so users would be likely to be aware when they are using a non-standard extension.
Note 1: An expression may reference a nonstandard function by name, or depend on implementation-defined behavior, or on semantics not guaranteed by this specification. Reference to or dependence upon functions or behavior not defined by this standard may impair the interoperability of the resulting expression(s).
Note 2: This specification defines formulas in terms of a canonical text representation used for exchange. If formulas are contained in XML attributes some characters shall be escaped as required by the XML specification (e.g., the character & shall be escaped in XML attributes using notations such as &). All string and character literals references by this specification are in the value space defined by [UNICODE] thus, “A” is U+0041, “Z” is U+005A, and the range of characters “A-Z” is the range U+0041 through U+005A inclusive.
An OpenDocument Formula Small Group Evaluator is an OpenDocument Formula Evaluator that meets the following additional requirements:
A)It shall implement at least the limits defined in the “Basic Limits” section.
B)It shall implement the syntax defined in these sections on syntax: Criteria; Basic Expressions; Constant Numbers; Constant Strings; Operators; Functions and Function Parameters; Nonstandard Function Names; References; Simple Named Expressions; Errors; Whitespace.
C)It shall implement all implicit conversions for the types it implements, at least Text, Conversion to Number, Reference, Conversion to Logical, and Error.
D)It shall implement the following operators (which are all the operators except reference union (~)): Infix Operator Ordered Comparison ("<", "<=", ">", ">="); Infix Operator "&”; Infix Operator "+”; Infix Operator "-”; Infix Operator "*”; Infix Operator "/”; Infix Operator "^”; Infix Operator "=”; Infix Operator "<>”; Postfix Operator “%”; Prefix Operator “+”; Prefix Operator “-”; Infix Operator Reference Intersection ("!"); Infix Operator Range (":").
E)It shall implement at least the following functions as defined in this specification: ABS 6.16.2 ; ACOS 6.16.3 ; AND 6.15.2 ; ASIN 6.16.7 ; ATAN 6.16.9 ; ATAN2 6.16.10 ; AVERAGE 6.18.3 ; AVERAGEIF 6.18.5 ; CHOOSE 6.14.3 ; COLUMNS 6.13.5 ; COS 6.16.19 ; COUNT 6.13.6 ; COUNTA 6.13.7 ; COUNTBLANK 6.13.8 ; COUNTIF 6.13.9 ; DATE 6.10.2 ; DAVERAGE 6.9.2 ; DAY 6.10.5 ; DCOUNT 6.9.3 ; DCOUNTA 6.9.4 ; DDB 6.12.14 ; DEGREES 6.16.25 ; DGET 6.9.5 ; DMAX 6.9.6 ; DMIN 6.9.7 ; DPRODUCT 6.9.8 ; DSTDEV 6.9.9 ; DSTDEVP 6.9.10 ; DSUM 6.9.11 ; DVAR 6.9.12 ; DVARP 6.9.13 ; EVEN 6.16.30 ; EXACT 6.20.8 ; EXP 6.16.31 ; FACT 6.16.32 ; FALSE 6.15.3 ; FIND 6.20.9 ; FV 6.12.20 ; HLOOKUP 6.14.5 ; HOUR 6.10.10 ; IF 6.15.4 ; INDEX 6.14.6 ; INT 6.17.2 ; IRR 6.12.24 ; ISBLANK 6.13.14 ; ISERR 6.13.15 ; ISERROR 6.13.16 ; ISLOGICAL 6.13.19 ; ISNA 6.13.20 ; ISNONTEXT 6.13.21 ; ISNUMBER 6.13.22 ; ISTEXT 6.13.25 ; LEFT 6.20.12 ; LEN 6.20.13 ; LN 6.16.39 ; LOG 6.16.40 ; LOG10 6.16.41 ; LOWER 6.20.14 ; MATCH 6.14.9 ; MAX 6.18.45 ; MID 6.20.15 ; MIN 6.18.48 ; MINUTE 6.10.12 ; MOD 6.16.42 ; MONTH 6.10.13 ; N 6.13.26 ; NA 6.13.27 ; NOT 6.15.7 ; NOW 6.10.15 ; NPER 6.12.29 ; NPV 6.12.30 ; ODD 6.16.44 ; OR 6.15.8 ; PI 6.16.45 ; PMT 6.12.36 ; POWER 6.16.46 ; PRODUCT 6.16.47 ; PROPER 6.20.16 ; PV 6.12.41 ; RADIANS 6.16.49 ; RATE 6.12.42 ; REPLACE 6.20.17 ; REPT 6.20.18 ; RIGHT 6.20.19 ; ROUND 6.17.5 ; ROWS 6.13.30 ; SECOND 6.10.16 ; SIN 6.16.55 ; SLN 6.12.45 ; SQRT 6.16.58 ; STDEV 6.18.72 ; STDEVP 6.18.74 ; SUBSTITUTE 6.20.21 ; SUM 6.16.61 ; SUMIF 6.16.62 ; SYD 6.12.46 ; T 6.20.22 ; TAN 6.16.69 ; TIME 6.10.17 ; TODAY 6.10.19 ; TRIM 6.20.24 ; TRUE 6.15.9 ; TRUNC 6.17.8 ; UPPER 6.20.27 ; VALUE 6.13.34 ; VAR 6.18.82 ; VARP 6.18.84 ; VLOOKUP 6.14.12 ; WEEKDAY 6.10.20 ; YEAR 6.10.23
F)It need not evaluate references that contain more than one area.
G)It need not implement inline arrays, complex numbers, and the reference union operator.
Note: This specification does not mandate a user interface for international characters, so a resource-constrained application may choose to not show the traditional glyph (e.g., it may show the [UNICODE] numeric code instead).
An OpenDocument Formula Medium Group Evaluator is an OpenDocument Small Group Formula Evaluator that meets the following additional requirements:
A)It shall implement the following functions as defined in this specification: ACCRINT 6.12.2 ; ACCRINTM 6.12.3 ; ACOSH 6.16.4 ; ACOT 6.16.5 ; ACOTH 6.16.6 ; ADDRESS 6.14.2 ; ASINH 6.16.8 ; ATANH 6.16.11 ; AVEDEV 6.18.2 ; BESSELI 6.16.12 ; BESSELJ 6.16.13 ; BESSELK 6.16.14 ; BESSELY 6.16.15 ; BETADIST 6.18.7 ; BETAINV 6.18.8 ; BINOMDIST 6.18.10 ; CEILING 6.17.1 ; CHAR 6.20.3 ; CLEAN 6.20.4 ; CODE 6.20.5 ; COLUMN 6.13.4 ; COMBIN 6.16.16 ; CONCATENATE 6.20.6 ; CONFIDENCE 6.18.16 ; CONVERT 6.16.18 ; CORREL 6.18.17 ; COSH 6.16.20 ; COT 6.16.21 ; COTH 6.16.22 ; COUPDAYBS 6.12.5 ; COUPDAYS 6.12.6 ; COUPDAYSNC 6.12.7 ; COUPNCD 6.12.7 ; COUPNUM 6.12.9 ; COUPPCD 6.12.10 ; COVAR 6.18.18 ; CRITBINOM 6.18.19 ; CUMIPMT 6.12.11 ; CUMPRINC 6.12.12 ; DATEVALUE 6.10.4 ; DAYS360 6.10.7 ; DB 6.12.13 ; DEVSQ 6.18.20 ; DISC 6.12.15 ; DOLLARDE 6.12.16 ; DOLLARFR 6.12.17 ; DURATION 6.12.18 ; EFFECT 6.12.19 ; EOMONTH 6.10.9 ; ERF 6.16.27 ; ERFC 6.16.28 ; EXPONDIST 6.18.21 ; FISHER 6.18.26 ; FISHERINV 6.18.27 ; FIXED 6.20.10 ; FLOOR 6.17.3 ; FORECAST 6.18.28 ; FTEST 6.18.30 ; GAMMADIST 6.18.31 ; GAMMAINV 6.18.32 ; GAMMALN 6.16.35 ; GCD 6.16.36 ; GEOMEAN 6.18.34 ; HARMEAN 6.18.36 ; HYPGEOMDIST 6.18.37 ; INTERCEPT 6.18.38 ; INTRATE 6.12.22 ; ISEVEN 6.13.17 ; ISODD 6.13.23 ; ISOWEEKNUM 6.10.11 ; KURT 6.18.39 ; LARGE 6.18.40 ; LCM 6.16.38 ; LEGACY.CHIDIST 6.18.11 ; LEGACY.CHIINV 6.18.13 ; LEGACY.CHITEST 6.18.15 ; LEGACY.FDIST 6.18.23 ; LEGACY.FINV 6.18.25 ; LEGACY.NORMSDIST 6.18.54 ; LEGACY.NORMSINV 6.18.55 ; LEGACY.TDIST 6.18.77 ; LINEST 6.18.41 ; LOGEST 6.18.42 ; LOGINV 6.18.43 ; LOGNORMDIST 6.18.44 ; LOOKUP 6.14.8 ; MDURATION 6.12.26 ; MEDIAN 6.18.47 ; MINVERSE 6.5.3 ; MIRR 6.12.27 ; MMULT 6.5.4 ; MODE 6.18.50 ; MROUND 6.17.4 ; MULTINOMIAL 6.16.43 ; NEGBINOMDIST 6.18.51 ; NETWORKDAYS 6.10.14 ; NOMINAL 6.12.28 ; ODDFPRICE 6.12.31 ; ODDFYIELD 6.12.32 ; ODDLPRICE 6.12.33 ; ODDLYIELD 6.12.34 ; OFFSET 6.14.11 ; PEARSON 6.18.56 ; PERCENTILE 6.18.57 ; PERCENTRANK 6.18.58 ; PERMUT 6.18.59 ; POISSON 6.18.62 ; PRICE 6.12.38 ; PRICEMAT 6.12.40 ; PROB 6.18.63 ; QUARTILE 6.18.64 ; QUOTIENT 6.16.48 ; RAND 6.16.50 ; RANDBETWEEN 6.16.51 ; RANK 6.18.65 ; RECEIVED 6.12.43 ; ROMAN 6.19.17 ; ROUNDDOWN 6.17.6 ; ROUNDUP 6.17.7 ; ROW 6.13.29 ; RSQ 6.18.66 ; SERIESSUM 6.16.53 ; SIGN 6.16.54 ; SINH 6.16.56 ; SKEW 6.18.67 ; SKEWP 6.18.68 ; SLOPE 6.18.69 ; SMALL 6.18.70 ; SQRTPI 6.16.59 ; STANDARDIZE 6.18.71 ; STDEVA 6.18.73 ; STDEVPA 6.18.75 ; STEYX 6.18.76 ; SUBTOTAL 6.16.60 ; SUMPRODUCT 6.16.64 ; SUMSQ 6.16.65 ; SUMX2MY2 6.16.66 ; SUMX2PY2 6.16.67 ; SUMXMY2 6.16.68 ; TANH 6.16.70 ; TBILLEQ 6.12.47 ; TBILLPRICE 6.12.48 ; TBILLYIELD 6.12.49 ; TIMEVALUE 6.10.18 ; TINV 6.18.78 ; TRANSPOSE 6.5.6 ; TREND 6.18.79 ; TRIMMEAN 6.18.80 ; TTEST 6.18.81 ; TYPE 6.13.33 ; VARA 6.18.83 ; VDB 6.12.50 ; WEEKNUM 6.10.21 ; WEIBULL 6.18.86 ; WORKDAY 6.10.22 ; XIRR 6.12.51 ; XNPV 6.12.52 ; YEARFRAC 6.10.24 ; YIELD 6.12.53 ; YIELDDISC 6.12.54 ; YIELDMAT 6.12.55 ; ZTEST 6.18.87
B)It shall implement the Infix Operator Reference Union ("~") 6.4.13
C)It shall evaluate references with more than one area.
An OpenDocument Formula Large Group Evaluator is an OpenDocument Medium Group Formula Evaluator that meets the following additional requirements:
A)It shall implement the syntax defined in these sections on syntax: Inline Arrays; Automatic Intersection; External Named Expressions.
B)It shall implement the complex number type as discussed in the section on Complex Number, array formulas, and Sheet-local Named Expressions.
It shall implement the following functions as defined in this specification: AMORLINC 6.12.4 ; ARABIC 6.19.2 ; AREAS 6.13.2 ; ASC 6.20.2 ; AVERAGEA 6.18.4 ; AVERAGEIFS 6.18.6 ; BASE 6.19.3 ; BIN2DEC 6.19.4 ; BIN2HEX 6.19.5 ; BIN2OCT 6.19.6 ; BINOM.DIST.RANGE 6.18.9 ; BITAND 6.6.2 ; BITLSHIFT 6.6.3 ; BITOR 6.6.4 ; BITRSHIFT 6.6.5 ; BITXOR 6.6.6 ; CHISQDIST 6.18.12 ; CHISQINV 6.18.14 ; COMBINA 6.16.17 ; COMPLEX 6.8.2 ; COUNTIFS 6.13.10 ; CSC 6.16.23 ; 6.16.23CSCH 6.16.24 ; DATEDIF 6.10.3 ; DAYS 6.10.6 ; DDE 6.11.2 ; DEC2BIN 6.19.7 ; DEC2HEX 6.19.8 ; DEC2OCT 6.19.9 ; DECIMAL 6.19.10 ; DELTA 6.16.26 ; EDATE 6.10.8 ; ERROR.TYPE 6.13.11; EUROCONVERT 6.16.29 ; FACTDOUBLE 6.16.33 ; FDIST 6.18.22 ; FINDB 6.7.2 ; FINV 6.18.24 ; FORMULA 6.13.12 ; FREQUENCY 6.18.29 ; FVSCHEDULE 6.12.21 ; GAMMA 6.16.34 ; GAUSS 6.18.33 ; GESTEP 6.16.37 ; GETPIVOTDATA 6.14.4 ; GROWTH 6.18.35 ; HEX2BIN 6.19.11 ; HEX2DEC 6.19.12 ; HEX2OCT 6.19.13 ; HYPERLINK 6.11.3 ; IFERROR 6.15.5 ; IFNA 6.15.6 ; IMABS 6.8.3 ; IMAGINARY 6.8.4 ; IMARGUMENT 6.8.5 ; IMCONJUGATE 6.8.6 ; IMCOS 6.8.7 ; IMCOT 6.8.9 ; IMCSC 6.8.10 ; IMCSCH 6.8.11 ; IMDIV 6.8.12 ; IMEXP 6.8.13 ; IMLN 6.8.14 ; IMLOG10 6.8.15 ; IMLOG2 6.8.16 ; IMPOWER 6.8.17 ; IMPRODUCT 6.8.18 ; IMREAL 6.8.19 ; IMSEC 6.8.22 ; IMSECH 6.8.23 ; IMSIN 6.8.20 ; IMSQRT 6.8.24 ; IMSUB 6.8.25 ; IMSUM 6.8.26 ; IMTAN 6.8.27; INDIRECT 6.14.7 ; INFO 6.13.13 ; IPMT 6.12.23 ; ISFORMULA 6.13.18 ; ISPMT 6.12.25 ; ISREF 6.13.24 ; JIS 6.20.11 ; LEFTB 6.7.3 ; LENB 6.7.4 ; MAXA 6.18.46 ; MDETERM 6.5.2 ; MULTIPLE.OPERATIONS 6.14.10 ; MUNIT 6.5.5 ; MIDB 6.7.5 ; MINA 6.18.49 ; NORMDIST 6.18.52 ; NORMINV 6.18.53 ; NUMBERVALUE 6.13.28 ; OCT2BIN 6.19.14 ; OCT2DEC 6.19.15 ; OCT2HEX 6.19.16 ; PDURATION 6.12.35 ; PERMUTATIONA 6.18.60 ; PHI 6.18.61 ; PPMT 6.12.37 ; PRICEDISC 6.12.39 ; REPLACEB 6.7.6 ; RIGHTB 6.7.7 ; RRI 6.12.44 ; SEARCH 6.20.20 ; SEARCHB 6.7.8 ; SEC 6.16.52 ; SECH 6.16.57 ; SHEET 6.13.31 ; SHEETS 6.13.32 ; SUMIFS 6.16.63 ; TEXT 6.20.23 ; UNICHAR 6.20.25 ; UNICODE 6.20.26 ; VARPA 6.18.85 ; XOR 6.15.10
Note: The following functions are documented by this specification, but not included even in the Large group:CELL 6.13.3 ; DOLLAR 6.20.7
Applications should document all implementation-defined and variances from this standard in a manner that the application users can obtain the information.
In a few cases a specific approach is required (e.g., string indexes begin at one), which may be different than the user interface of some implementations.
In practice, for nearly all documents the differences are irrelevant. The primary variances and differences from OpenFormula and some existing applications are:
●Some conversions between types are not required to be automatic. In particular, applications may, but need not, perform automatic conversion of text in a cell when it is to be used as a number (see Auto Text to Number).
●There need not be a distinguishable Logical type. Applications may have a Logical type distinct from Number (see Distinct Logical), but Logical values may also be represented by the Number type using the values 1 (True) and 0 (False). This means that functions that take number sequences (such as SUM) may or may not include true and false values in the sequence.
●Applications vary on the set of Errors they support. In this specification. The only distinguished Error is #N/A; all other errors are simply errors, allowing applications to choose the Error set that best meets their needs.
●In this specification, string index positions start from 1. Users of applications with string index positions starting from 0 shall add and subtract 1 on import/export of this format, as appropriate.
●Database criteria match patterns (such as the pattern matching language for text) have historically varied: Some support glob syntax (e.g., a*b is a, followed by 0 or more characters, followed by b), while others support traditional regular expression syntax (e.g., a*b is zero or more a’s, followed by b). This specification supports both pattern languages.
Note: Interoperability is improved by the use of the DATE and TIME functions or the textual [ISO8601] date representation because dates in that format do not rely upon epoch or locale-specific settings.
In an OpenDocument file, calculation settings impact formula recalculation, which can be the same or different from a particular application's defaults. These include whether or not text comparisons are case-sensitive, or if search criteria shall apply to the whole cell.
This section describes the basic formula processing model: how expressions are calculated, when recalculation occurs, and limits on formulas.
OpenFormula defines rules for the evaluation of expressions as well as the functions and operators that appear in expressions.
Expressions in OpenFormula shall be evaluated by application of the following rules:
1)If an expression consists of a constant Number (5.3), a constant String (5.4), a Reference (5.8), constant Error (per section 5.12), the value of that type is returned.
2)If an expression consists of one or more operations, apply the operators in order of precedence and associativity as defined by Table 1 in 5.5 (Operators). Precedence of operators may be altered by the use of "(" (LEFT PARENTHESES, U+0028) and ")" (RIGHT PARENTHESES, U+0029) to group operators. Evaluate the operator as described in Operator and Function Evaluation, 3.2.3.
3)If an expression consists of a function call (5.6, 5.7), evaluate the function as described in Operator and Function Evaluation, 3.2.3.
4)If an expression consists of a named expression (5.11), the result of evaluating the named expression is returned.
5)If an expression consists of a QuotedLabel (5.10), AutomaticIntersection (5.10.6), or Array (5.13), its value is returned. Expression Syntax 5
Once evaluation has completed:
1)If the result is a Reference and a single non-reference value is needed, it is converted to the referenced value, using the rules of Non-Scalar Evaluation, 3.3, 1.2.
2)If the result an Array, for the display area, apply the rules of Non-Scalar Evaluation, 3.3, 1.1.
Operators and functions in OpenFormula shall be evaluated according to their definitions by applying the following rules:
1)The value of all expression arguments are computed. Exceptions to computation of all arguments are noted in a function's specification.
Note: The practice of computing all argument expressions is known as "eager" evaluation. The IF function is an example of a function that does not require computation of all arguments.
2)If an argument expression evaluates to Error, calculation of the operator or function may short-circuit and return the Error if the function does not suppress error propagation as noted in the function's specification.
3)If an operator or function is passed a value of incorrect type, call the appropriate implicit conversion function to convert the value to the correct type. If conversion is not possible, generate an Error.
4)The function or operation is called with its argument expressions' results, and the result of the function or operation is the evaluation of the expression.
Non-scalar values passed as arguments to functions are evaluated by intersection or iteration.
1)Evaluation as an implicit intersection of the argument with the expression's evaluation position.
1.1)Inline Arrays
Element (0;0) of the array is used in place of the array.
Note 1:
=ABS({-3;-4}) => ABS(-3) // row vector
=ABS({-3|-4}) => ABS(-3) // column vector
=ABS({-3;-4|-6;-8}) => ABS(-3) // matrix
={1;2;3|4;5;6} => 1 // simple display
1.2)References
1.2.1)If the target reference is a row-vector (Nx1) use the value at the intersection of the evaluation position's column and the reference's row.
Note 2:
in cell B2 : =ABS(A1:C1) => ABS(B1)
If there is no intersection the result is #VALUE!
Note 3: in cell D4 : =ABS(A1:C1) => #VALUE!
1.2.2)If the target reference is a column-vector (1xM) the value at the intersection of the evaluation position's row and the reference's column.
Note 4:
in cell B2 : =ABS(A1:A3) => ABS(A2)
in cell D4 : =ABS(A1:A3) => #VALUE!
2)Matrix evaluation.
If an expression is being evaluated in a cell flagged as a being part of a 'Matrix' (OpenDocument 8.1.3 table:number-matrix-columns-spanned):
2.1)The portion of a non-scalar result to be displayed may not be co-extensive with a specified display area. The portion of the non-scalar result to be displayed is determined by:
2.1.1)If the position to be displayed exists in the result, display that position.
2.1.2)If the non-scalar result is 1 column wide, subsequent columns in the display area display the value in the first column. This applies to
- scalars '3'
- singletons '{3}'
- column vectors '{1|2|3}'
2.1.3)If the non-scalar result is 1 row high, subsequent rows in the display area use the value of the first row. This applies to
- scalars '3'
- singletons '{3}'
- row vectors '{1;2;3}'
2.1.4)If none of the other rules apply #N/A
Note 5:
in matrix A1:B3 with ={1;2|3;4|5;6} : cell B2 contains 4. [Rule 2.1.1]
in matrix A1:B3 with ={1|3|5} : cell B2 contains 3. [Rule 2.1.1 for row, and Rule 2.1.2 column]
in matrix A1:B3 with ={2;4} : cell B2 contains 4. [Rule 2.1.3 for row, and Rule 2.1.1 column]
in matrix A1:C4 with ={1;2|3;4|5;6} : cell C1,A4 contain #N/A. [Rule 2.1.4]
Note 6: if a value is not requested it is not displayed
in matrix A1:B2 with ={1;2|3;4|5;6} : the value '6' is not displayed because B3 is not part of the display matrix.
2.2)Calculations with non-scalar inputs are a generalization of (2.1).
When evaluating a formula in 'matrix' mode, and a non-scalar value is passed to a function argument that expects a scalar, the function is evaluated multiple times, iterating over the non-scalar input(s) and putting the function result into a matrix at the position corresponding to the input. Unary/Binary operators, other than range and union, follow the rules for scalar functions when passed non-scalar values.
Inline arrays and references are interchangeable.
2.2.1)Functions returning arrays are not eligible for implicit iteration. When evaluated in 'matrix' mode the {0;0}th element is used.
Note 7:
e.g. =SUM(INDIRECT({"A1";"A2")) would produce the value in A1 when evaluated in array mode.
2.2.2)The result matrix is rectangular, sized with the maximum number of rows and columns from all non-scalar arguments.
Note 8:
={1;2}+{3;4;5} => {4;6;#N/A}
={1}+{1;2} => {2;3}
2.2.3)The result matrix is populated by extracting the corresponding value from each of the non-scalar arguments based on the following rules, and evaluating the function with that set of arguments.
2.2.3.1)If the argument data is a singleton array or a scalar the value is repeated for each evaluation.
Note 9:
= 1 + {1;2;3|4;5;6} => {2;3;4|5;6;7}
= {1} + {1;2;3|4;5;6} => {2;3;4|5;6;7}
2.2.3.2)If the argument data is 1 column wide the value in the corresponding row is used to evaluate all columns in the result matrix.
Note 10:
= {1|2} + {10;20|30;40} => {11;21|32;42}
2.2.3.3)If the argument data is 1 row height the value in the corresponding column is used to evaluate all rows in the result matrix.
Note 11:
= {1;2} + {10;20|30;40} => {11;22|31;42}
2.2.3.4)If one argument data is 1 column wide and another argument data is 1 row height the value of the corresponding row respectively column is used to evaluate all elements in the result matrix.
Note 12:
={1;2} + {10|20} => {11;12|21;22}
2.2.3.5)If an argument is a 2d matrix the argument value in the position corresponding to the current output position is used if it is within range of the supplied argument, otherwise #N/A is used in the calculation.
Note 13:
=MID("abcd";{1;2};{1;2;3}) => {"a";"bc";#VALUE!}
A Formula Evaluator operates in an execution environment (a "host"). The behavior of the Formula Evaluator is parametrized by host-defined properties and functions.
The following properties are host-defined:
1)HOST-CASE-SENSITIVE: if true, text comparisons are case-sensitive. This influences the operators =, <>, <, <=, >, and >=, as well as database query functions that use them. Note that the EXACT function is always case-sensitive, regardless of this calculation setting.
2)HOST-PRECISION-AS-SHOWN: If true, calculations are performed using rounded values of those displayed; otherwise, calculations are performed using the precision of the underlying numeric representation.
Note: This does not impose a particular numeric model. Since implementations may use binary representations, this rounding may be inexact for decimal value.
3)HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL If true, the specified search criteria shall apply to the entire cell contents if it is a text match using = or <>; if not, only a subpart of the cell content needs to match the text.
4)HOST-AUTOMATIC-FIND-LABELS: if true, row and column labels are automatically found.
5)HOST-USE-REGULAR-EXPRESSIONS: If true, regular expressions are used for character string comparisons and when searching.
6)HOST-USE-WILDCARDS: If true, wildcards question mark '?' and asterisk '*' are used for character string comparisons and when searching. Wildcards may be escaped with a tilde '~' character.
7)HOST-NULL-YEAR: This defines how to convert a two-digit year into a four-digit year. All two-digit year values are interpreted as a year that equals or follows this year.
8)HOST-NULL-DATE: Defines the beginning of the epoch; a numeric date of 0 equals this date.
9)HOST-LOCALE: The locale to be used for locale-dependent operations, such as conversion of text to dates, or text to numbers.
10) HOST-ITERATION-STATUS: If enabled, iterative calculations of cyclic references are performed.
11) HOST-ITERATION-MAXIMUM-DIFFERENCE: If iterative calculations of cyclic references are enabled, the maximum absolute difference between calculation steps that all involved formula cells must yield for the iteration to end and yield a result.
12) HOST-ITERATION-STEPS: If iterative calculations of cyclic references are enabled, the maximum number of steps iterations are performed if the results are not within HOST-ITERATION-MAXIMUM-DIFFERENCE.
The function HOST-REFERENCE-RESOLVER(Reference) is implementation defined. This function takes as input a Unicode string containing a Reference according to section 4.8 and returns a resolved value.
Implementations of OpenFormula typically recalculate formulas when its information is needed. Typical implementations will note what values a formula depends on, and when those dependent values are changed and the formula's results are displayed, it will re-execute the formulas that depend on them to produce the new results (choosing the formulas in the right order based on their dependencies). Implementations may recalculate when a value changes (this is termed automatic recalculation) or on user command (this is termed manual recalculation).
Some functions' dependencies are difficult to determine and/or should be recalculated more frequently. These include functions that return today's date or time, random number generator functions (such as RAND 6.16.50), or ones that indirectly determine the cells to act on. Many implementations always recalculate formulas including such functions whenever a recalculation occurs. Functions that are always recalculated whenever a recalculation occurs are termed volatile functions. Functions that are often volatile functions include CELL 6.13.3, HYPERLINK 6.11.3, INDIRECT 6.14.7, INFO 6.13.13, NOW 6.10.15, OFFSET 6.14.11, RAND 6.16.50 and TODAY 6.10.19. Functions that depend on the cell position of the formula they are contained in or the position of a cell they reference need to be recalculated whenever that cell is moved, such functions are COLUMN 6.13.4, ROW 6.13.29 and SHEET 6.13.31. In addition, formulas may indicate that they should always be recalculated during a recalculation process by including a forced recalculation marker, as described in the syntax below.
This specification does not, by itself, specify a numerical implementation model, though it does imply some minimal levels of accuracy for most functions. For example, an application cannot say that it implements the infix operator “/” as specified in this document if it implements integer-only arithmetic.
Evaluators which claim to support “basic limits” shall support at least the following limits:
1.formulas up to at least 1024 characters long, as measured when in OpenDocument interchange format not counting the square brackets around cell addresses, or the “.” in a cell address when the sheet name is omitted.
2.at least 30 parameters per function when the function prototype permits a list of parameters.
3.permit strings of ASCII characters of up to 32,767 (2^15-1) characters.
4.support at least 7 nesting levels of functions.
All values defined by OpenFormula have a type. OpenFormula defines Text, Number, Complex Number, Logical, Error, Reference, ReferenceList and Array types.
A Text value (also called a string value) is a Character string" per [CharModel].
A text value of length zero is termed the empty string.
Index positions in a text value begin at 1.
Whether or not Unicode Normalization [UTR15] is performed on formulas, formula results or user inputs is implementation-defined. Some functions defined in this Part are labeled as "normalization-sensitive", meaning that the results of the formula evaluation may differ depending on whether normalization occurs, and which normalization form is used. Mixing operands of different normalization forms in the same calculation is undefined.
A number is a numeric value.
Numbers shall be able to represent fractional values (they shall not be limited to only integers). Evaluators may implement Number with a fixed or with a variable bit length. A cell with a constant numeric value has the Number type.
Implementations typically support many subtypes of Number, including Date, Time, DateTime, Percentage, fixed-point arithmetic, and arithmetic supporting arbitrarily long integers, and determine the display format from this. All such Number subtypes shall yield True for the ISNUMBER 6.13.22 function. This specification does not require that specific subtypes be distinguishable from each other, or that the subtype be tracked, but in practice most implementations do such tracking because requiring users to manually format every cell appropriately becomes tedious very quickly. Automatically determining the most likely subtype is especially important for a good user interface when generating OpenDocument format, since some subtypes (such as date, time, and currency) are stored in a different manner depending on their subtype. Thus, this specification identifies some common subtypes and identifies those subtypes where relevant in some function definitions, as an aid to implementing good user interfaces. Many applications vary in the subtype produced when combining subtypes (e.g., what is the result when percentages are multiplied together), so unless otherwise noted these are unspecified. Typical implementations try to heuristically determine the "right" format for a cell when a formula is first created, based on the operations in the formula. Users can then override this format, so as a result the heuristics are not important for data exchange (and thus outside the scope of this specification).
All Number subtypes shall yield True for the ISNUMBER function.
Time is a subtype of Number.
Time is represented as a fraction of a day.
Date is a subtype of Number.
Date is represented by an integer value.
A serial date is the expression of a date as the number of days elapsed from a start date called the epoch.
Evaluators shall support all dates from 1904-01-01 through 9999-12-31 (inclusive) in calculations, should support dates from 1899-12-30 through 9999-12-31 (inclusive) and may support a wider date range.
Note 1: Using expressions that assume serial numbers are based on a particular epoch may cause interoperability issues.
Evaluators shall support positive serial numbers. Evaluators may support negative serial numbers to represent dates before an epoch.
Note 2: It is implementation-defined if the year 1900 is treated as a leap year.
Note 3: Evaluators that treat 1900 as a non-leap year can use the epoch date 1899-12-30 to compensate for serial numbers that originate from evaluators that treat 1900 as a leap year and use 1899-12-31 as an epoch date.
DateTime is a subtype of Number. It is a Date plus Time.
A percentage is a subtype of Number that may be displayed by multiplying the number by 100 and adding the sign “%” or with other formatting depending upon the number format assigned to the cell where it appears.
A currency is a subtype of Number that may appear with or without a currency symbol or with other formatting depending upon the number format assigned to the cell where it appears.
A Logical value is a subtype of Number where TRUE() returns 1 and FALSE() returns 0.
The implicit conversion operator “Convert to Logical” 6.3.12, when a Number is passed as a condition, 0 is considered False and all other numeric values are considered True.
Note: Logical values can be a distinct type from Number. 4.5
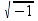
A complex number may, but need not be, represented as a Number or Text. The results of the functions ISNUMBER() and ISTEXT() are implementation-defined when applied to a complex number.
Functions and operators that accept complex numbers shall accept Text values as complex numbers (6.3.10 Conversion to Complex Number, as well as Numbers that are not complex numbers.
Note 1: IMSUM("3i";4) will produce the same result as COMPLEX(4;3).
Note 2: Expression authors should be aware that use of functions that are not defined by OpenFormula as accepting complex numbers as input may impair interoperability.
Equality can be tested using IMSUB to compute the difference, use IMABS to find the absolute difference, and then ensure the absolute difference is smaller than or equal to some nonnegative value (for exact equality, compare for equality with 0).
A Logical value (also called a Boolean value) is a value with one of two values: TRUE() and FALSE().
Note: Logical values can be represented as a subtype of Number. 4.3.7
An Error is one of a set of possible error values. Implementations may have many different error values, but one error value in particular is distinct: #N/A, the result of the NA() function. Users may choose to enter some data values as #N/A, so that this error value propagates to any other formula that uses it, and may test for this using the function ISNA().
Functions and operators that receive one or more error values as an input shall produce one of those input error values as their result, except when the formula or operator is specifically defined to do otherwise.
In an OpenDocument document, if an error value is the result of a cell computation it shall be stored as if it was a string. That is, the office:value-type of an error value is string; if the computed value is stored, it is stored in the attribute office:string-value.
Note: This does not change an Error into a string type (since the Error will be restored on recalculation); this enables applications which cannot recalculate values to display the error information.
An empty cell is neither zero nor the empty string, and an empty cell can be distinguished from cells containing values (including zero and the empty string). An empty cell is not the same as an Error, in particular, it is distinguishable from the Error #N/A (not available).
A cell strip consists of cell positions in the same row and in one or more contiguous columns.
A cell rectangle consists of cell positions in the same cell strips of one or more contiguous rows.
A cell cuboid consists of cell positions in the same cell rectangles of one or more contiguous sheets.
A reference is the smallest cuboid that (1) contains specifically-identified cell positions and/or specifically-identified complete columns/rows such that (2) removal of any cell positions either violates condition (1) or does not leave a cuboid.
Cell positions in a cell cuboid/rectangle/strip can resolve to empty cells (section 3.7).
The definitions of specific operations and functions that allow references as operands and parameters stipulate any particular limitations there are on forms of references and how empty cells, when permitted, are interpreted.
A reference list contains 1 or more references, in order. A reference list can be passed as an argument to functions where passing one reference results in an identical computation as an arbitrary sequence of single references occupying the identical cell range.
Note 1: For example, SUM([.A1:.B2]) is identical to SUM([.A1]~[.B2]~[.A2]~[.B1]), but COLUMNS([.A1:.B2]), resulting in 2 columns, is not identical to COLUMNS([.A1]~[.B2]~[.A2]~[.B1]), where iterating over the reference list would result in 4 columns.
A reference list cannot be converted to an array.
Note 2: For example, in array context {ABS([.A1]~[.B2]~[.A2]~[.B1])} is an invalid expression, whereas {ABS([.A1:.B2])} is not.
Passing a reference list where a function does not expect one shall generate an Error. Passing a reference list in array iteration context to a function expecting a scalar value shall generate an Error.
An array is a set of rows each with the same number of columns that contain one or more values. There is a maximum of one value per intersection of row and column. The intersection of a row and column may contain no value.
Many functions require a type or a set of types with special properties, and/or process them specially. For example, a "Database" requires headers that are the field names. These specialized types are called pseudotypes.
A Scalar value is a value that has a single value. A reference to more than one cell is not a scalar (by itself), and shall be converted to one as described below. An array with more than one element is not a scalar. The types Number (including a complex number), Logical, and Text are scalars.
A DateParam is a value that is either a Number (interpreted as a serial number; 4.3.3) or Text; text is automatically converted to a date value. 6.3.15
A TimeParam is a value that is either a Number (interpreted as a serial number; 4.3.2) or Text; text is automatically converted to a time value (fraction of a day). 6.3.16
An integer is a subtype of Number that has no fractional value. An integer X is equal to INT(X). Division of one integer by another integer may produce a non-integer.
TextOrNumber is a value that is either a Number or Text.
A basis is a subtype of Integer that specifies the day-count convention to be used in a calculation.
This standard defines five day-count conventions, corresponding to widely used current and historical accounting conventions. Each of these five bases defines two things:
1.How to calculate the number of days between two dates, date1 and date2.
2.How to calculate the number of days in each year between two dates, date1 and date2.
Historically day-count bases used the naming convention x/y, which indicated that the convention assumed x days per month and y days per year. These names are given for reference purposes.
|
Date Basis |
Historical Name |
Day Count |
Days in Year |
|
0 |
US (NASD) 30/360 |
Procedure A, 4.11.7.3 |
Procedure D, 4.11.7.6 |
|
1 |
Actual/Actual |
Procedure B, 4.11.7.4 |
Procedure E, 4.11.7.7 |
|
2 |
Actual/360 |
Procedure B, 4.11.7.4 |
Procedure D, 4.11.7.6 |
|
3 |
Actual/365 |
Procedure B, 4.11.7.4 |
Procedure F, 4.11.7.8 |
|
4 |
European 30/360 |
Procedure C, 4.11.7.5 |
Procedure D, 4.11.7.6 |
The day-count procedures are expressed using notations defined as:
•.day(date) returns the day of the month for the given date value, an integer from 1 to 31
•.month(date) returns the month of a given date value, an integer from 1-12
•.year(date) returns the year of the given date value
•.truncate(date) truncates any fractional (hours, minutes, seconds) of a date value and returns the whole date portion.
•.Binary comparison operators date1>date2 and date1 == date2
•.is-leap-year(year) returns true if year is a leap year, otherwise false.
Note: Some of the day count procedures use intermediate results that contain counter-factual dates, such as February 30th. This is not an error. The above functions work on such dates as well, e.g., day(February 30th) = = 30.
1.truncate(date1), truncate(date2)
2.If date1==date2 return 0
3.If date1> date2, then swap the values of date1 and date2.
4.If day(date1)==31 then subtract 1 day from date1
5.If day(date1)==30 and day(date2)==31 then subtract 1 day from date2
6.If both date1 and date2 are the last day of February, change date2 to the 30th of the month.
7.If date1 is the last day of February, change it to the 30th of the month.
8.Return (year(date2)*360 + month(date2)*30 + day(date2)) - (year(date1)*360 + month(date1)*30 + day(date1)).
1.truncate(date1), truncate(date2)
2.If date1> date2, then swap the values of date1 and date2.
3.Return the actual numbers of days between date1 and date2, inclusive of date1, but not inclusive of date2.
1.truncate(date1), truncate(date2)
2.If date1==date2 return 0
3.If date1> date2, then swap the values of date1 and date2.
4.If day(date1)==31 then subtract 1 from date1
5.If day(date2)==31 then subtract 1 from date 2
6.Return (year(date2)*360 + month(date2)*30 + day(date2)) - (year(date1)*360 + month(date1)*30 + day(date1)).
1.Return 360
1.Evaluate A: year(date1) != year(date2)
2.Evaluate B: year(date2)!=year(date1)+1
3.Evaluate C: month(date1) < month(date2)
4.Evaluate D: month(date1) == month(date2)
5.Evaluate E: day(date1) < day(date2)
6.Evaluate F: (A and B) or (A and C) or (A and D and E)
7.If F is true then return the average of the number of days in each year between date1 and date2, inclusive.
8.Otherwise, if A and is-leap-year(year(date1)) then return 366
9.Otherwise, if a February 29 occurs between date1 and date2 then return 366
10. Otherwise, if date2 is a February 29, then return 366
11. Otherwise return 365
1.Return 365
A criterion is a single cell Reference, Number or Text. It is used in comparisons with cell contents.
A reference to an empty cell is interpreted as the numeric value 0.
A matching expression can be:
●A Number or Logical value. A matching cell content equals the Number or Logical value.
●A value beginning with a comparator (<, <=, =, >, >=, <>). 6.4.9
For =, if the value is empty it matches empty cells. 4.7
For <>, if the value is empty it matches non-empty cells.
For <>, if the value is not empty it matches any cell content except the value, including empty cells.
Note: "=0" does not match empty cells.
For = and <>, if the value is not empty and can not be interpreted as a Number type or one of its subtypes and the host-defined property HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL is true, comparison is against the entire cell contents, if false, comparison is against any subpart of the field that matches the criteria. For = and <>, if the value is not empty and can not be interpreted as a Number type or one of its subtypes 3.4 applies.
●Other Text value. If the host-defined property HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL is true, the comparison is against the entire cell contents, if false, comparison is against any subpart of the field that matches the criteria.
A database is a rectangular organized set of data. Any database has a set of one or more fields that determine the structure of the database. A database has a set of zero or more records with data, and each record contains data for every field (though that field may be empty).
Evaluators shall support the use of ranges as databases if they support any database functions. The first row of a range is interpreted as a set of field names.
Note: Field names of type Text and unique without regard to case enhance the interoperability of data. It is also a common expectation that rows following the first row of data are data records that correspond to field names in the first row.
A single cell containing text can be used as a database; if it is, it is a database with a single field and no data records.
A field is a value that selects a field in a database; it is also called a field selector. If the field selector is Text, it selects the field in the database with the same name.
Evaluators should match the database field name case insensitive.
If a field selector is a Number, it is a positive integer and used to select the fields. Fields are numbered from left to right beginning with the number 1.
All functions that accept a field parameter shall, when evaluated, return an Error if the selected field does not exist.
A criteria is a rectangular set of values, with at least one column and two rows, that selects matching records from a database. The first row lists fields against which expressions will be matched. 4.11.10 Rows after the first row contain fields with expressions for matching against database records.
For a record to be selected from a database, all of the expressions in a row of criteria shall match.
A reference to an empty cell is interpreted as the numeric value 0.
●Expressions are matched as per 4.11.8 Criterion.
Some functions accept a sequence, i.e., a value that is to be treated as a sequential series of values. The following are sequences: NumberSequence, NumberSequenceList, DateSequence, LogicalSequence, and ComplexSequence.
When evaluating a function that accepts a sequence, the evaluator shall follow the rules for that sequence as defined in section 6.3. When processing a ReferenceList, the references are processed in order (first, second if any, and so on). In a cuboid, the first sheet is first processed, followed by later sheets (if any) in order. Inside a sheet, it is implementation-defined as to whether the values are processed row-at-a-time or column-at-a-time, but it must be one of these two processing orders. If processing row-at-a-time, the sequence must be produced by processing each row in turn, from smallest to largest column value (e.g., A1, B1, C1). If processing column-at-a-time, the sequence must be produced by processing each column at a time, from the smallest to the largest row value (e.g., A1, A2, A3).
Any represents a value of any type defined in this standard, including Error values.
The OpenFormula syntax is defined using the BNF notation of the XML specification, chapter 6 [XML1.0]. Each syntax rule is defined using "::=".
Note: Formulas are typically embedded inside an XML document. When this occurs, characters (such as "<", ">", '"', and "&") shall be escaped, as described in section 2.4 of the XML specification [XML1.0]. In particular, the less-than symbol "<" is typically represented as “<”, the double-quote symbol as “"”, and the ampersand symbol as “&” (alternatively, a numeric character reference can be used).
Formulas may start with a '=' (EQUALS SIGN, U+003D), which if present may be followed by a “forced recalculate” marker '=' (EQUALS SIGN, U+003D), followed by an expression. If the second '=' (EQUALS SIGN, U+003D) is present, this formula is a "forced recalculation" formula. If a formula is marked as a "forced recalculation" formula, then it should be recalculated whenever one of its predecessors it depends on changes.
Expressed in BNF grammar, a formula is specified:
Formula ::= Intro? Expression
Intro ::= '=' ForceRecalc?
ForceRecalc ::= '='
The primary component of a formula is an Expression . Formulas are composed of Expression s, which may in turn be composed from other Expression s.
Expression ::=
Whitespace* (
Number |
String |
Array |
PrefixOp Expression |
Expression PostfixOp |
Expression InfixOp Expression |
'(' Expression ')' |
FunctionName Whitespace* '(' ParameterList ')' |
Reference |
QuotedLabel |
AutomaticIntersection |
NamedExpression |
Error
) Whitespace*
SingleQuoted ::= "'" ([^'] | "''")+ "'"
Constant numbers are written using '.' (FULL STOP, U+002E) dot as the decimal separator. Optional "E" or "e" denotes scientific notation. Syntactically, negative numbers are positive numbers with a prefix "-" (HYPHEN-MINUS, U+002D) operator. A constant number is of type Number.
Number ::= StandardNumber |
'.' [0-9]+ ([eE] [-+]? [0-9]+)?
StandardNumber ::= [0-9]+ ('.' [0-9]+)? ([eE] [-+]? [0-9]+)?
Evaluators should be able to read the Number format, which accepts a decimal fraction that starts with decimal point '.' (FULL STOP, U+002E), without a leading zero. Evaluators shall write numbers only using the StandardNumber format, which requires a leading digit, and shall not write numbers with a leading '.' (FULL STOP, U+002E).
Constant strings are surrounded by double-quote characters (QUOTATION MARK, U+0022); a literal double-quote character '"' (QUOTATION MARK, U+0022) as string content is escaped by duplicating it. When a formula is stored in an XML attribute, XML escaping rules apply: thus inside an XML attribute double-quote characters shall be escaped (e.g., as ") and carriage return characters in a String (e.g., as 
) . A constant string is of type Text.
String ::= '"' ([^"#x00] | '""')* '"'
Operators are functions with one or more parameters.
PrefixOp ::= '+' | '-'
PostfixOp ::= '%'
InfixOp ::= ArithmeticOp | ComparisonOp | StringOp | ReferenceOp
ArithmeticOp ::= '+' | '-' | '*' | '/' | '^'
ComparisonOp ::= '=' | '<>' | '<' | '>' | '<=' | '>='
StringOp ::= '&'
There are three predefined reference operators: reference intersection , reference concatenation , and range. The result of these operators may be a 3 dimensional range, with front-upper-left and back-lower-right corners, or even a list of such ranges in the case of cell concatenation.
ReferenceOp ::= IntersectionOp | ReferenceConcatenationOp | RangeOp
IntersectionOp ::= '!'
ReferenceConcatenationOp ::= '~'
RangeOp ::= ':'
Table 1 - Operators defines the associativity and precedence of operators, from hightest to lowest precedence.
|
Associativity |
Operator(s) |
Comments |
|
left |
: |
Range. |
|
left |
! |
Reference intersection ([.A1:.C4]![.B1:.B5] is [.B1:.B4]). Displayed as the space character in some implementations. |
|
left |
~ |
Reference union. Displayed as the function parameter separator in some implementations. |
|
right |
+,- |
Prefix unary operators, e.g., -5 or -[.A1]. Note that these have a different precedence than add and subtract. |
|
left |
% |
Postfix unary operator % (divide by 100). Note that this is legal with expressions (e.g., [.B1]%). |
|
left |
^ |
Power (2 ^ 3 is 8). |
|
left |
*,/ |
Multiply, divide. |
|
left |
+,- |
Binary operations add, subtract. Note that unary (prefix) + and - have a different precedence. |
|
left |
& |
Binary operation string concatenation. Note that unary (prefix) + and - has a different precedence. Note that "&" shall be escaped when included in an XML document |
|
left |
=, <>, <, <=, |
Comparison operators equal to, not equal to, less than, less than or equal to, greater than, greater than or equal to |
Note 1: Prefix “-” has a higher precedence than “^”, that “^” is left-associative, and that reference intersection has a higher precedence than reference union.
Note 2: Prefix “+” and “–“ are defined to be right-associative. However, note that typical applications which implement at most the operators defined in this specification (as specified) may implement them as left-associative, because the calculated results will be identical.
Note 3: Precedence can be overridden by using parentheses, so "=2+3*4" computes to 14 but "=(2+3)*4" computes 20. Implementations should retain "unnecessary" parentheses and white space, since these are added by people to improve readability.
Functions are called by name, followed by parentheses surrounding a list of parameters. Parameters are separated using the semicolon ';' (SEMICOLON, U+003B) character:
FunctionName ::= LetterXML (LetterXML | DigitXML |
'_' | '.' | CombiningCharXML)*
Where LetterXML, DigitXML, and CombiningCharXML are Letter, Digit, and CombiningChar as they are defined in [XML1.0].
Function names are case-insensitive.
Function calls shall be given a parameter list, though it may be empty. An empty list of parameters is considered a call with 0 parameters, not a call with one parameter that happens to be empty. TRUE() is syntactically a function call with 0 parameters. It is syntactically legitimate to provide empty parameters, though functions may not accept empty parameters unless otherwise noted:
ParameterList ::= /* empty */ |
Parameter (Separator EmptyOrParameter )* |
Separator EmptyOrParameter /* First param empty */
(Separator EmptyOrParameter )*
EmptyOrParameter ::= /* empty */ Whitespace* | Parameter
Parameter ::= Expression
Separator ::= ';'
When writing a document using function(s) not defined in this specification, an evaluator shall include a prefix in such function names to identify the original definer of the function's semantics. When the origin of a function cannot be determined, producers may omit a prefix. Producers may use the prefix to differentiate between different definition types. Evaluators that do not support a function should compute its result as some Error value other than NA().
Note: Examples of implementation-defined functions include extension functions included with an implementation, user-defined functions written by users, and 3rd party functions distributed in libraries.
Note: Examples of such names include COM.MICROSOFT.CUBEMEMBER, ORG.OPENOFFICE.STYLE, ORG.GNUMERIC.RANDRAYLEIGH, and COM.LOTUS.V98.FOO.
Evaluators should avoid defining evaluator-unique functions beginning with a top-level domain name followed by a period. Evaluators should avoid defining application functions beginning with “NET.”, “COM.”, “ORG.”, or a country code followed by a period.
Evaluators that do not support a function should compute its result as some Error value other than NA().
References refer to a specific cell or set of cells. The syntax for a constant reference:
Reference ::= '[' (Source? RangeAddress) | ReferenceError ']'
RangeAddress ::=
SheetLocatorOrEmpty '.' Column Row (':' '.' Column Row )? |
SheetLocatorOrEmpty '.' Column ':' '.' Column |
SheetLocatorOrEmpty '.' Row ':' '.' Row |
SheetLocator '.' Column Row ':' SheetLocator '.' Column Row |
SheetLocator '.' Column ':' SheetLocator '.' Column |
SheetLocator '.' Row ':' SheetLocator '.' Row
SheetLocatorOrEmpty ::= SheetLocator | /* empty */
SheetLocator ::= SheetName ('.' SubtableCell)*
SheetName ::= QuotedSheetName | '$'? [^\]\. #$']+
QuotedSheetName ::= '$'? SingleQuoted
SubtableCell ::= ( Column Row ) | QuotedSheetName
ReferenceError ::= "#REF!"
Column ::= '$'? [A-Z]+
Row ::= '$'? [1-9] [0-9]*
Source ::= "'" IRI "'" "#"
CellAddress ::= SheetLocatorOrEmpty '.' Column Row /* Not used directly */
References always begin with '[' (LEFT SQUARE BRACKET, U+005B); this disambiguates cell addresses from function names and named expressions. SheetNames include single-quote“'” (APOSTROPHE, U+0027) characters by doubling them and having the entire name surrounded by single-quotes. Column labels shall be in uppercase. The syntax supports whole-row and whole-column references. A reference is of type Reference.
A ReferenceError provides information that a formula evaluates to an Error because of a particular reference having been invalidated by actions that occurred after the formula was validly created.
Columns are named by a sequence of one or more uppercase letters A-Z (U+0041 through U+005A). Columns are named A, B, C, ... X, Y, Z, AA, AB, AC, ... AY, AZ, BA, BB, BC, ... ZX, ZY, ZZ, AAA, AAB, AAC, AAZ, ABA, ABB, and so on.
If a RangeAddress does not contain a Column element or does not contain a Row element, it specifies a cell rectangle (4.8 Reference). If it contains Row elements, the cell rectangle starts on the first column and ends on the last column the evaluator supports. If it contains Column elements, the cell rectangle starts on the first row and ends on the last row the evaluator supports.
If in a RangeAddress the first part (left of ':' colon) contains a SheetLocator and the second part (right of ':' colon) does not contain a SheetLocator, the second part inherits the SheetLocator from the first part.
If a RangeAddress contains two different SheetLocators, it specifies a cell cuboid (4.8 Reference).
If a RangeAddress contains no SheetLocator, the current sheet local to the position where the expression is evaluated is referred.
A reference with an explicit row or column value beyond the capabilities of an evaluator shall be computed as an Error, and not as a reference.
Note that references can include a single embedded “:” separator. Evaluators should use references with embedded “:” separators inside the [..] markers, instead of the general-purpose “:” operator, when saving files, and where there is a choice of cells to join, and evaluators should choose the leftmost pair.
The optional Source expresses that the reference is to sheets and/or cells in a different location (possibly in a same-document fragment) than that for the formula in which the reference occurs. The optional Source is also used for locating Named Expressions (section 5.11).
The IRI portion of Source shall be an IRI reference [RFC3987] conforming to the general syntax IRI-reference rule (section 2.2 of [RFC3987]) after each pair of consecutive single-quote characters (APOSTROPHE, U+0027) is replaced by one single single-quote character.
Note: The escaping of single-quotes as paired single-quotes is because the IRI is enclosed in single quote characters of the Source.
Resolution of the [RFC3987] IRI reference is host-defined behavior. 3.4
A reference list is the result of the Infix Operator Reference Concatenation 6.4.13 '~', the syntax is:
ReferenceList ::= Reference (Whitespace* ReferenceConcatenationOp Whitespace* Reference)*
A reference list can be passed as an argument to functions expecting a reference parameter where passing one reference results in an identical computation as an arbitrary sequence of single references occupying the identical cell range. A reference list cannot be converted to an array.
A quoted label is Text contained in a table as cell content, either literally or as a formula result.
QuotedLabel ::= SingleQuoted
A quoted label identifies a column or a row, depending on the label range in which its text appears.
For a QuotedLabel, first the cells defined in column label ranges (cell ranges of the table:label-cell-range-address attribute in the elements <table:label-range> with attribute table:orientation set to column) are searched for the string content of QuotedLabel (without the quotes). If found, the corresponding column's range of the data cell range of the table:data-cell-range-address attribute is taken as a reference. If not found, the cells defined in row label ranges (attribute table:orientation set to row) are searched and if found the corresponding row's range of the data cell range is taken. Label ranges of the current formula's sheet take precedence over label ranges of other sheets if a name occurs in both.
For a QuotedLabel where no defined label is found, an automatic lookup is performed on the sheet where the formula cell resides, if that document setting is enabled (HOST-AUTOMATIC-FIND-LABELS value true ).
Matches to the upper left of the formula cell are preferred over other matches, followed by matches with a smaller distance. The following algorithm is used:
Cells on the same sheet as the formula cell are examined column-wise from left to right whether they contain the text of QuotedLabel (without the quotes). If more than one cell match, the distance and direction from the formula cell's position is taken into account. The distance is calculated by Distance= ColumnDifference*ColumnDifference+ RowDifference*Row Difference using an idealized layout of quadratic cells. For the direction, during the run two independent match positions are remembered each time Distance is smaller than a previous Distance: Match2 for positions right of and/or below the formula position (FormulaColumn < MatchColumn || FormulaRow < MatchRow), Match1 for all others (not right of and not below). Match1 also holds the very first match, in case there is only one match or all matches are somewhere below or right of the formula cell. After having found the smallest distances the conditions are:
1.If Match1 has the smallest distance, that match is taken.
2.Else, Match2 (right and/or below) has the smallest or an equal distance:
2.1 A match to the upper left (FormulaColumn >= Match1Column && FormulaRow >= Match1Row) takes precedence over matches to other directions.
2.2 Else, if there is no match to the upper left:
2.2.1 If Match1 is somewhere right of the formula cell (FormulaColumn < Match1Column) it was the first match found in column-wise lookup.
2.2.1.1 If Match2 is above the formula cell (FormulaRow >= Match2Row) it is to the upper right of the formula cell and either nearer than Match1 or Match1 is below. Match2 is taken.
2.2.1.2 Else Match2 is below the formula cell and Match1 is taken.
2.2.2 Else (Match1 not right of the formula cell => two matches below or below and right) the match with the smallest distance is taken.
If the resulting cell is below or above another cell containing Text a row lable is assumed, else a column label is assumed.
Note: Use of automatically looked up column or row labels in expressions impairs interoperability.
For the reference resulting from a single QuotedLabel an implicit intersection is generated if the operator or function where it is used with expects a scalar value. The intersection is generated with the current formula's cell position, thus for a column label an intersection is generated with the formula cell's row, for a row label with the formula cell's column.
When passed as a non-scalar argument (e.g. Array or NumberSequence) to a function, an automatically looked up column or row label (not defined label range) is converted to an automatic range reference that is adjusted each time the formula is interpreted. The range is generated from the column below a column label, or the row right of a row label, constructed by encompassing contiguous non-empty cells. An empty cell interrupts contiguousness, one empty cell directly below a column label cell or right of a row label cell is ignored.
Example:
|
Row |
Data |
Expression |
Result |
Comment | ||||||||||||||||
|
=SUM('Label') |
3 |
Empty cell in row 2 is skipped (two empty cells in row 2 and 3 would not and stop), empty cell in row 5 stops the automatic range. | |||||||||||||||||
If any cell content is entered in row 5 the range is regenerated as follows:
|
Row |
Data |
Expression |
Result |
Comment | ||||||||||||||||
|
=SUM('Label') |
15 |
Empty cell in row 2 is skipped, empty cell in row 7 stops the automatic range. | |||||||||||||||||
An automatic intersection may be used to identify the intersection of two quoted labels. Note that this is different from the IntersectionOp, which takes two references instead of two labels:
AutomaticIntersection ::= QuotedLabel Whitespace* '!!' Whitespace* QuotedLabel
In an automatic intersection, one of the labels identifies a row, the other a column; they may be in either order. Each QuotedLabel is looked up as defined above under "Lookup of Defined Lables" and "Automatic Lookup of Labels". If two data cell ranges are found, the intersection of the column's data cell range and the row's data cell range is generated. If the intersection result is not exactly one cell, an Error is generated.
A NamedExpression references another expression, possibly in a completely different spreadsheet or any other document type that can be imported into a spreadsheet.
NamedExpression ::= SimpleNamedExpression |
SheetLocalNamedExpression | ExternalNamedExpression
SimpleNamedExpression ::= Identifier |
'$$' (Identifier | SingleQuoted)
SheetLocalNamedExpression ::=
QuotedSheetName '.' SimpleNamedExpression
ExternalNamedExpression ::=
Source (SimpleNamedExpression | SheetLocalNamedExpression)
Evaluators supporting named expressions shall support Simple Named Expressions that are global to all the sheets in a (spreadsheet) document in the current document. This is a named expression without a Source, QuotedSheetName, or SubtableCell. The type of a named expression is the type of the value that the named expression returns.
Named expressions are case-consistent, meaning that matching is done case-insensitive and identifiers can not differ ONLY in their case. Evaluators should write identifiers with identical case in all locations.
Evaluators may support Sheet-local Named Expressions that are local (attached) to individual sheets. In that case, a non-empty QuotedSheetName can be used to reference a sheet-specific named expression. The most specific named expression for a given expression is used. If the QuotedSheetName is empty, the search for the named expression begins with the current sheet, then up through the container(s) of the sheet (the same is true if the QuotedSheetName rule fragment is not included at all). If there is a non-empty QuotedSheetName, search begins with that named sheet, then up through its container(s) for the given name.
Note: There is no syntax for referencing a named expression without first looking at the current sheet's named expressions; where this is a problem, a user can define a blank sheet and reference that sheet as the starting location for finding the named expression.
If a sheetname is not empty, it shall be quoted using “'” (APOSTROPHE, U+0027). While both Source and QuotedSheetName can begin with the single-quote character “'” (APOSTROPHE, U+0027), they are distinguished: after the closing single-quote character, a non-empty source shall have the '#' (NUMBER SIGN, U+0023) character as the next non-whitespace; a non-empty sheetname shall be followed by the '.' (FULL STOP, U+002E) character as the next non-whitespace.
Expressions should limit the names of their identifiers to only ([UNICODE]) letters, underscores, and digits, not including patterns that look like cell references or the words True or False.
Identifier ::= ( LetterXML
(LetterXML | DigitXML | '_' | CombiningCharXML)* )
- ( [A-Za-z]+[0-9]+ )
- ([Tt][Rr][Uu][Ee]) - ([Ff][Aa][Ll][Ss][Ee])
Evaluators shall support the Error value #N/A. Evaluators may support other Error values. Evaluators may allow entry of errors directly, parse them and recognize them as Errors. Functions shall propagate Errors unless stated otherwise.
Inline Error constants shall have the following syntax:
Error ::= '#' [A-Z0-9]+ ([!?] | ('/' ([A-Z] | ([0-9] [!?]))))
Specific Error values are indicated by an identifier.
Table 4 is a list of constant error names that are used by several existing implementations. Evaluators may implement other constant Error values.
Table 4 - Possible Other Constant Error Values
|
Name |
Comments |
|
#DIV/0! |
Attempt to divide by zero, including division by an empty cell. ERROR.TYPE of 2 |
|
#NAME? |
Unrecognized/deleted name. ERROR.TYPE of 5. |
|
#N/A |
Not available. ISNA() applied to this value will return True. Lookup functions which failed, and NA(), return this value. ERROR.TYPE of 7. |
|
#NULL! |
Intersection of ranges produced zero cells. ERROR.TYPE of 1. |
|
#NUM! |
Failed to meet domain constraints (e.g., input was too large or too small). ERROR.TYPE of 6. |
|
#REF! |
Reference to invalid cell (e.g., beyond the application’s abilities). ERROR.TYPE of 4. |
|
#VALUE! |
Parameter is wrong type. ERROR.TYPE of 3. |
An unknown constant Error value shall be mapped into an Error value supported by the evaluator when read (e.g., the application's equivalent of #NAME?), though an evaluator may warn the user if this has or will take place. It is desirable to preserve the original specific Error name when writing an Error constant back out, where possible, but evaluators may write a different Error value for a formula than they did when reading it for Errors other than #N/A. Whitespace shall not be included in an Error name.
Evaluators should use a human-comprehensible name, not a numeric id, for constant Error values they write.
Inline arrays are enclosed with curly braces. Inside, they contain one or more rows, with each row separated by a row separator:
Array ::= '{' MatrixRow ( RowSeparator MatrixRow )* '}'
MatrixRow ::= Expression ( ';' Expression )*
RowSeparator ::= '|'
Evaluators that support inline arrays shall accept a matrix with one or more rows, each with one or more columns, with the same number of columns in each row, with constant values for each expression. Evaluators that do not support inline arrays, or cannot support a particular use permitted by this syntax, should compute an Error value for such arrays. An inline array is of type Array.
Note: Expression authors should be aware that use of Expression other than constant Number or constant String may impair interoperability.
Whitespace ::= #x20 | #x09 | #x0a | #x0d
For calculation purposes, whitespace is ignored unless it is inside the contents of string constants or text surrounded by single quotes. Evaluators shall ignore any whitespace characters before and/or after any operators, constant numbers, constant strings, constant errors, inline arrays, parentheses used for controlling precedence, and the closing parenthesis of a function call. Whitespace shall be ignored following the initial equal sign(s). Whitespace shall be ignored just before a function name, but whitespace shall not separate a function name from its initial opening parentheses. Whitespace shall not be used in the interior of a terminating grammar rule (a rule that references no other rule other than character sets, internally or externally-defined), unless specifically permitted by the terminating grammar rule, since these rules define the lexical properties of a component. Evaluators shall not write formulas with whitespace embedded in any unquoted identifier, constant Number, or constant Error. Evaluators shall treat SPACE (U+0020), CHARACTER TABULATION (U+0009), LINE FEED (U+000A), and CARRIAGE RETURN (U+000D) as whitespace characters.
An embedded line break shall be represented by a single LINE FEED character (U+000A), not by a carriage return-linefeed pair. When embedded in an XML attribute the linefeed character is represented as “
”.
Evaluators should retain whitespace entered by the original formula creator and use it when saving or presenting the formula, and should not add additional whitespace unless directed to do so during the process of editing a formula.
OpenFormula defines commonly used operators and functions.
Function names ignore case. Evaluators should write function names in all uppercase letters when writing OpenFormula formulas.
Unless otherwise noted, if any value being provided is an Error, the result is an Error; if more than one Error is provided, one of them is returned (evaluators should return the leftmost Error result).
For every function or operator, the following are defined in this specification:
●Name: The function/operator name.,
●Summary: One sentence briefly describing the function or operator.
●Syntax:
●Parameter names are shown in order, with each parameter prefixed by the type or pseudo-type of that parameter. If the type has multiple names separated by “|”, then any of those types are permitted.
●A { ... } indicates a list of zero or more parameters, separated by the function parameter separator character.
●A { ... } followed by a superscripted + indicates a list of one or more parameters, separated by the function parameter separator character.
●Components surrounded by [ ... ] are optional. Optional components may be omitted.
●An optional parameter followed by the = symbol has the default value given after the equal sign.
●Parameters are separated with a semicolon (";"), as per the OpenFormula syntax.
When a function is given a value of a different type, the parameters are first converted using the implicit conversion rules before the function operates on its parameters.
Evaluators may extend functions by permitting fewer or additional parameters, which documents may use. Extended functions may result in a lack of interoperability.
●Returns: Return type (e.g., Number, Text, Logical, Reference).
●Constraints: A description of constraints, in addition to the constraints imposed by the parameter types. If there are no additional constraints beyond those imposed by the parameter types, this is "None". If a constraint is not met, the function/operator shall return an Error unless otherwise noted.
●Semantics: This text describes what the function/operator does.
If a parameter is a pseudotype, but the provided value fails to meet the requirements for that type, the behavior is implementation-defined.
Note: Functions and operators are defined by mathematical formulas or by an OpenFormula formula. Formulas define the correct result, and not the algorithm for calculation. Since computing systems have limited precision and range of numbers, some functions cannot or should not be naively implemented as their formulas suggest. This specification defines the mathematically correct answer, and allows implementors to choose the best algorithm that will meet that definition.
●Comment: Explanatory comment.
●See also A list of related operators and functions.
The implicit conversion operators omit many of these items, e.g., the syntax (since there is none).
Any given function or operand takes 0 or more parameters, and each of those parameters has an expected type. The expected type can be one of the base types, identified above. It can also be of some conversion type that controls conversion, e.g., Any means that no conversion is done (it can be of any type); NumberSequence causes a conversion to an ordered sequence of zero or more numbers. If the passed-in type does not match the expected type, an attempt is made to automatically convert the value to the expected type. An Error is returned if the type cannot be converted (this can never happen if the expected type is Any). Unless otherwise noted, any conversion operation applied to a value of type Error returns the same value.
To convert to a scalar, if the value is of type:
●Number, Logical, or Text, return the value.
●reference to a single cell: obtain the value of the referenced cell, and return that value.
●reference to more than one cell: do an implied intersection, 6.3.3, to determine which single cell to use, then handle as a reference to a single cell.
In some cases a reference to a single cell is needed, but a reference to multiple cells is provided. In this case an "implied intersection" is performed. To perform an implied intersection:
●Compute the union of cells contained in the current row and current column of the formula being computed.
●Intersect this with the provided reference to multiple cells
●If a single cell is referenced; return it; otherwise, return an Error.
A ForceArray attribute forces calculation of the argument's expression into non-scalar array mode. This means that no implied intersection is performed, instead where a reference to a single cell is expected and multiple cells are provided, iteration over the multiple cells is performed and results are stored in an array that is passed on.
See also Non-Scalar Evaluation 3.3
If the expected type is Number, then if value is of type:
●Number, return it.
●Logical, return 0 if FALSE, 1 if TRUE.
●Text: The specific conversion is implementation-defined; an evaluator may return 0, an Error value, or the results of its attempt to convert the Text value to a Number (and fall back to 0 or Error if it fails to do so). Evaluators may apply VALUE() or some other function to do this conversion, should they choose to do so. Conversion depends on the actual locale the application runs in, especially if group or decimal separators are involved.
●Reference: If the reference covers more than one cell, do an implied intersection to determine which cell to use. Then obtain the value of the single cell and perform the rules as above. If the calculation setting “precision-as-shown” is true, then convert the number to the closest possible representation of the displayed number. If the cell is empty (blank), use 0 (zero) as the value. Evaluators may choose to convert references to Text in a different manner than they handle converting embedded Text to a Number.
If the expected type is Integer for a function or operator, apply the “Conversion to Number” operation. 6.3.5 Then, if the result is a Number but not an integer, apply the specific conversion from Number to integer specified by that particular function/operator. If the function or operator does not specify any particular conversion operation, then the conversion from a non-integer Number into an integer is implementation-defined.
Many different conversions from a non-integer number into an integer are possible. The conversion direction may be towards negative infinity, towards positive infinity, towards zero, away from zero, towards the nearest even number, or towards the nearest odd number. A conversion can select the nearest integer, the nearest even or odd integer, or the “next” integer in the given direction if it is not already an integer. If a conversion selects the nearest integer, a direction is still needed (for when a value is halfway between two integers). In this specification, this conversion is referred to as “rounding” or “truncation”; these terms by themselves do not specify any specific operation.
If a function specifies its rounding operation using a series of capital letters, the function defined in this specification for that function is used to do the conversion to integer. Common such functions are:
●INT, which if given non-integer rounds down to the next integer towards negative infinity, regardless of whether or not it is the closest integer.
●ROUND, which if given non-integer rounds to the nearest integer. If the input number is halfway between integers, it rounds away from zero.
●TRUNC, which if given non-integer rounds towards zero, regardless of whether or not that integer is the closest integer.
If the expected type is NumberSequence, then if value is of type:
●Number, Text, or Logical, handle as Conversion to Number 6.3.5 (creating a sequence of length 1).
●reference, create a sequence of numbers from the values of the referenced cells that only includes the values of type Number or Error. Thus, Empty cells and Text that could be converted into a value is not included in a number sequence. If the Logical type is a distinguished type from the Number type, it should not be included in the sequence of numbers; if the Logical type is not a distinguished type, then such values will (of course) be included in the number sequence.
Identical to Conversion to NumberSequence 6.3.7 , with the addition that instead of a Reference also a ReferenceList is accepted as argument. Each Reference in the list is converted to a NumberSequence in the order of occurrence.
Identical to Conversion to NumberSequence 6.3.7 except that each element in the list represents a serial date value of subtype Date.
An evaluator may accept complex numbers as Text, Number, or a different distinguishable type.
If the value is:
●Number that is not complex, use the Number with 0 as the imaginary part.
●Text, attempt to convert to complex number using VALUE(). If it is a number that is not complex, use it. If the text matches one of these patterns, accept it:
([+-]?Number [+-])?Number[ij]
[+-]?Number[ij]
●Logical, convert to Number and then handle as Number.
●reference: Convert to Scalar, then use the rules above. If the reference is to an empty cell, consider it equal to 0.
If the expected type is ComplexSequence, then if value is of type:
●Number, Text, or Logical, handle as Conversion to Complex Number (creating a sequence of length 1).
●Reference, create a sequence of complex numbers from the values of the referenced cells that only includes the values of type Number, Text, and Error. Empty cells are not included in a complex number sequence. If the Logical type is a distinguished type from the Number type, it should not be included in the sequence of numbers; if the Logical type is not a distinguished type, then such values will (of course) be included in the number sequence.
If the expected type is Logical, then if value is of type:
●Number, return TRUE() for nonzero and FALSE() for 0.
●Text: The specific conversion is implementation-defined; an evaluator may return False, an Error value, or the results of its attempt to convert the Text value (ignoring case) to a Logical value (and fall back to False or Error if it fails to do so). Conversion depends on the actual locale the evaluator runs in.
●Logical, return it.
●Reference, convert to scalar and then perform as above. If the reference is to an empty cell, consider it FALSE().
If the expected type is LogicalSequence, then if value is of type:
●Number or Logical, handle as Conversion to Logical (creating a sequence of length 1).
●Reference, create a sequence of logical values from the values of the referenced cells that only includes the values of type Logical and Error. If the Logical type is not a distinguished type, then include values of type Number, converting each to a Logical value as described in Conversion to Logical. Empty cells are not included in a LogicalSequence.
If the expected type is Text, then if value is of type:
●Number, transform into Text (with no whitespace).
●Text, return it.
●Logical, return "TRUE" if it is TRUE and "FALSE" if it is false.
●Reference: perform conversion to scalar. If the referenced cell is empty, treat as an empty string (a text value with length 0). Then perform as above.
If the expected type is the pseudotype DateParam, then if value is of type:
●Number, return it.
●Text, pass to DATEVALUE, and if non-Error, return it. If DATEVALUE would return an Error, an evaluator may attempt to convert to a Number in other ways (such as by calling VALUE); this is implementation-defined. If the evaluator cannot convert to Number, it returns an Error.
●Logical, the result is implementation-defined, either a Number or Error
●Reference: perform conversion to scalar, then perform as above. If the cell is empty, return 0.
If the expected type is the pseudotype TimeParam, then if value is of type:
●Number, return it.
●Text, pass to TIMEVALUE, and if non-Error, return it. If TIMEVALUE would return an Error, an evaluator may attempt to convert to a Number in other ways (such as by calling VALUE); this is implementation-defined. If the evaluator cannot convert to Number, it returns an Error.
●Logical, the result is implementation-defined, either a Number or Error
●Reference: perform conversion to scalar, then perform as above. If the cell is empty, return 0.
The functions defined under standard operators differ from other functions only by their frequency of use. That frequency of use has lead to the colloquial terminology, standard operators.
Summary: Add two numbers.
Syntax: Number Left + Number Right
Returns: Number
Constraints: None
Semantics: Adds numbers together.
See also Infix Operator "-" 6.4.3, Prefix Operator "+" 6.4.15
Summary: Subtract the second number from the first.
Syntax: Number Left - Number Right
Returns: Number
Constraints: None
Semantics: Subtracts one number from another number.
See also Infix Operator "+" 6.4.2, Prefix Operator "-" 6.4.16
Summary: Multiply two numbers.
Syntax: Number Left * Number Right
Returns: Number
Constraints: None
Semantics: Multiplies numbers together.
See also Infix Operator "+" 6.4.2, Infix Operator "/" 6.4.5
Summary: Divide the second number into the first.
Syntax: Number Left / Number Right
Returns: Number
Constraints: None
Semantics: Divides numbers. Dividing by zero returns an Error.
See also Infix Operator "-" 6.4.3, Infix Operator "*" 6.4.4
Summary: Exponentiation (Power).
Syntax: Number Left ^ Number Right
Returns: Number
Constraints: NOT(AND(Left=0; Right=0)); Evaluators may evaluate expressions where OR(Left != 0; Right != 0) evaluates to a non-Error value.
Semantics: Returns POWER(Left, Right).
See also Infix Operator "*" 6.4.4, POWER 6.16.46
Summary: Report if two values are equal
Syntax: Scalar Left = Scalar Right
Returns: Logical
Constraints: None
Semantics: Returns TRUE if two values are equal. If the values differ in type, return FALSE. If the values are both Number, return TRUE if they are considered equal, else return FALSE. If they are both Text, return TRUE if the two values match, else return FALSE. For Text values, if the calculation setting HOST-CASE-SENSITIVE is false, text is compared but characters differencing only in case are considered equal. If they are both Logicals, return TRUE if they are identical, else return FALSE. Error values cannot be compared to a constant Error value to determine if that is the same Error value.
Evaluators may approximate and test equality of two numeric values with an accuracy of the magnitude of the given values scaled by the number of available bits in the mantissa, ignoring some least significant bits and thus providing compensation for not exactly representable values.
The result of “1=TRUE()” is FALSE for evaluators that implement a distinct Logical type and TRUE if they don't.
See also Infix Operator "<>" 6.4.8
Summary: Report if two values are not equal
Syntax: Any Left <> Any Right
Returns: Logical
Constraints: None
Semantics: Returns NOT(Left = Right) if Left and Right are not Error. For Text values, if the calculation setting HOST-CASE-SENSITIVE is false, text is compared but characters differencing only in case are considered equal.
If either Left and Right are an Error, the result is an Error; this operator cannot be used to determine if two Errors are the same kind of Error.
Note: In some user interfaces the infix operator “<>” is displayed (or accepted) as “!=” or “≠”.
See also Infix Operator "=" 6.4.7
Summary: Report if two values have the given order
Syntax: Scalar Left op Scalar Right
where op is one of: "<", "<=", ">", or ">="
Returns: Logical
Constraints: None
Semantics: Returns TRUE if the two values are less than, less than or equal, greater than, or greater than or equal (respectively). If both Left and Right are Numbers, compare them as numbers. If both Left and Right are Text, compare them as text; if the calculation setting HOST-CASE-SENSITIVE is false, text is compared but characters are compared ignoring case. If the values are both Logical, convert both to Number and then compare as Number.
These functions return one of True, False, or an Error if Left and Right have different types, but it is implementation-defined which of these results will be returned when the types differ.
See also Infix Operator "<>" 6.4.8, Infix Operator "=" 6.4.7
Summary: Concatenate two strings.
Syntax: Text Left & Text Right
Returns: Text
Constraints: None
Semantics: Concatenates two text (string) values.
Note: The infix operator “&” is equivalent to CONCATENATE(Left,Right).
See also Infix Operator "+" 6.4.2, CONCATENATE 6.20.6
Summary: Computes an inclusive range given two references
Syntax: Reference Left : Reference Right
Returns: Reference
Constraints: None
Semantics: Takes two references and computes the range, that is, a reference to the smallest 3-dimensional cube of cells that include both Left and Right including the cells on sheets positioned between Left and Right. Left and Right need not be a single cell. For an expression such as [.B4:.B5]:[.C5] the resulting range is B4:C5. In case Left and/or Right involve a reference list (result of operator reference union), the range is computed and extended for each element of the list(s).
Note: For example, (a,b,c,d denoting one reference each)
(a~b):(c~d) computes a:b:c:d
determining the outermost front-top-left and rear-bottom-right corners.
Left and Right may also be defined names or the result of a function returning a reference, such as INDIRECT.
See also Infix Operator Reference Union 6.4.13, Infix Operator Reference Intersection 6.4.12, INDIRECT 6.14.7
Summary: Compute the intersection of two references
Syntax: Reference Left ! Reference Right
Returns: Reference
Constraints: None
Semantics: Takes two references and computes the intersection - a reference to the intersection of cells in both Left and Right. If there are no cells in common, returns an Error.
If Left or Right are not of type Reference or ReferenceList, an Error shall be returned.
If Left and/or Right are reference lists (result of infix operator reference concatenation), the intersection is computed for each combination of Left and Right, producing a reference list of intersections.
Note 1: For example (a,b,c,d denoting one reference each):
(a~b)!(c~d) will compute (a!c)~(a!d)~(b!c)~(b!d)
If for a resulting intersection there are no cells in common, the element is ignored and omitted from the result list. If for all intersections there are no cells in common and the result list is empty, Error #NULL! is returned.
Note 2: Intersection is notated as "!" in OpenFormula format, but as a space character in some user interfaces.
See also Infix Operator Reference Union 6.4.13
Summary: Concatenate two references
Syntax: Reference Left ~ Reference Right
Returns: ReferenceList
Constraints: None
Semantics: Takes two references and computes the "cell union", which is a concatenation of the reference Left followed by the reference Right. This is not the same as a union in set theory; duplicate references to cells are not removed. The resulting reference will have the number of areas, as reported by AREAS, as AREAS(Left)+AREAS(Right).
Note: Concatenation is notated as "~" in OpenFormula format, but as a comma or “+” in some user interfaces.
If Left or Right are not of type Reference or ReferenceList, an Error shall be returned.
Test Cases:
See also Infix Operator Reference Range 6.4.11, Infix Operator Reference Intersection 6.4.12
Summary: Divide the operand by 100
Syntax: Number Left %
Returns: Number
Constraints: None
Semantics: Computes Left / 100.
See also Prefix Operator "-" 6.4.16, Prefix Operator "+" 6.4.15
Summary: No operation; returns its one argument.
Syntax: + Any Right
Returns: Any
Constraints: None
Semantics: Returns the value given to it. Note that this does not convert a value to the Number type. In fact, it does no conversion at all of a Number, Logical, or Text value - it returns the same Number, Logical, or Text value (respectively). The "+" applied to a reference may return the reference, or an Error.
See also Infix Operator "+" 6.4.2
Summary: Negate its one argument.
Syntax: - Number Right
Returns: Number
Constraints: None
Semantics: Computes 0 - Right.
See also Infix Operator "-" 6.4.3
Matrix functions operate on matrices.
A matrix with M rows and N columns is defined by
 formula
formula
Summary: Calculates the determinant of a matrix.
Syntax: MDETERM( ForceArray Array matrix )
Returns: Number
Constraints: Only square matrices are allowed.
Semantics: Returns the determinant of the matrix. The determinant is defined by
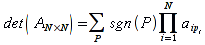
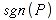
See also MINVERSE 6.5.3
Summary: Returns the inverse of a matrix.
Syntax: MINVERSE( ForceArray Array matrix )
Returns: Array
Constraints: Only square matrices are allowed.
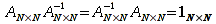
Invertible matrices have a non-zero determinant. If the matrix is not invertible, this function should return an Error value.
See also MDETERM 6.5.2
Summary: Multiplies the matrices A and B.
Syntax: MMULT( ForceArray Array A ; ForceArray Array B )
Returns: Array
Constraints: COLUMNS(A)=ROWS(B)
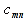
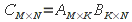 formula
formula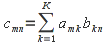 formula
formulaSummary: Creates a unit matrix of a specified dimension N.
Syntax: MUNIT( Integer N )
Returns: Array
Constraints: The dimension has to be greater than zero.
Semantics: Creates the unit matrix (identity matrix) of dimension N.
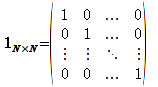
Summary: Returns the transpose of a matrix.
Syntax: TRANSPOSE( Array A )
Returns: Array
Constraints: None
Semantics: Returns the transpose AT of a matrix A, i.e. rows and columns of the matrix are exchanged.
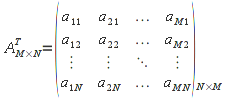 formula
formulaEvaluators shall support unsigned integer values and results of at least 48 bits (values from 0 to 2^48-1 inclusive). Operations that receive or result in a value that cannot be represented within 48 bits are implementation-defined.
Summary: Returns bitwise “and” of its parameters
Syntax: BITAND( Integer X ; Integer Y )
Returns: Number
Constraints: X ≥ 0, Y ≥ 0
Semantics: Returns bitwise “and” of its parameters. In the result, each bit position is 1 if and only if all parameters' bits at that position are also 1; else it is 0.
See also BITOR 6.6.4, BITXOR 6.6.6, AND 6.15.2
Summary: Returns left shift of value x by n bits (“<<”)
Syntax: BITLSHIFT( Integer x ; Integer n )
Returns: Number
Constraints: x ≥ 0
Semantics: Returns left shift of value x by n bit positions:
●If n<0, return BITRSHIFT(x,-n)
●if n=0, return x
●if n>0, return x*2^n
See also BITAND 6.6.2, BITXOR 6.6.6, BITRSHIFT 6.6.5
Summary: Returns bitwise “or” of its parameters
Syntax: BITOR( Integer X ; Integer Y )
Returns: Number
Constraints: X ≥ 0, Y ≥ 0
Semantics: Returns bitwise “or” of its parameters. In the result, each bit position is 1 if any of its parameters' bits at that position are also 1; else it is 0.
See also BITAND 6.6.2, BITXOR 6.6.6, AND 6.15.2
Summary: Returns right shift of value x by n bits (“>>”)
Syntax: BITRSHIFT( Integer x ; Integer n )
Returns: Number
Constraints: x ≥ 0
Semantics: Returns right shift of value x by n bit positions:
●If n<0, return BITLSHIFT(x,-n)
●if n=0, return x
●if n>0, return INT(x/2^n)
See also BITAND 6.6.2, BITXOR 6.6.6, BITLSHIFT 6.6.3
Summary: Returns bitwise “exclusive or” of its parameters
Syntax: BITXOR( Integer X ; Integer Y )
Returns: Number
Constraints: X ≥ 0, Y ≥ 0
Semantics: Returns bitwise “exclusive or” (xor) of its parameters. In the result, each bit position is 1 if one or the other parameters' bits at that position are 1; else it is 0.
See also BITAND 6.6.2, BITOR 6.6.4, OR 6.15.8
Byte-position text functions are like their equivalent ordinary text functions, but manipulate byte positions rather than a count of the number of characters. Byte positions are integers that may depend on the specific text representation used by the implementation. Byte positions are by definition implementation-dependent and reliance upon them reduces interoperability.
The pseudotypes ByteLength and BytePosition are Integers, but their exact meanings and values are not further defined by this specification.
Summary: Returns the starting position of a given text, using byte positions.
Syntax: FINDB( Text Search ; Text T [ ; BytePosition Start ] )
Returns: BytePosition
Semantics: The same as FIND, but using byte positions.
See also FIND 6.20.9 , LEFTB 6.7.3 , RIGHTB 6.7.7
Summary: Returns a selected number of text characters from the left, using a byte position.
Syntax: LEFTB( Text T [ ; ByteLength Length ] )
Returns: Text
Semantics: As LEFT, but using a byte position.
See also LEFT 6.20.12, RIGHT 6.20.19, RIGHTB 6.7.7
Summary: Returns the length of given text in units compatible with byte positions
Syntax: LENB( Text T )
Returns: ByteLength
Constraints: None.
Semantics: As LEN, but compatible with byte position values.
See also LEN 6.20.13, LEFTB 6.7.3, RIGHTB 6.7.7
Summary: Returns extracted text, given an original text, starting position using a byte position, and length.
Syntax: MIDB( Text T ; BytePosition Start ; ByteLength Length )
Returns: Text
Constraints: Length >= 0.
Semantics: As MID, but using byte positions.
See also MID 6.20.15, LEFTB 6.7.3, RIGHTB 6.7.7, REPLACEB 6.7.6
Summary: Returns text where an old text is replaced with a new text, using byte positions.
Syntax: REPLACEB( Text T ; BytePosition Start ; ByteLength Len ; Text New )
Returns: Text
Semantics: As REPLACE, but using byte positions.
See also REPLACE 6.20.17, LEFTB 6.7.3, RIGHTB 6.7.7, MIDB 6.7.5, SUBSTITUTE 6.20.21
Summary: Returns a selected number of text characters from the right, using byte position.
Syntax: RIGHTB( Text T [ ; ByteLength Length ] )
Returns: Text
Semantics: As RIGHT, but using byte positions.
See also RIGHT 6.20.19, LEFTB 6.7.3
Summary: Returns the starting position of a given text, using byte positions.
Syntax: SEARCHB( Text Search ; Text T [ ; BytePosition Start ] )
Returns: BytePosition
Semantics: As SEARCH, but using byte positions.
See also SEARCH 6.20.20, EXACT 6.20.8, FIND 6.20.9, FINDB 6.7.2
Functions for complex numbers.
Summary: Creates a complex number from a given real coefficient and imaginary coefficient.
Syntax: COMPLEX( Number Real ; Number Imaginary [ ; Text Suffix ] )
Returns: Complex
Constraints: None
Semantics: Constructs a complex number by the given coefficients. The third parameter Suffix is optional, and should be either “i” or “j”. Upper case “I” or “J” are not accepted for the suffix parameter.
Summary: Returns the absolute value of a complex number
Syntax: IMABS( Complex X )
Returns: Number
Constraints: None
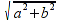
See also IMARGUMENT 6.8.5
Summary: Returns the imaginary coefficient of a complex number
Syntax: IMAGINARY( Complex X )
Returns: Number
Constraints: None
Semantics: If X=a+bi or X=a+bj, then the imaginary coefficient is b.
See also IMREAL 6.8.19
Summary: Returns the complex argument of a complex number
Syntax: IMARGUMENT( Complex X )
Returns: Number
Constraints: None
Semantics: If X=a+bi=r(cosφ + isinφ), a or b is not 0 and -π < φ ≤ π, then the complex argument is φ. φ is expressed by radians. If X=0, then IMARGUMENT(X) is implementation-defined and either 0 or an error.
See also IMABS 6.8.3
Summary: Returns the complex conjugate of a complex number
Syntax: IMCONJUGATE( Complex X )
Returns: Complex
Constraints: None
Semantics: If X=a+bi, then the complex conjugate is a-bi.
Summary: Returns the cosine of a complex number
Syntax: IMCOS( Complex X )
Returns: Complex
Constraints: None
Semantics: If X=a+bi, then cos(X)=cos(a)cosh(b)-sin(a)sinh(b)i.
See also IMSIN 6.8.20
Summary: Returns the hyperbolic cosine of a complex number
Syntax: IMCOSH( Complex N )
Returns: Complex
Constraints: None
Semantics: If N=a+bi, then cosh(N)=cosh(a)cos(b)+sinh(a)sin(b)i.
Summary: Returns the cotangent of a complex number
Syntax: IMCOT(Complex N)
Returns: Complex
Constraints: None
Semantics: Equivalent to the following (except N is computed only once):
IMDIV(IMCOS(N);IMSIN(N))
See also IMTAN 6.8.20
Summary: Returns the cosecant of a complex number
Syntax: IMCSC(Complex N)
Returns: Complex
Constraints: None
Semantics: Equivalent to the following:
IMDIV(1;IMSIN(N))
See also IMSIN 6.8.20
Summary: Returns the hyperbolic cosecant of a complex number
Syntax: IMCSCH( Complex N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic cosecant. This is equivalent to:
IMDIV(1;IMSINH(N))
See also IMSINH, CSCH
Summary: Divides the second number into the first.
Syntax: IMDIV( Complex X ; Complex Y )
Returns: Complex
Constraints: None
Semantics: Given X=a+bi and Y=c+di, return the quotient
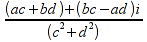
Division by zero returns an Error.
See also IMDIV 6.8.12
Summary: Returns the exponent of e and a complex number.
Syntax: IMEXP( Complex X )
Returns: Complex
Constraints: None
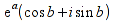
See also IMLN 6.8.14
Summary: Returns the natural logarithm of a complex number.
Syntax: IMLN( Complex X )
Returns: Complex
Constraints: X ≠ 0
Semantics: COMPLEX(LN(IMABS(X)); IMARGUMENT(X)) .
See also IMEXP 6.8.13 , IMLOG10 6.8.15
Summary: Returns the common logarithm of a complex number.
Syntax: IMLOG10( Complex X )
Returns: Complex
Constraints: X ≠ 0
Semantics: IMLOG10(X) is IMDIV(IMLN(X);COMPLEX(LN(10);0)) .
See also IMLN 6.8.14 , IMPOWER 6.8.17
Summary: Returns the binary logarithm of a complex number.
Syntax: IMLOG2( Complex X )
Returns: Complex
Constraints: X ≠ 0
Semantics: IMLOG2(X) is IMDIV(IMLN(X);COMPLEX(LN(2);0)) .
See also IMLN 6.8.14 , IMPOWER 6.8.17
Summary: Returns the complex number X raised to the Yth power.
Syntax: IMPOWER( Complex X ; Complex Y ) or IMPOWER( Complex X ; Number Y)
Returns: Complex
Constraints: X ≠ 0
Semantics: IMPOWER(X;Y) is IMEXP(IMPRODUCT(Y; IMLN(X)))
An evaluator implementing this function shall permit any Number Y but may also allow any Complex Y.
See also IMEXP 6.8.13
Summary: Returns the product of complex numbers.
Syntax: IMPRODUCT( { ComplexSequence N }+ )
Returns: Complex
Constraints: None
Semantics: Multiply the complex numbers together. Given two complex numbers X=a+bi and Y=c+di, the product X*Y = (ac-bd) + (ad+bc)i
See also IMDIV 6.8.12
Summary: Returns the real coefficient of a complex number
Syntax: IMREAL( Complex N )
Returns: Number
Constraints: None
Semantics: If N=a+bi or N=a+bj, then the real coefficient is a.
See also IMAGINARY 6.8.4
Summary: Returns the sine of a complex number
Syntax: IMSIN( Complex N )
Returns: Complex
Constraints: None
Semantics: If N=a+bi, then sin(N)=sin(a)cosh(b)+cos(a)sinh(b)i.
See also IMCOS 6.8.7
Summary: Returns the hyperbolic sine of a complex number
Syntax: IMSINH( Complex N )
Returns: Complex
Constraints: None
Semantics: If N=a+bi, then sinh(N)=sinh(a)cos(b)+cosh(a)sin(b)i.
Summary: Returns the secant of a complex number
Syntax: IMSEC(Complex N)
Returns: Complex
Constraints: None
Semantics: Equivalent to the following:
IMDIV(1;IMCOS(N))
See also IMCOS 6.8.7
Summary: Returns the hyperbolic secant of a complex number
Syntax: IMSECH( Complex N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic secant. This is equivalent to:
IMDIV(1;IMCOSH(N))
See also IMCOSH, SECH
Summary: Returns the square root of a complex number
Syntax: IMSQRT( Complex N )
Returns: Complex
Constraints: None
Semantics: If N= 0+0i, then IMSQRT(N)=0. Otherwise IMSQRT(N) is SQRT(IMABS(N)) * sin(IMARGUMENT(N)/2) + SQRT(IMABS(N)) * cos(IMARGUMENT(N)/2)i.
See also IMPOWER 6.8.17
Summary: Subtracts the second complex number from the first.
Syntax: IMSUB( Complex X ; Complex Y )
Returns: Complex
Constraints: None
Semantics: Subtract complex number Y from X.
See also IMSUM 6.8.26
Summary: Sums (add) a set of complex numbers, including all numbers in ranges
Syntax: IMSUM( { ComplexSequence N }+ )
Returns: Complex Number
Constraints: None
Semantics: Adds complex numbers together. Text that cannot be converted to a complex number is ignored.
It is implementation-defined what happens if this function is given zero parameters; an evaluator may either produce an Error or the Number 0 if it is given zero parameters.
See also IMSUB 6.8.25
Summary: Returns the tangent of a complex number
Syntax: IMTAN(Complex N)
Returns: Complex
Constraints: None
Semantics: Equivalent to the following (except N is computed only once):
IMDIV(IMSIN(N);IMCOS(N))
See also IMSIN, IMCOS, IMCOT 6.8.25
Database functions use the variables, Database 4.11.9, Field 4.11.10, and Criteria 4.11.11.
The results of database functions may change when the values of the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties change. 3.4
Summary: Finds the average of values in a given field from the records (rows) in a database that match a search criteria.
Syntax: DAVERAGE( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform AVERAGE on data records in database D field F that match criteria C.
See also AVERAGE 6.18.3, COUNT 6.13.6, DSUM 6.9.11, DCOUNT 6.9.3, SUM 6.16.61
Summary: Counts the number of records (rows) in a database that match a search criteria and contain numerical values.
Syntax: DCOUNT( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform COUNT on data records in database D field F that match criteria C.
See also COUNT 6.13.6, COUNTA 6.13.7, DCOUNTA 6.9.4, DSUM 6.9.11
Summary: Counts the number of records (rows) in a database that match a search criteria and contain values (as COUNTA).
Syntax: DCOUNTA( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform COUNTA on data records in database D field F that match criteria C.
See also COUNT 6.13.6, COUNTA 6.13.7, DCOUNT 6.9.3, DSUM 6.9.11
Summary: Gets the single value in the field from the single record (row) in a database that matches a search criteria.
Syntax: DGET( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Extracts the value in field F of the one data record in database D that matches criteria C. If no records match, or more than one matches, it returns an Error.
See also DMAX 6.9.6, DMIN 6.9.7, DSUM 6.9.11
Summary: Finds the maximum value in a given field from the records (rows) in a database that match a search criteria.
Syntax: DMAX( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform MAX on only the data records in database D field F that match criteria C.
See also MAX 6.18.45, DMIN 6.9.7, MIN 6.18.48
Summary: Finds the minimum value in a given field from the records (rows) in a database that match a search criteria.
Syntax: DMIN( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform MIN on only the data records in database D field F that match criteria C.
See also MIN 6.18.48, DMAX 6.9.6, MAX 6.18.45
Summary: Finds the product of values in a given field from the records (rows) in a database that match a search criteria.
Syntax: DPRODUCT( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Multiply together only the data records in database D field F that match criteria C.
See also SUM 6.16.61, DSUM 6.9.11
Summary: Finds the sample standard deviation in a given field from the records (rows) in a database that match a search criteria.
Syntax: DSTDEV( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform STDEV on only the data records in database D field F that match criteria C.
See also STDEV 6.18.72, DSTDEVP 6.9.10
Summary: Finds the population standard deviation in a given field from the records (rows) in a database that match a search criteria.
Syntax: DSTDEVP( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform STDEVP on only the data records in database D field F that match criteria C.
See also STDEVP 6.18.74, DSTDEV 6.9.9
Summary: Finds the sum of values in a given field from the records (rows) in a database that match a search criteria.
Syntax: DSUM( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform SUM on only the data records in database D field F that match criteria C.
See also SUM 6.16.61, DMIN 6.9.7, DMAX 6.9.6
Summary: Finds the sample variance in a given field from the records (rows) in a database that match a search criteria.
Syntax: DVAR( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform VAR on only the data records in database D field F that match criteria C.
See also VAR 6.18.82, DVARP 6.9.13
Summary: Finds the population variance in a given field from the records (rows) in a database that match a search criteria.
Syntax: DVARP( Database D ; Field F ; Criteria C )
Returns: Number
Constraints: None
Semantics: Perform VARP on only the data records in database D field F that match criteria C.
See also VARP 6.18.84, DVAR 6.9.12
Summary: Constructs a date from year, month, and day of month.
Syntax: DATE( Integer Year ; Integer Month ; Integer Day )
Returns: Date
Constraints: 1904 <= Year <= 9956; 1 <= Month <= 12; 1 <= Day <= 31; Evaluators may evaluate expressions that do no meet this constraint.
Semantics: This computes the date's serial number given Year, Month, and Day of the Gregorian calendar. Fractional values are truncated. Month > 12 and Day > days of Month will roll over the date, computing the result by adding months and days as necessary. The value of the serial number depends on the current epoch.
See also TIME 6.10.17, DATEVALUE 6.10.4
Summary: Returns the difference in years, months, or days of two date numbers.
Syntax: DATEDIF( DateParam StartDate ; DateParam EndDate ; Text Format )
Returns: Number
Constraints: None
Semantics: Compute difference of StartDate and EndDate, in the units given by Format.
The Format is a code from the following table, entered as text, that specifies the format you want the result of DATEDIF to have.
|
format |
Returns the number of |
|
y |
Years |
|
m |
Months. If there is not a complete month between the dates, 0 will be returned. |
|
d |
Days |
|
md |
Days, ignoring months and years |
|
ym |
Months, ignoring years |
|
yd |
Days, ignoring years |
See also DAYS360 6.10.7, DAYS 6.10.6, Infix Operator “-” 6.4.3
Summary: Returns the date serial number from given text.
Syntax: DATEVALUE( Text D )
Returns: Date
Constraints: None
Semantics: This computes the serial number of the text string D, using the current locale. This function shall accept ISO date format (YYYY-MM-DD), which is locale-independent. It is semantically equal VALUE(Date) if Date has a date format, since text matching a date format is automatically converted to a serial number when used as a Number. If the text of D has a combined date and time format, e.g. YYYY-MM-DD HH:MM:SS, the integer part of the date serial number is returned. If the text of Date does not have a date or time format, an evaluator may return an Error. See VALUE for more information on date formats. The value of the serial number depends on the current epoch.
See also TIME 6.10.17, DATE 6.10.2, TIMEVALUE 6.10.18, VALUE 6.13.34
Summary: Returns the day from a date.
Syntax: DAY( DateParam Date )
Returns: Number
Constraints: None
Semantics: Returns the day portion of a date.
See also MONTH 6.10.13, YEAR 6.10.23
Summary: Returns the number of days between two dates
Syntax: DAYS( DateParam EndDate ; DateParam StartDate )
Returns: Number
Constraints: None
Semantics: Returns the number of days between two dates. If StartDate and EndDate are Numbers, this is EndDate – StartDate. If they are both Text, this is DATEVALUE(StartDate) – DATEVALUE(EndDate).
See also DATEDIF 6.10.3, DAYS360 6.10.7, MONTH 6.10.13, YEAR 6.10.23, Infix Operator “-” 6.4.3
Summary: Returns the number of days between two dates using the 360-day year
Syntax: DAYS360( DateParam StartDate ; DateParam EndDate [ ; Integer Method = 0 ] )
Returns: Number
Constraints: 0 <= Method <= 1
Semantics: Returns the number of days between two dates, using the 360-day year system (12 30-month days). In this system, February always has 30 days and there are no leap years.
If method is 0, it uses the National Association of Securities Dealers (NASD) method, also known as the U.S. method. If the method is 1, the European method is used.
The US/NASD Method (30US/360):
1.Truncate date values, set sign=1.
2.If StartDate's day-of-month is 31, it is changed to 30.
3.Otherwise, if StartDate's day-of-month is the last day of February, it is changed to 30.
4.If EndDate's day-of-month is 31 and StartDate's day-of-month is 30 (after having applied a change for #2 or #3, if necessary), EndDate's day-of-month is changed to 30.
Note 1: This calculation is slightly different from Basis 0 (4.11.7 Basis). Dates are never swapped.
The European Method (30E/360):
1.Truncate date values, set sign=1.
2.If StartDate is after EndDate then swap dates and set sign=-1.
3.If StartDate's day-of-month is 31, it is changed to 30.
4.If EndDate's day-of-month is 31, it is changed to 30.
Note 2: Days in February are never changed.
Note 3: This calculation is identical to Basis 4 (4.11.7 Basis)
For both methods the value then returned is
sign * ((EndDate.year*360 + EndDate.month*30 + EndDate.day) - (StartDate.year*360 + StartDate.month*30 + StartDate.day))
See also DAYS 6.10.6, DATEDIF 6.10.3
Summary: Returns the serial number of a given date when MonthAdd months is added
Syntax: EDATE( DateParam StartDate ; Number MonthAdd )
Returns: Number
Constraints: None
Semantics: First truncate StartDate and MonthAdd, then add MonthAdd number of months. MonthAdd can be positive, negative, or 0; if zero, the number representing StartDate (in the current epoch) is returned.
If after adding the given number of months, the day of month in the new month is larger than the number of days in the given month, the day of month is adjusted to the last day of the new month. Then the serial number of that date is returned.
See also DAYS 6.10.6, DATEDIF 6.10.3, EOMONTH 6.10.9
Summary: Returns the serial number of the end of a month, given date plus MonthAdd months
Syntax: EOMONTH( DateParam StartDate ; Integer MonthAdd )
Returns: Number
Constraints: None
Semantics: First truncate StartDate and MonthAdd, then add MonthAdd number of months. MonthAdd can be positive, negative, or 0. Then return the serial number representing the end of that month. Due to the semantics of this function, the value of DAY(StartDate) is irrelevant.
See also EDATE 6.10.8
Summary: Extracts the hour (0 through 23) from a time.
Syntax: HOUR( TimeParam T )
Returns: Number
Constraints: None
Semantics: Extract from T the hour value, 0 through 23, as per a 24-hour clock. This is equal to:
DayFraction=(T-INT(T))
Hour=INT(DayFraction*24)
See also MONTH 6.10.13, DAY 6.10.5, MINUTE 6.10.12, SECOND 6.10.16
Summary: Determines the ISO week number of the year for a given date.
Syntax: ISOWEEKNUM( DateParam Date )
Returns: Number
Constraints: None
Semantics: Returns the ordinal number of the [ISO8601] calendar week in the year for the given date. ISO 8601 defines the calendar week as a time interval of seven calendar days starting with a Monday, and the first calendar week of a year as the one that includes the first Thursday of that year.
See also DAY 6.10.5, MONTH 6.10.13, YEAR 6.10.23, WEEKDAY 6.10.20, WEEKNUM 6.10.21
Summary: Extracts the minute (0 through 59) from a time.
Syntax: MINUTE( TimeParam T )
Returns: Number
Constraints: None
Semantics: Extract from T the minute value, 0 through 59, as per a clock. This is equal to:
DayFraction=(T-INT(T))
HourFraction=(DayFraction*24-INT(DayFraction*24))
Minute=INT(HourFraction*60)
See also MONTH 6.10.13, DAY 6.10.5, HOUR 6.10.10, SECOND 6.10.16
Summary: Extracts the month from a date.
Syntax: MONTH( DateParam Date )
Returns: Number
Constraints: None
Semantics: Takes a date and returns the month portion.
See also YEAR 6.10.23, DAY 6.10.5
Summary: Returns the whole number of work days between two dates.
Syntax: NETWORKDAYS( DateParam Date1 ; DateParam Date2 [ ; [ DateSequence holidays ] [ ; LogicalSequence workdays ] ] )
Returns: Number
Constraints: None
Semantics: Returns the whole number of work days between two dates.
Work days are defined as non-weekend, non-holiday days. By default, weekends are Saturdays and Sundays and there are no holidays.
The optional 3rd parameter Holidays can be used to specify a list of dates to be treated as holidays. Note that this parameter can be omitted as an empty parameter (two consecutive ;; semicolons) to be able to pass the set of Workdays without Holidays.
The optional 4th parameter Workdays can be used to specify a different definition for the standard work week by passing in a list of numbers which define which days of the week are workdays (indicated by 0) or not (indicated by non-zero) in order Sunday, Monday,...,Saturday. So, the default definition of the work week excludes Saturday and Sunday and is: {1;0;0;0;0;0;1}. To define the work week as excluding Friday and Saturday, the third parameter would be: {0;0;0;0;0;1;1}.
Summary: Returns the serial number of the current date and time.
Syntax: NOW()
Returns: DateTime
Constraints: None
Semantics: This returns the current day and time serial number, using the current locale. If you want only the serial number of the current day, use TODAY 6.10.19.
See also DATE 6.10.2, TIME 6.10.17, TODAY 6.10.19
Summary: Extracts the second (the integer 0 through 59) from a time. This function presumes that leap seconds never exist.
Syntax: SECOND( TimeParam T )
Returns: Number
Constraints: None
Semantics: Extract from T the second value, 0 through 59, as per a clock. Note that this returns an integer, without a fractional part. Note also that this rounds to the nearest second, instead of returning the integer part of the seconds. This is equal to:
DayFraction=(T-INT(T))
HourFraction=(DayFraction*24-INT(DayFraction*24))
MinuteFraction=(HourFraction*60-INT(HourFraction*60))
Second=ROUND(MinuteFraction*60)
See also MONTH 6.10.13, DAY 6.10.5, HOUR 6.10.10, MINUTE 6.10.12
Summary: Constructs a time value from hours, minutes, and seconds.
Syntax: TIME( Number hours ; Number minutes ; Number seconds )
Returns: Time
Constraints: None. Evaluators may first perform INT() on the hour, minute, and second before doing the calculation.
Semantics: Returns the fraction of the day consumed by the given time, i.e.:
((hours*60*60)+(minutes*60)+seconds)/(24*60*60)
Time is a subtype of number, where a time value of 1 = 1 day = 24 hours.
Hours, minutes, and seconds may be any number (they shall not be limited to the ranges 0..24, 0..59, or 0..60 respectively).
See also DATE 6.10.2
Summary: Returns a time serial number from given text.
Syntax: TIMEVALUE( Text T )
Returns: Time
Constraints: None
Semantics: This computes the serial number of the text string T, which is a time, using the current locale. This function shall accept ISO time format (HH:MM:SS), which is locale-independent. If the text of T has a combined date and time format, e.g. YYYY-MM-DD HH:MM:SS, the fractional part of the date serial number is returned. If the text of T does not have a time format, an evaluator may attempt to convert the number another way (e.g., using VALUE), or it may return an Error (this is implementation-dependent).
See also TIME 6.10.17, DATE 6.10.2, DATEVALUE 6.10.4, VALUE 6.13.34
Summary: Returns the serial number of today.
Syntax: TODAY()
Returns: Date
Constraints: None
Semantics: This returns the current day's serial number, using current locale. This only returns the date, not the datetime value. For the specific time of day as well, use NOW 6.10.15.
See also TIME 6.10.17, NOW 6.10.15
Summary: Extracts the day of the week from a date; if text, uses current locale to convert to a date.
Syntax: WEEKDAY( DateParam Date [ ; Integer Type = 1 ] )
Returns: Number
Constraints: None
Semantics: Returns the day of the week from a date, as a number from 0 through 7. The exact meaning depends on the value of Type:
1.When Type is 1, Sunday is the first day of the week, with value 1; Saturday has value 7.
2.When Type is 2, Monday is the first day of the week, with value 1; Sunday has value 7.
3.When Type is 3, Monday is the first day of the week, with value 0; Sunday has value 6.
|
Day of Week |
Type=1 Result |
Type=2 Result |
Type=3 Result |
|
Sunday |
1 |
7 |
6 |
|
Monday |
2 |
1 |
0 |
|
Tuesday |
3 |
2 |
1 |
|
Wednesday |
4 |
3 |
2 |
|
Thursday |
5 |
4 |
3 |
|
Friday |
6 |
5 |
4 |
|
Saturday |
7 |
6 |
5 |
See also DAY 6.10.5, MONTH 6.10.13, YEAR 6.10.23
Summary: Determines the week number of the year for a given date.
Syntax: WEEKNUM( DateParam Date [ ; Number Mode = 1 ] )
Returns: Number
Constraints: 1 ≤ Mode ≤ 2, or 11 ≤ Mode ≤ 17, or Mode = 21, or Mode = 150
Semantics: Returns the number of the week in the year for the given date.
For Mode={1, 2, 11, 12, ..., 17} the week containing January 1 is the first week of the year, and is numbered week 1. The week starts on {Sunday, Monday, Monday, Tuesday, ..., Sunday}.
Mode 21 or 150 are both [ISO8601], the week starts on Monday and the week containing the first Thursday of the year is the first week of the year, and is numbered week 1.
See also DAY 6.10.5, MONTH 6.10.13, YEAR 6.10.23, WEEKDAY 6.10.20, ISOWEEKNUM 6.10.11
Summary: Returns the date serial number which is a specified number of work days before or after an input date.
Syntax: WORKDAY( DateParam Date ; Number Offset [ ; [ DateSequence Holidays ] [ ; LogicalSequence Workdays ] ] )
Returns: DateTime
Constraints: None
Semantics: Returns the date serial number for the day that is offset from the input Date parameter by the number of work days specified in the Offset parameter. If Offset is negative, the offset will return a date prior to Date. If Offset is positive, a date later Date is returned. If Offset is zero, then Date is returned.
Work days are defined as non-weekend, non-holiday days. By default, weekends are Saturdays and Sundays and there are no holidays.
The optional 3rd parameter Holidays can be used to specify a list of dates to be treated as holidays. Note that this parameter can be omitted as an empty parameter (two consecutive ;; semicolons) to be able to pass the set of Workdays without Holidays.
The optional 4th parameter Workdays can be used to specify a different definition for the standard work week by passing in a list of numbers which define which days of the week are workdays (indicated by 0) or not (indicated by non-zero) in order Sunday, Monday,...,Saturday. If all seven numbers in Workdays are non-zero and Offset is also non-zero, WORKDAY returns an error.
Note: The default definition of the work week that excludes Saturday and Sunday and is: {1;0;0;0;0;0;1}. To define the workweek as excluding Friday and Saturday, the third parameter would be: {0;0;0;0;0;1;1}.
Summary: Extracts the year from a date given in the current locale of the evaluator.
Syntax: YEAR( DateParam D )
Returns: Number
Constraints: None
Semantics: Parses a date-formatted string in the current locale's format and returns the year portion.
If a year is given as a two-digit number, as in "05-21-15", then the year returned is either 1915 or 2015, depending upon the break point in the calculation context. In an OpenDocument document, this break point is determined by HOST-NULL-YEAR.
Evaluators shall support extracting the year from a date beginning in 1900. Three-digit year numbers precede adoption of the Gregorian calendar, and may return either an Error or the year number. Four-digit year numbers preceding 1582 (inception of the Gregorian Calendar) may return either an Error or the year number. Four-digit year numbers following 1582 should return the year number.
See also MONTH 6.10.13, DAY 6.10.5, VALUE 6.13.34
Summary: Extracts the number of years (including fractional part) between two dates
Syntax: YEARFRAC( DateParam StartDate ; DateParam EndDate [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: None
Semantics: Computes the fraction of the number of years between a StartDate and EndDate.
Basis indicates the day-count convention to use in the calculation. 4.11.7
See also DATEDIF 6.10.3
OpenFormula defines two functions, DDE and HYPERLINK, for accessing external data.
Summary: Returns data from a DDE request
Syntax: DDE( Text server ; Text topic ; Text item [ ; Integer Mode = 0 ] )
Returns: Number|Text
Constraints: None
Semantics: Performs a DDE request and returns its result. The request invokes the service server on the topic named as topic, requesting that it reply with the information on item.
Evaluators may choose to not perform this function on every recalculation, but instead cache an answer and require a separate action to re-perform these requests. Evaluators shall perform this request on initial load when their security policies permit it.
Mode is an optional parameter that determines how the results are returned:
|
Mode |
Effect |
|
0 or missing |
Data converted to number using VALUE in the number style's locale of the default table cell style |
|
1 |
Data converted to number using VALUE in the English-US (en_US) locale |
|
2 |
Data retrieved as text (not converted to number) |
In an OpenDocument spreadsheet document the default table cell style is specified with table:default-cell-style-name. Its number:number-style specified by style:data-style-name specifies the locale to use in the conversion.
The DDE function is non-portable because it depends on availability of external programs (server parameter) and their interpretation of the topic and item parameters.
Summary: Creation of a hyperlink involving an evaluated expression.
Syntax: HYPERLINK( Text IRI [ ; Text|Number FunctionResult ] )
Returns: Text or Number
Constraints: None
Semantics: The default for the second argument is the value of the first argument. The second argument value is returned.
In addition, hosting environments may interpret expressions containing HYPERLINK function calls as calling for an implementation-dependent creation of a hypertext link based on the expression containing the HYPERLINK function calls.
The financial functions are defined for use in financial calculations.
An annuity is a recurring series of payments. A "simple annuity" is one where equal payments are made at equal intervals, and the compounding of interest occurs at those same intervals. The time between payments is called the "payment interval". Where payments are made at the end of the payment interval, it is called an "ordinary annuity". Where payments are made at the beginning of the payment interval, it is called an "annuity due". Periods are numbered starting at 1.
Financial functions defined in this standard use a cash flow sign convention where outgoing cash flows are negative and incoming cash flows are positive.
Summary: Calculates the accrued interest for securities with periodic interest payments.
Syntax: ACCRINT( DateParam issue ; DateParam first ; DateParam settlement ; Number coupon ; Number par ; Integer frequency [ ; Basis basis = 0 [ ; Logical calc_method = TRUE() ] ] )
Returns: Currency
Constraints: issue < first < settlement ; coupon > 0; par > 0
frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
|
12 |
Monthly |
Semantics: Calculates the accrued interest for securities with periodic interest payments. ACCRINT supports short, standard, and long coupon periods.
If calc_method is TRUE (the default) then ACCRINT returns the sum of the accrued interest in each coupon period from issue date until settlement date. If calc_method is FALSE then ACCRINT returns the sum of the accrued interest in each coupon period from first date until settlement date. For each coupon period, the interest is par*coupon*YEARFRAC(start-of-period;end-of-period; basis)
issue The security's issue or dated date.
first The security's first interest date.
settlement The security's settlement date.
coupon The security's annual coupon rate.
par The security's par value, that is, the principal to be paid at maturity.
frequency The number of coupon payments per year.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
calc_method A logical value that specifies how to treat the case where settlement>first.
See also ACCRINTM 6.12.3
Summary: Calculates the accrued interest for securities that pay at maturity.
Syntax: ACCRINT( DateParam issue ; DateParam settlement ; Number coupon ; Number par [ ; Basis basis = 0 ] )
Returns: Currency
Constraints: coupon > 0; par > 0
Semantics: Calculates the accrued interest for securities that pay at maturity.
issue The security's issue or dated date.
settlement The security's maturity date.
coupon The security's annual coupon rate.
par The security's par value, that is, the principal to be paid at maturity.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
See also ACCRINT 6.12.2
Summary: Calculates the amortization value for the French accounting system using linear depreciation (l'amortissement linéaire comptable) .
Syntax: AMORLINC( Number cost ; DateParam purchaseDate ; DateParam firstPeriodEndDate ; Number salvage ; Integer period ; Number rate [ ; Basis basis = 0 ] )
Returns: Currency
Constraints: cost > 0; purchaseDate <= firstPeriodEndDate; salvage >= 0; period >= 0; rate > 0
Semantics: Calculates the amortization value for the French accounting system using linear depreciation.
cost The value of the asset at the date of aquisition.
purchaseDate The date of aquisition.
firstPeriodEndDate The end date of the first depreciation period.
salvage The value of the asset at the end of the depreciation life time.
period Which period the depreciation should be calculated for.
rate The rate of depreciation.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
When period = 0:
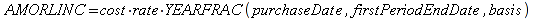
For full periods, where period > 0, the depreciation is cost * rate
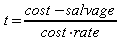
For the last period, possibly a partial period, the depreciation = cost-salvage-accumulated-depreciation, where accumulated-depreciation is the sum of the depreciation in period 0 plus any full period depreciations.
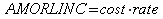
When period > depreciated life of the asset, i.e., when period > (cost-salvage)/(cost*rate) then the depreciation is 0.

Note: The behavior of this function is implementation-defined in cases where purchaseDate = firstPeriodEndDate.
See also DB 6.12.13, DDB 6.12.14, YEARFRAC 6.10.24
Summary: Calculates the number of days between the beginning of the coupon period that contains the settlement date and the settlement date.
Syntax: COUPDAYBS( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Number
Constraints: settlement < maturity
frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculate the number of days from the beginning of the coupon period to the settlement date.
settlement The settlement date.
maturity The maturity date.
frequency The number of coupon payments per year.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
See also COUPDAYS 6.12.6 , COUPDAYSNC 6.12.7 , COUPNCD 6.12.7 , COUPNUM 6.12.9 , COUPPCD 6.12.10
Summary: Calculates the number of days in a coupon period that contains the settlement date.
Syntax: COUPDAYS( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Number
Constraints: settlement < maturity
frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculates the number of days in the coupon period containing the settlement date.
settlement The settlement date.
maturity The maturity date.
frequency The number of coupon payments per year.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
See also COUPDAYBS 6.12.5 , COUPDAYSNC 6.12.7 , COUPNCD 6.12.7 , COUPNUM 6.12.9 , COUPPCD 6.12.10
Summary: Calculates the number of days between a settlement date and the next coupon date.
Syntax: COUPDAYNC( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Number
Constraints: settlement < maturity
frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculates the number of days between the settlement date and the next coupon date.
settlement The settlement date.
maturity The maturity date.
frequency The number of coupon payments per year.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7
See also COUPDAYBS 6.12.5 , COUPDAYS 6.12.6 , COUPNCD 6.12.7 , COUPNUM 6.12.9 , COUPPCD 6.12.10
Summary: Calculates the next coupon date following a settlement.
Syntax: COUPNCD( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Date
Constraints: settlement < maturity
frequency is the number of coupon payments per year. frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculates the next coupon date after the settlement date based on the maturity (expiration) date of the asset, the frequency of coupon payments and the day-count basis.
Basis indicates the day-count convention to use in the calculation. 4.11.7
Summary: Calculates the number of outstanding coupons between settlement and maturity dates.
Syntax: COUPNUM( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Number
Constraints: frequency is the number of coupon payments per year. frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculates the number of coupons in the interval between the settlement and the maturity (expiration) date of the asset, the frequency of coupon payments and the day-count basis.
Basis indicates the day-count convention to use in the calculation. 4.11.7
See also COUPDAYBS 6.12.5, COUPDAYS 6.12.6, COUPDAYSNC 6.12.7, COUPNCD 6.12.7, COUPPCD 6.12.10
Summary: Calculates the next coupon date prior a settlement.
Syntax: COUPPCD( DateParam settlement ; DateParam maturity ; Integer frequency [ ; Basis basis = 0 ] )
Returns: Date
Constraints: settlement < maturity
frequency is the number of coupon payments per year. frequency is one of the following values:
|
frequency |
Frequency of coupon payments |
|
1 |
Annual |
|
2 |
Semiannual |
|
4 |
Quarterly |
Semantics: Calculates the next coupon date prior to the settlement date based on the maturity (expiration) date of the asset, the frequency of coupon payments and the day-count basis.
Basis indicates the day-count convention to use in the calculation. 4.11.7
See also COUPDAYBS 6.12.5, COUPDAYS 6.12.6, COUPDAYSNC 6.12.7, COUPNCD 6.12.7, COUPNUM 6.12.9
Summary: Calculates a cumulative interest payment.
Syntax: CUMIPMT( Number rate ; Number periods ; Number value ; Integer start ; Integer end ; Integer type )
Returns: Currency
Constraints: rate > 0; value > 0; 1 <= start <= end <= periods
type is one of the following values:
|
type |
Maturity date |
|
0 |
due at the end |
|
1 |
due at the beginning |
Semantics: Calculates the cumulative interest payment.
rate The interest rate per period.
periods The number of periods.
value The current value of the loan.
start The starting period.
end The end period.
type The maturity date, the beginning or the end of a period.

See also IPMT 6.12.23, CUMPRINC 6.12.12
Summary: Calculates a cumulative principal payment.
Syntax: CUMPRINC( Number rate ; Number periods ; Number value ; Integer start ; Integer end ; Integer type )
Returns: Currency
Constraints: type is one of the following values:
|
type |
Maturity date |
|
0 |
due at the end |
|
1 |
due at the beginning |
Semantics: Calculates the cumulative principal payment.
rate The interest rate per period.
periods The number of periods.
value The current value of the loan.
start The starting period.
end The end period.
type The maturity date, the beginning or the end of a period.

See also PPMT 6.12.37 , CUMIPMT 6.12.11
Summary: Compute the depreciation allowance of an asset.
Syntax: DB( Number cost ; Number salvage ; Integer lifeTime ; Number period [ ; Number month = 12 ] )
Returns: Currency
Constraints: cost > 0, salvage >= 0, lifetime >0; period > 0; 0 < month < 13
Semantics: Calculate the depreciation allowance of an asset with an initial value of cost, an expected useful lifeTime, and a final salvage value at a specified period of time, using the fixed-declining balance method. The parameters are:
●cost: the total amount paid for the asset.
●salvage: the salvage value at the end of the lifeTime.
●lifeTime: the number of periods that the depreciation will occur over. A positive integer.
●period: the time period for which you want to find the depreciation allowance, in the same units as lifeTime.
●month: (optional) the number of months in the first year of depreciation, assumed to be 12, if not specified. If a value is specified for month, lifeTime and period are assumed to be measured in years.
The rate is calculated as follows:
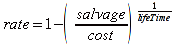
and is rounded to 3 decimals.
For the first period the residual value is
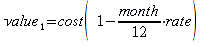
For all periods, where period <= lifeTime, the residual value is calculated by
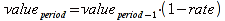
If month was specified, the residual value for the period after lifeTime becomes
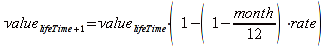
The depreciation allowance for the first period is

For all other periods the allowance is calculated by
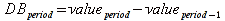
For all periods, where period > lifeTime + 1 – INT(month/12), the depreciation allowance is zero.
See also DDB 6.12.14, SLN 6.12.45
Summary: Compute the amount of depreciation at a given period of time.
Syntax: DDB( Number cost ; Number salvage ; Number lifeTime ; Number period [ ; Number declinationFactor = 2 ] )
Returns: Currency
Constraints: cost >= 0, salvage >= 0, salvage <= cost, 1 <= period <= lifeTime, declinationFactor > 0
Semantics: Compute the amount of depreciation of an asset at a given period of time. The parameters are:
●cost: the total amount paid for the asset.
●salvage: the salvage value at the end of the LifeTime
●lifeTime: the number of periods that the depreciation will occur over.
●period: the period for which a depreciation value is specified.
●declinationFactor: the method of calculating depreciation, the rate at which the balance declines. Defaults to 2. If 2, double-declining balance is used.
To calculate depreciation, DDB uses a fixed rate. When declinationFactor = 2 this is the double-declining-balance method (because it is double the straight-line rate that would depreciate the asset to zero). The rate is given by:
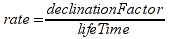
The depreciation each period is calculated as
depreciation_of_period = MIN( book_value_at_start_of_ period * rate; book_value_at_start_of_ period - salvage )
Thus the asset depreciates at rate until the book value is salvage value.
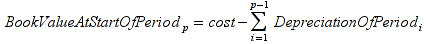
To allow also non-integer period values this algorithm may be used:
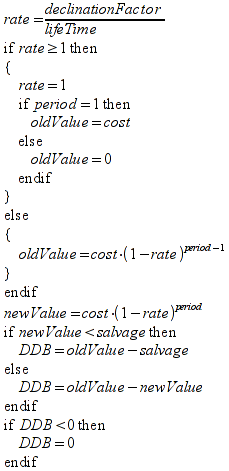
If period is an Integer number, the relation between DDB and VDB is:
DDB( cost ; salvage ; lifeTime ; period ; declinationFactor )
equals
VDB( cost ; salvage ; lifeTime ; period - 1 ; period ; declinationFactor ; TRUE() )
See also SLN 6.12.45, VDB 6.12.50
Summary: Returns the discount rate of a security.
Syntax: DISC( DateParam settlement ; DateParam maturity ; Number price ; Number redemption [ ; Basis basis = 0 ] )
Returns: Percentage
Constraints: settlement < maturity
Semantics: Calculates the discount rate of a security.
settlement The settlement date of the security.
maturity The maturity date.
price The price of the security.
redemption The redemption value of the security.
basis Basis indicates the day-count convention to use in the calculation. 4.11.7

See also YEARFRAC 6.10.24
Summary: Converts a fractional dollar representation into a decimal representation.
Syntax: DOLLARDE( Number fractional ; Integer denominator )
Returns: Number
Constraints: denominator > 0
Semantics: Converts a fractional dollar representation into a decimal representation.
fractional Decimal fraction.
denominator Denominator of the fraction.
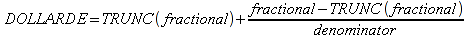
See also DOLLARFR 6.12.17 , TRUNC 6.17.8
Summary: Converts a decimal dollar representation into a fractional representation.
Syntax: DOLLARFR( Number decimal ; Integer denominator )
Returns: Number
Constraints: denominator > 0
Semantics: Converts a decimal dollar representation into a fractional representation.
decimal Decimal number.
denominator Denominator of the fraction.
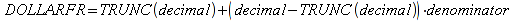
See also DOLLARDE 6.12.16, TRUNC 6.17.8
Summary: Returns the Macaulay duration of a fixed interest security in years
Syntax: DURATION( Date Settlement ; Date Maturity ; Number Coupon ; Number Yield ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Yield >=0, Coupon >= 0, Settlement <= Maturity; Frequency = 1, 2, 4
Semantics: Computes the Macaulay duration, given:
Settlement the date of purchase of the securityMaturity the date when the security matures
Coupon the annual nominal rate of interest
Yield the annual yield of the security
Frequency number of interest payments per year
Basis Basis indicates the day-count convention to use in the calculation. 4.11.7
See also MDURATION 6.12.26
Summary: Returns the net annual interest rate for a nominal interest rate.
Syntax: EFFECT( Number rate ; Integer payments )
Returns: Number
Constraints: rate >= 0; payments > 0
Semantics: Nominal interest refers to the amount of interest due at the end of a calculation period. Effective interest increases with the number of payments made. In other words, interest is often paid in installments (for example, monthly or quarterly) before the end of the calculation period.
rate The interest rate per period.
payments The number of payments per period.
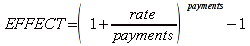
See also NOMINAL 6.12.28
Summary: Compute the future value (FV) of an investment.
Syntax: FV( Number Rate ; Number Nper ; Number Payment [ ; [ Number Pv = 0 ] [ ; Number PayType = 0 ] ] )
Returns: Currency
Constraints: None.
Semantics: Computes the future value of an investment. The parameters are:
●Rate: the interest rate per period.
●Nper: the total number of payment periods.
●Payment: the payment made in each period.
●Pv: the present value; default is 0.
●PayType: the type of payment, defaults to 0. It is 0 if payments are due at the end of the period; 1 if they are due at the beginning of the period.
See PV 6.12.41 for the equation this solves.
See also PV 6.12.41, NPER 6.12.29, PMT 6.12.36, RATE 6.12.42
Summary: Returns the accumulated value given starting capital and a series of interest rates.
Syntax: FVSCHEDULE( Number Principal ; NumberSequence Schedule )
Returns: Currency
Constraints: None.
Semantics: Returns the accumulated value given starting capital and a series of interest rates, as follows:
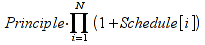
See also PV 6.12.41, NPER 6.12.29, PMT 6.12.36, RATE 6.12.42
Summary: Computes the interest rate of a fully vested security.
Syntax: INTRATE( Date Settlement ; Date Maturity ; Number Investment ; Number Redemption [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Settlement < Maturity
Semantics: Calculates the annual interest rate that results when an item is purchased at the investment price and sold at the redemption price. No interest is paid on the investment. The parameters are:
Settlement: the date of purchase of the security.Maturity: the date on which the security is sold.
Investment: the purchase price.
Redemption: the selling price.
Basis indicates the day-count convention to use in the calculation. 4.11.7
The return value for this function is:
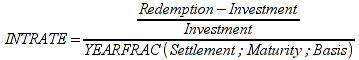
See also RECEIVED 6.12.43, YEARFRAC 6.10.24
Summary: Returns the amount of an annuity payment going towards interest.
Syntax: IPMT( Number Rate ; Number Period ; Number Nper ; Number PV [ ; Number FV = 0 [ ; Number Type = 0 ] ] )
Returns: Currency
Constraints: None.
Semantics: Computes the interest portion of an amortized payment for a constant interest rate and regular payments. The interest payment is the interest rate multiplied by the balance at the beginning of the period. The parameters are:
Rate: The periodic interest rate.
Period: The period for which the interest payment is computed.
Nper: The total number of periods for which the payments are made
PV: The present value (e.g. The initial loan amount).
FV: The future value (optional) at the end of the periods. Zero if omitted.
Type: the due date for the payments (optional). Zero if omitted. If type is 1, then payments are made at the beginning of each period. If type is 0, then payments are made at the end of each period.
See also PPMT 6.12.37, PMT 6.12.36
Summary: Compute the internal rate of return for a series of cash flows.
Syntax: IRR( NumberSequence Values [ ; Number Guess = 0.1 ] )
Returns: Percentage
Constraints: None.
Semantics: Compute the internal rate of return for a series of cash flows.
If provided, Guess is an estimate of the interest rate to start the iterative computation. If omitted, the value 0.1 (10%) is assumed.
The result of IRR is the rate at which the NPV() function will return zero with the given values.
There is no closed form for IRR. Evaluators may return an approximate solution using an iterative method, in which case the Guess parameter may be used to initialize the iteration. If the evaluator is unable to converge on a solution given a particular Guess, it may return an Error.
See also NPV 6.12.30, RATE 6.12.42
Summary: Compute the interest payment of an amortized loan for a given period.
Syntax: ISPMT( Number Rate ; Number Period ; Number Nper ; Number Pv )
Returns: Currency
Constraints: None.
Semantics: Computes the interest payment of an amortized loan for a given period. The parameters are:
●Rate: the interest rate per period.
●Period: the period for which the interest is computed
●Nper: the total number of payment periods.
●Pv: the amount of the investment
See also PV 6.12.41, FV 6.12.20, NPER 6.12.29, PMT 6.12.36, RATE 6.12.42
Summary: Returns the modified Macaulay duration of a fixed interest security in years
Syntax: MDURATION( Date Settlement ; Date Maturity ; Number Coupon ; Number Yield ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Yield >= 0, Coupon >= 0, Settlement <= Maturity; Frequency = 1, 2, 4
Semantics: Computes the modified Macaulay duration, given:
●Settlement the date of purchase of the security
●Maturity the date when the security matures
●Coupon the annual nominal rate of interest
●Yield the annual yield of the security
●Frequency number of interest payments per year
●Basis Basis indicates the day-count convention to use in the calculation. 4.11.7
The modified duration is computed as follows:
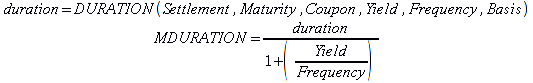
See also DURATION 6.12.18
Summary: Returns the modified internal rate of return (IRR) of a series of periodic investments
Syntax: MIRR( Array Values ; Number Investment ; Number ReinvestRate )
Returns: Percentage
Constraints: Values shall contain at least one positive value and at least one negative value.
Semantics: Values is a series of periodic income (positive values) and payments (negative values) at regular intervals (Text and Empty cells are ignored). Investment is the rate of interest of the payments (negative values); ReinvestRate is the rate of interest of the reinvestment (positive values).
Computes the modified internal rate of return, which is:
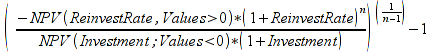
where N is the number of incomes and payments in Values (total).
See also IRR 6.12.24
Summary: Compute the annual nominal interest rate.
Syntax: NOMINAL( Number EffectiveRate ; Integer CompoundingPeriods )
Returns: Number
Constraints: EffectiveRate >0 , CompoundingPeriods > 0
Semantics: Returns the annual nominal interest rate based on the effective rate and the number of compounding periods in one year. The parameters are:
●EffectiveRate: effective rate
●CompoundingPeriods: the compounding periods per year
Suppose that P is the present value, m is the compounding periods per year, the future value after one year is
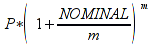
The mapping between nominal rate and effective rate is
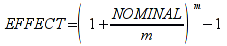
See also EFFECT 6.12.19
Summary: Compute the number of payment periods for an investment.
Syntax: NPER( Number Rate ; Number Payment ; Number Pv [ ; [ Number Fv ] [ ; Number PayType ] ] )
Returns: Number
Constraints: None.
Semantics: Computes the number of payment periods for an investment. The parameters are:
●Rate: the constant interest rate.
●Payment: the payment made in each period.
●Pv: the present value of the investment.
●Fv: the future value; default is 0.
●PayType: the type of payment, defaults to 0. It is 0 if payments are due at the end of the period; 1 if they are due at the beginning of the period.
If Rate is 0, then NPER solves this equation:
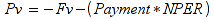
If Rate is non-zero, then NPER solves this equation:
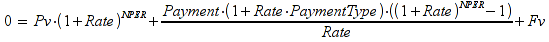
Evaluators claiming to support the “Medium” or “Large” set shall support negative rates; evaluators only claiming to support the “Small” set need not.
See also FV 6.12.20, RATE 6.12.42, PMT 6.12.36, PV 6.12.41
Summary: Compute the net present value (NPV) for a series of periodic cash flows.
Syntax: NPV( Number Rate ; { NumberSequenceList Value }+ )
Returns: Currency
Constraints: None.
Semantics: Computes the net present value for a series of periodic cash flows with the discount rate Rate. Values should be positive if they are received as income, and negative if the amounts are paid as outgo. Because the result is affected by the order of values, evaluators shall evaluate arguments in the order given and range reference and array arguments row-wise starting from top left.
If n is the number of values in the Values, the formula for NPV is:
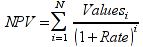
See also FV 6.12.20, IRR 6.12.24, NPER 6.12.29, PMT 6.12.36, PV 6.12.41, XNPV 6.12.52
Summary: Compute the value of a security per 100 currency units of face value. The security has an irregular first interest date.
Syntax: ODDFPRICE( DateParam Settlement ; DateParam Maturity ; DateParam Issue ; DateParam First ; Number Rate ; Number Yield ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, Yield, and Redemption should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Issue: the issue date of the security
●First: the first coupon date of the security
●Rate: the interest rate of the security
●Yield: the annual yield of the security
●Redemption: the redemption value per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly.
●Basis indicates the day-count convention to use in the calculation. 4.11.7
See also ODDLPRICE 6.12.33 , ODDFYIELD 6.12.32
Summary: Compute the yield of a security per 100 currency units of face value. The security has an irregular first interest date.
Syntax: ODDFYIELD( DateParam Settlement ; DateParam Maturity ; DateParam Issue ; DateParam First ; Number Rate ; Number Price ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, Price, and Redemption should be greater than 0. Maturity > First > Settlement > Issue.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Issue: the issue date of the security
●First: the first coupon date of the security
●Rate: the interest rate of the security
●Price: the price of the security
●Redemption: the redemption value per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly.
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also ODDLYIELD 6.12.34 , ODDFPRICE 6.12.31
Summary: Compute the value of a security per 100 currency units of face value. The security has an irregular last interest date.
Syntax: ODDLPRICE( DateParam Settlement ; DateParam Maturity ; DateParam Last ; Number Rate ; Number AnnualYield ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, AnnualYield, and Redemption should be greater than 0. The Maturity date should be greater than the Settlement date, and the Settlement should be greater than the last interest date.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Last: the last interest date of the security
●Rate: the interest rate of the security
●AnnualYield: the annual yield of the security
●Redemption: the redemption value per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also ODDFPRICE 6.12.31
Summary: Compute the yield of a security which has an irregular last interest date.
Syntax: ODDLYIELD( DateParam Settlement ; DateParam Maturity ; DateParam Last ; Number Rate ; Number Price ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, Price, and Redemption should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Last: the last interest date of the security
●Rate: the interest rate of the security
●Price: the price of the security
●Redemption: the redemption value per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly.
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also ODDLPRICE 6.12.33 , ODDFYIELD 6.12.32
Summary: Returns the number of periods required by an investment to realize a specified value.
Syntax: PDURATION( Number rate ; Number currentValue ; Number specifiedValue )
Returns: Number
Constraints: rate > 0; currentValue > 0; specifiedValue > 0
Semantics: Calculates the number of periods for attaining a certain value specifiedValue, starting from currentValue and using the interest rate rate.
●rate The interest rate per period.
●currentValue The current value of the investment.
●specifiedValue The value, that should be reached.
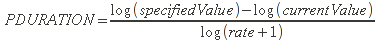
See also DURATION 6.12.18
Summary: Compute the payment made each period for an investment.
Syntax: PMT( Number Rate ; Integer Nper ; Number Pv [ ; [ Number Fv = 0 ] [ ; Number PayType = 0 ] ] )
Returns: Currency
Constraints: Nper > 0
Semantics: Computes the payment made each period for an investment. The parameters are:
●Rate: the interest rate per period.
●Nper: the total number of payment periods.
●Pv: the present value of the investment.
●Fv: the future value of the investment; default is 0.
●PayType: the type of payment, defaults to 0. It is 0 if payments are due at the end of the period; 1 if they are due at the beginning of the period. With PayType=1 the first payment is made on the same day the loan is taken out.
If Rate is 0, the following equation is solved:
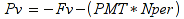
If Rate is nonzero, then PMT solves this equation:
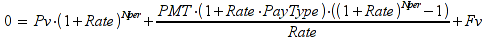
See also FV 6.12.20, NPER 6.12.29, PV 6.12.41, RATE 6.12.42
Summary: Calculate the payment for a given period on the principal for an investment at a given interest rate and constant payments.
Syntax: PPMT( Number Rate ; Integer Period ; Integer nPer ; Number Present [ ; Number Future = 0 [ ; Number Type = 0 ] ] )
Returns: Number
Constraints: Rate and Present should be greater than 0. 0<Period <nPer.
Semantics: The parameters are
●Rate: the interest rate
●Period: the given period that the payment returned is for
●nPer: the total number of periods
●Present: the present value
●Future: optional, the future value specified after nPer periods. The default value is 0.
●Type: optional, 0 or 1, respectively for payment at the end or at the beginning of a period. The default value is 0.
See also PMT 6.12.36
Summary: Calculates a quoted price for an interest paying security, per 100 currency units of face value.
Syntax: PRICE( DateParam Settlement ; DateParam Maturity ; Number Rate ; Number AnnualYield ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, AnnualYield, and Redemption should be greater than 0; Frequency = 1, 2 or 4.
Semantics: If A is the number of days from the Settlement date to next coupon date, B is the number of days of the coupon period that the Settlement is in, C is the number of coupons between Settlement date and Redemption date, D is the number of days from beginning of coupon period to Settlement date, then PRICE is calculated as
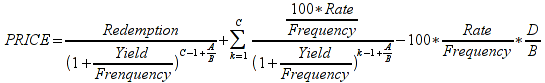
The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Rate: the interest rate of the security
●AnnualYield: a measure of the annual yield of a security (compounded at each interest payment)
●Redemption: the redemption value per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly.
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also PRICEDISC 6.12.39, PRICEMAT 6.12.40
Summary: Calculate the price of a security with a discount per 100 currency units of face value.
Syntax: PRICEDISC( DateParam Settlement ; DateParam Maturity ; Number Discount ; Number Redemption [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Discount and Redemption should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Discount: the discount rate of the security
●Redemption: the redemption value per 100 currency units face value
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also PRICE 6.12.38, PRICEMAT 6.12.40, YIELDDISC 6.12.54
Summary: Calculate the price per 100 currency units of face value of the security that pays interest on the maturity date.
Syntax: PRICEMAT( DateParam Settlement ; DateParam Maturity ; DateParam Issue ; Number Rate ; Number AnnualYield [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Settlement < Maturity, Rate >= 0, AnnualYield >= 0
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Issue: the issue date of the security
●Rate: the interest rate of the security
●AnnualYield: the annual yield of the security
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
If both, Rate and AnnualYield, are 0, the return value is 100.
See also PRICEDISC 6.12.39, PRICEMAT 6.12.40
Summary: Compute the present value (PV) of an investment.
Syntax: PV( Number Rate ; Number Nper ; Number Payment [ ; [ Number Fv = 0 ] [ ; Number PayType = 0 ] ] )
Returns: Currency
Constraints: None.
Semantics: Computes the present value of an investment. The parameters are:
●Rate: the interest rate per period.
●Nper: the total number of payment periods.
●Payment: the payment made in each period.
●Fv: the future value; default is 0.
●PayType: the type of payment, defaults to 0. It is 0 if payments are due at the end of the period; 1 if they are due at the beginning of the period.
If Rate is 0, then:
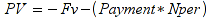
If Rate is nonzero, then PV solves this equation:
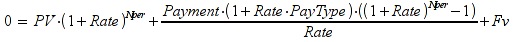
See also FV 6.12.20, NPER 6.12.29, PMT 6.12.36, RATE 6.12.42
Summary: Compute the interest rate per period of an investment.
Syntax: RATE( Number Nper ; Number Payment ; Number Pv [ ; [ Number Fv = 0 ] [ ; [ Number PayType = 0 ] [ ; Number Guess = 0.1 ] ] ] )
Returns: Percentage
Constraints: If Nper is 0 or less than 0, the result is an Error.
Semantics: Computes the interest rate of an investment. The parameters are:
●Nper: the total number of payment periods.
●Payment: the payment made in each period.
●Pv: the present value of the investment.
●Fv: the future value; default is 0.
●PayType: the type of payment, defaults to 0. It is 0 if payments are due at the end of the period; 1 if they are due at the beginning of the period.
●Guess: An estimate of the interest rate to start the iterative computation. If omitted, 0.1 (10%) is assumed.
RATE solves this equation:
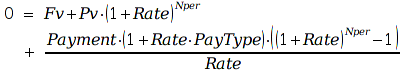
See also FV 6.12.20, NPER 6.12.29, PMT 6.12.36, PV 6.12.41
Summary: Calculates the amount received at maturity for a zero coupon bond.
Syntax: RECEIVED( DateParam Settlement ; DateParam Maturity ; Number Investment ; Number Discount [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Investment and Discount should be greater than 0.
Semantics:
The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Investment: the amount of investment in the security
●Discount: the discount rate of the security
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
The return value is:
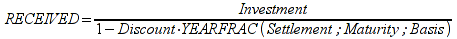
See also YEARFRAC 6.10.24
Summary: Returns an equivalent interest rate when an investment increases in value.
Syntax: RRI( Number N ; Number Pv ; Number Fv )
Returns: Percentage
Constraints: N > 0
Semantics: Returns the interest rate given N (the number of periods), Pv (present value), and Fv (future value), calculated as follows:
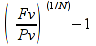
See also FV 6.12.20, NPER 6.12.29, PMT 6.12.36, PV 6.12.41, RATE 6.12.42
Summary: Compute the amount of depreciation at a given period of time using the straight-line depreciation method.
Syntax: DDB( Number Cost ; Number Salvage ; Number LifeTime )
Returns: Currency
Constraints: None.
Semantics: Compute the amount of depreciation of an asset at a given period of time using straight-line depreciation. The parameters are:
●Cost: the total amount paid for the asset.
●Salvage: the salvage value at the end of the LifeTime (often 0)
●LifeTime: the number of periods that the depreciation will occur over. A positive integer.
For alternative methods to compute depreciation, see DDB 6.12.14.
See also DDB 6.12.14
Summary: Compute the amount of depreciation at a given period of time using the Sum-of-the-Years'-Digits method.
Syntax: SYD( Number Cost ; Number Salvage ; Number LifeTime ; Number Period )
Returns: Currency
Constraints: None.
Semantics: Compute the amount of depreciation of an asset at a given period of time using the Sum-of-the-Years'-Digits method. The parameters are:
●Cost: the total amount paid for the asset.
●Salvage: the salvage value at the end of the LifeTime (often 0)
●LifeTime: the number of periods that the depreciation will occur over. A positive integer.
●Period: the period for which the depreciation value is specified.
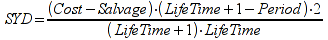
For other methods of computing depreciation, see DDB 6.12.14.
See also SLN 6.12.45, DDB 6.12.14
Summary: Compute the bond-equivalent yield for a treasury bill.
Syntax: TBILLEQ( DateParam Settlement ; DateParam Maturity ; Number Discount )
Returns: Number
Constraints: The maturity date should be less than one year beyond settlement date. Discount is any positive value.
Semantics: The parameters are defined as,
●Settlement: the settlement/purchase date of the treasury bill
●Maturity: the maturity/expire date of the treasury bill
●Discount: the discount rate of the treasury bill.
TBILLEQ is calculated as
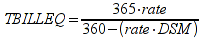
where DSM is the number of days between settlement and maturity computed according to the 360 days per year basis (basis 2, 4.11.7)
See also TBILLPRICE 6.12.48, TBILLYIELD 6.12.49
Summary: Compute the price per 100 face value for a treasury bill.
Syntax: TBILLPRICE( DateParam Settlement ; DateParam Maturity ; Number Discount )
Returns: Number
Constraints: The maturity date should be less than one year beyond settlement. Discount is any positive value.
Semantics: The parameters are:
●Settlement: the settlement/purchase date of the treasury bill
●Maturity: the maturity/expire date of the treasury bill
●Discount: the discount rate of the treasury bill.
See also TBILLEQ 6.12.47, TBILLYIELD 6.12.49
Summary: Compute the yield for a treasury bill.
Syntax: TBILLYIELD( DateParam Settlement ; DateParam Maturity ; Number Price )
Returns: Number
Constraints: The maturity date should be less than one year beyond settlement. Price is any positive value.
Semantics: The parameters are:
●Settlement: the settlement/purchase date of the treasury bill
●Maturity: the maturity/expire date of the treasury bill
●Price: the price of the treasury bill per 100 face value
See also TBILLEQ 6.12.47, TBILLPRICE 6.12.48
Summary: Calculates the depreciation allowance of an asset with an initial value, an expected useful life, and a final value of salvage for a period specified, using the variable-rate declining balance method..
Syntax: VDB( Number cost ; Number salvage ; Number lifeTime ; Number startPeriod ; Number endPeriod [ ; Number depreciationFactor = 2 [ ; Logical noSwitch = FALSE() ] ] )
Returns: Number
Constraints: salvage < cost, lifeTime > 0, 0 ≤ startPeriod ≤ lifeTime, startPeriod ≤ endPeriod ≤ lifeTime, depreciationFactor ≥ 0
Semantics: cost is the amount paid for the asset. cost can be any value greater than salvage.
salvage is the value of the asset at the end of its life. salvage can be any value.
lifeTime is the number of periods the asset takes to depreciate to its salvage value. lifeTime can be any value greater than 0.
startPeriod is the point in the asset's life when you want to begin calculating depreciation. start-Period can be any value greater than or equal to 0, but cannot be greater than lifeTime.
endPeriod is the point in the asset's life when you want to stop calculating depreciation. end-Period can be any value greater than startPeriod.
startPeriod and endPeriod correspond to the asset's life, relative to the fiscal period. For example, if you want to find the first year's depreciation of an asset purchased at the beginning of the second quarter of a fiscal year, start-period would be 0 and end-period would be 0.75 (1 minus 0.25 of a year).
VDB allows for the use of an initialPeriod option to calculate depreciation for the period the asset is placed in service. VDB uses the fractional part of startPeriod and endPeriod to determine the initialPeriod option. If both startPeriod and endPeriod have fractional parts, then VDB uses the fractional part of startPeriod.
depreciationFactor is an optional argument that specifies the percentage of straight-line depreciation you want to use as the depreciation rate. If you omit this argument, VDB uses 2, which is the double-declining balance rate. depreciation-factor can be any value greater than or equal to 0; commonly used rates are 1.25, 1.50, 1.75, and 2.
noSwitch is an optional argument that you include if you do not want VDB to switch to straight-line depreciation for the remaining useful life. Normally, declining-balance switches to such a straight-line calculation when it is greater than the declining-balance calculation.
If noSwitch is FALSE() or omitted, VDB automatically switches to straight-line depreciation when that is greater than declining-balance depreciation. If noSwitch is TRUE(), VDB never switches to straight-line depreciation.
See also DDB 6.12.14, SLN 6.12.45
Summary: Compute the internal rate of return for a non-periodic series of cash flows.
Syntax: XIRR( NumberSequence Values ; DateSequence Dates [ ; Number Guess = 0.1 ] )
Returns: Number
Constraints: The size of Values and Dates are equal. Values contains at least one positive and one negative cash flow.
Semantics: Compute the internal rate of return for a series of cash flows which is not necessarily periodic. The parameters are
●Values: a series of cash flows. The first cash-flow amount is a negative number that represents the investment. The later cash flows are discounted based on the annual discount rate and the timing of the flow. The series of cash flow should contain at least one positive and one negative value.
●Dates: a series of dates that corresponds to values. The first date indicates the start of the cash flows. The range of Values and Dates shall be the same size.
●Guess: If provided, Guess is an estimate of the interest rate to start the iterative computation. If omitted, the value 0.1 (10%) is assumed. The result of XIRR is the rate at which the XNPV() function will return zero with the given cash flows. There is no closed form for XIRR. Implementations may return an approximate solution using an iterative method, in which case the Guess parameter may be used to initialize the iteration. If the implementation is unable to converge on a solution given a particular Guess, it may return an error.
See also IRR 6.12.24
Summary: Compute the net present value of a series of cash flows.
Syntax: XNPV( Number Rate ; Reference|Array Values ; Reference| Array Dates )
Returns: Number
Constraints:
Number of elements in Values equals number of elements in Dates.
All elements of Values are of type Number.
All elements of Dates are of type Number.
All elements of Dates >= Dates[1]
Semantics: Compute the net present value for a series of cash flows which is not necessarily periodic. The parameters are
●Rate: discount rate. The value should be greater than -1.
●Values: a series of cash flows. The first cash-flow amount is a negative number that represents the investment. The later cash flows are discounted based on the annual discount rate and the timing of the flow. The series of cash flow should contain at least one positive and one negative value.
●Dates: a series of dates that corresponds to values. The first date indicates the start of the cash flows. If the dimensions of the Values and Dates arrays differ, evaluators shall match value and date pairs row-wise starting from top left.
With N being the number of elements in Values and Dates each, the formula is:
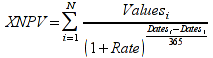
See also NPV 6.12.30
Summary: Calculate the yield of a bond.
Syntax: YIELD( DateParam Settlement ; DateParam Maturity ; Number Rate ; Number Price ; Number Redemption ; Number Frequency [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate, Price, and Redemption should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the bond
●Maturity: the maturity/expire date of the bond
●Rate: the interest rate of the bond
●Price: the price of the bond per 100 currency units face value
●Redemption: the redemption value of the bond per 100 currency units face value
●Frequency: the number of interest payments per year. 1=annual; 2=semiannual; 4=quarterly
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also PRICE 6.12.38, YIELDDISC 6.12.54, YIELDMAT 6.12.55
Summary: Calculate the yield of a discounted security per 100 currency units of face value.
Syntax: YIELDDISC( DateParam Settlement ; DateParam Maturity ; Number Price ; Number Redemption [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Price and Redemption should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Price: the price of the security per 100 currency units face value
●Redemption: the redemption value per 100 currency units face value
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
The return value is
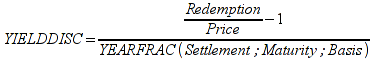
See also PRICEDISC 6.12.39, YEARFRAC 6.10.24
Summary: Calculate the yield of the security that pays interest on the maturity date.
Syntax: YIELDMAT( DateParam Settlement ; DateParam Maturity ; DateParam Issue ; Number Rate ; Number Price [ ; Basis Basis = 0 ] )
Returns: Number
Constraints: Rate and Price should be greater than 0.
Semantics: The parameters are
●Settlement: the settlement/purchase date of the security
●Maturity: the maturity/expire date of the security
●Issue: the issue date of the security
●Rate: the interest rate of the security
●Price: the price of the security per 100 currency units face value
●Basis: indicates the day-count convention to use in the calculation. 4.11.7
See also PRICE 6.12.38, YIELD 6.12.53, YIELDDISC 6.12.54
Information functions provide information about a data value, the spreadsheet, or underlying environment, including special functions for converting between data types.
Summary: Returns the number of areas in a given reference
Syntax: AREAS( ReferenceList R )
Returns: Number
Constraints: None
Semantics: Returns the number of areas in the reference list.
See also Infix Operator Reference Concatenation 6.4.13, INDEX 6.14.6
Summary: Returns information about position, formatting or contents in a reference.
Syntax: CELL( Text Info_Type [ ; Reference R ] )
Returns: Information about position, formatting properties or content
Constraints: None
Semantics: The parameters are
●Info_Type: the text string which specifies the type of information. Please refer to the following table.
|
Info_Type |
Comment |
|
COL |
Returns the column number of the cell. |
|
ROW |
Returns the row number of the cell. |
|
SHEET |
Returns the sheet number of the cell. |
|
ADDRESS |
Returns the absolute address of the cell. The sheet name is included if given in the reference. For an external reference a Source as specified in the syntax rules for References 5.8 is included. |
|
FILENAME |
Returns the file name of the file that contains the cell as an IRI. If the file is newly created and has not yet been saved, the file name is empty text “”. |
|
CONTENTS |
Returns the contents of the cell, without formatting properties. |
|
COLOR |
Returns 1 if color formatting is set for negative value in this cell; otherwise returns 0 |
|
FORMAT |
Returns a text string which shows the number format of the cell. ,(comma) = number with thousands separator F = number without thousands separator C = currency format S = exponential representation P = percentage To indicate the number of decimal places after the decimal separator, a number is given right after the above characters. D1 = MMM-D-YY, MM-D-YY and similar formats D2 = DD-MM D3 = MM-YY D4 = DD-MM-YYYY HH:MM:SS D5 = MM-DD D6 = HH:MM:SS AM/PM D7 = HH:MM AM/PM D8 = HH:MM:SS D9 = HH:MM G = All other formats - (Minus) at the end = negative numbers in the cell have color setting () (brackets) at the end = this cell has the format settings with parentheses for positive or all values |
|
TYPE |
Returns the text value corresponding to the type of content in the cell: “b” : blank or empty cell content “l” : label or text cell content “v” : number value cell content |
|
WIDTH |
Returns the column width of the cell. The unit is the width of one zero (0) character in default font size. |
|
PROTECT |
Returns the protection status of the cell: 1 = cell is protected 0 = cell is unprotected |
|
PARENTHESES |
Returns 1 if the cell has the format settings with parentheses for positive or all values, otherwise returns 0 |
|
PREFIX |
Returns single character text strings corresponding to the alignment of the cell. “'” (APOSTROPHE, U+0027) = left alignment '"' (QUOTATION MARK, U+0022) = right alignment ^(caret) = centered alignment \(back slash) = filled alignment otherwise, returns empty string "". |
●R : if R is a reference to a cell, it is the cell whose information will be returned; if R is a reference to a range, the top-left cell in the range is the selected one; if R is omitted, the current cell is used.
Summary: Returns the column number(s) of a reference
Syntax: COLUMN( [ Reference R ] )
Returns: Number
Constraints: AREAS(R) = 1
Semantics: Returns the column number of a reference, where “A” is 1, “B” is 2, and so on. If no parameter is given, the current cell is used. If a reference has multiple columns, an array of numbers is returned with all of the columns in the reference.
See also ROW 6.13.29, SHEET 6.13.31
Summary: Returns the number of columns in a given range
Syntax: COLUMNS( Reference|Array R )
Returns: Number
Constraints: None
Semantics: Returns the number of columns in the range or array specified. The result is not dependent on the cell content in the range.
See also ROWS 6.13.30
Summary: Count the number of Numbers provided
Syntax: COUNT( { NumberSequenceList N }+ )
Returns: Number
Constraints: One or more parameters.
Semantics: Counts the numbers in the list of NumberSequences provided. Only numbers in references are counted; all other types are ignored. Errors are not propagated. It is implementation-defined what happens if 0 parameters are passed, but it should be an Error or 0.
See also COUNTA 6.13.7
Summary: Count the number of non-empty values
Syntax: COUNTA( { Any A }+ )
Returns: Number
Constraints: None.
Semantics: Counts the number of non-blank values in the list of Any sequences provided. A value is non-blank if it contains any content of any type, including an Error. In a reference, every cell that is not empty is included in the count. An empty string value ("") is not considered blank. Errors contained in a range are considered a non-blank value for purposes of the count; errors do not propagate. Constant expressions or formulas are allowed; these are evaluated and if they produce an Error value the Error value is counted as one non-blank value (and not propagated as an Error). It is implementation-defined what happens if 0 parameters are passed, but it should be an Error or 0. Any A may be a ReferenceList.
See also COUNT 6.13.6, ISBLANK 6.13.14
Summary: Count the number of blank values
Syntax: COUNTBLANK( ReferenceList R )
Returns: Number
Constraints: None.
Semantics: Counts the number of blank cells in the Reference provided. A cell is blank if the cell is empty for purposes of COUNTBLANK. If ISBLANK(R) is true, then it is blank. A cell with numeric value zero ('0') is not blank. It is implementation-defined whether or not a cell returning the empty string ("") is considered blank; because of this, there is a (potential) subtle difference between COUNTBLANK and ISBLANK.
Evaluators shall support one Reference as a parameter and may support a ReferenceList as a parameter.
See also COUNT 6.13.6, COUNTA 6.13.7, COUNTIF 6.13.9, ISBLANK 6.13.14
Summary: Count the number of cells in a range that meet a criteria.
Syntax: COUNTIF( ReferenceList R ; Criterion C )
Returns: Number
Constraints: Does not accept constant values as the reference parameter.
Semantics: Counts the number of cells in the reference range R that meet the Criterion C (4.11.8).
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also COUNT 6.13.6, COUNTA 6.13.7, COUNTBLANK 6.13.8, COUNTIFS 6.13.10, SUMIF 6.16.62, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: Count the number of cells that meet multiple criteria in multiple ranges.
Syntax: COUNTIFS( Reference R1 ; Criterion C1 [ ; Reference R2 ; Criterion C2 ]... )
Returns: Number
Constraints: Does not accept constant values as the reference parameter.
Semantics: Counts the number of cells that meet the Criterion C1 in the reference range R1 and the Criterion C2 in the reference range R2, and so on (4.11.8). All reference ranges shall have the same dimension and size, else an Error is returned. A logical AND is applied between each array result of each selection; an entry is counted only if the same position in each array is the result of a Criterion match.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also AVERAGEIFS 6.18.6, COUNT 6.13.6, COUNTA 6.13.7, COUNTBLANK 6.13.8, COUNTIF 6.13.9, SUMIF 6.16.62, SUMIFS 6.16.63, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: Returns Number representing the specific Error type.
Syntax: ERROR.TYPE( Error E )
Returns: Number
Constraints: None.
Semantics: Returns a number representing what kind of Error has occurred. Note that unlike most functions, this function does not propagate Error values. Receiving a non-Error value returns an Error. In particular, ERROR.TYPE(NA()) returns 7, and ERROR.TYPE applied to a non-Error returns an Error.
See also NA 6.13.27
Summary: Returns formula at given reference as text
Syntax: FORMULA( Reference X )
Returns: String
Constraints: Reference X shall contain a formula
Semantics: Returns the formula in reference X as a string. The specific syntax of this returned string is implementation-defined. This function is intended to aid debugging by simplifying display of formulas in other cells. Error results of the referred formula cell are not propagated.
See also ISFORMULA 6.13.18
Summary: Returns information about the environment
Syntax: INFO( Text Category )
Returns: Any (see below)
Constraints: Category shall be valid
Semantics: Returns information about the environment in the given category.
Evaluators shall support at least the following categories:
|
Category |
Meaning |
Type |
|
"directory" |
Current directory. This shall be formatted so file names can be appended to the result (e.g., on POSIX and Windows systems it shall end with the separator “/” or “\” respectively). |
Text |
|
"memavail" |
Amount of memory “available”, in bytes. On many modern (virtual memory) systems this value is not really available, but a system should return 0 if it is known that there is no more memory available, and greater than 0 otherwise |
Number |
|
"memused" |
Amount of memory used, in bytes, by the data |
Number |
|
"numfile" |
Number of active worksheets in files |
Number |
|
"osversion" |
Operating system version |
Text |
|
"origin" |
The top leftmost visible cell's absolute reference prefixed with “$A:”. In locales where cells are ordered right-to-left, the top rightmost visible cell is used instead. |
Text |
|
"recalc" |
Current recalculation mode. If the locale is English, this is either "Automatic" or "Manual" (the exact text depends on the locale) |
Text |
|
"release" |
The version of the implementation. |
Text |
|
"system" |
The type of the operating system. |
Text |
|
"totmem" |
Total memory available in bytes, including the memory already used. |
Number |
Evaluators may support other categories.
See also CELL 6.13.3
Summary: Return TRUE if the referenced cell is blank, else return FALSE
Syntax: ISBLANK( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Number, Text, or Logical, return FALSE. If X is a reference to a cell, examine the cell; if it is blank (has no value), return TRUE, but if it has a value, return FALSE. A cell with the empty string is not considered blank.
See also ISNUMBER 6.13.22, ISTEXT 6.13.25
Summary: Return True if the parameter has type Error and is not NA, else return False.
Syntax: ISERR( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Error, and ISNA(X) is not true, returns TRUE. Otherwise it returns FALSE. Note that this function returns False if given NA(); if this is not desired, use ISERROR 6.13.16. Note that this function does not propagate Error values.
ISERR(X) is the same as:
IF(ISNA(X),FALSE(),ISERROR(X))
See also ERROR.TYPE 6.13.11, ISERROR 6.13.16, ISNUMBER 6.13.22, ISTEXT 6.13.25, NA 6.13.27
Summary: Return TRUE if the parameter has type Error, else return FALSE
Syntax: ISERROR( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Error, returns TRUE, else returns FALSE. Note that this function returns True if given NA(); if this is not desired, use ISERR 6.13.15. Note that this function does not propagate Error values.
See also ERROR.TYPE 6.13.11, ISERR 6.13.15, ISNA 6.13.20, ISNUMBER 6.13.22, ISTEXT 6.13.25, NA 6.13.27
Summary: Return TRUE if the value is even, else return FALSE
Syntax: ISEVEN( Number X )
Returns: Logical
Constraints: None
Semantics: First, compute X1=TRUNC(X). Then, if X1 is even (a division by 2 has a remainder of 0), return True, else return False. The result is implementation-defined if given a Logical value; an evaluator may return either an Error or the result of converting the Logical value to a Number (per Conversion to Number 6.3.5 ).
See also ISODD 6.13.23
Summary: Return TRUE if the reference refers to a formula, else return FALSE
Syntax: ISFORMULA( Reference X )
Returns: Logical
Constraints: None
Semantics: If X refers to a cell whose value is computed by a formula, return TRUE(), else return FALSE(). A formula itself may compute a constant; in that case it will still return TRUE() since it is still a formula. Passing a non-reference, or a reference to more than one cell, is implementation-defined.
See also ISTEXT 6.13.25, ISNUMBER 6.13.22
Summary: Return TRUE if the parameter has type Logical, else return FALSE
Syntax: ISLOGICAL( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Logical, returns TRUE, else FALSE. Evaluators that do not have a distinct Logical type will return the same value ISNUMBER(X) would return.
See also ISTEXT 6.13.25, ISNUMBER 6.13.22
Summary: Return True if the parameter is of type NA, else return False.
Syntax: ISERR( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is NA, return True, else return False. Note that if X is a reference, the value being referenced is considered. This function does not propagate Error values.
See also ERROR.TYPE 6.13.11, ISERROR 6.13.16, ISERR 6.13.15, ISNUMBER 6.13.22, ISTEXT 6.13.25, NA 6.13.27
Summary: Return TRUE if the parameter does not have type Text, else return FALSE
Syntax: ISNONTEXT( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Text, ISNONTEXT returns FALSE, else TRUE. If X is a reference, it examines what X references. References to empty cells are not considered text, so for reference to an empty cell ISNONTEXT will return TRUE. Empty Cell 4.7
ISNONTEXT(X) is equivalent to NOT(ISTEXT(X))
See also ISNUMBER 6.13.22, ISLOGICAL 6.13.19, ISTEXT 6.13.25
Summary: Return TRUE if the parameter has type Number, else return FALSE
Syntax: ISNUMBER( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Number, returns TRUE, else FALSE. Evaluators may not have a distinguished Logical type; in such evaluators, ISNUMBER(TRUE()) is TRUE.
See also ISTEXT 6.13.25, ISLOGICAL 6.13.19
Summary: Return TRUE if the value is even, else return FALSE
Syntax: ISODD( Number X )
Returns: Logical
Constraints: None
Semantics: First, compute X1=TRUNC(X). Then, if X1 is odd (a division by 2 has a remainder of 1), return True, else return False. The result is implementation-defined if given a Logical value; an evaluator may return either an Error or the result of converting the Logical value to a Number (per Conversion to Number 6.3.5 ).
See also ISEVEN 6.13.17
Summary: Return True if the parameter is of type reference, else return False.
Syntax: ISREF( Any X )
Returns: Logical
Constraints: None
Semantics: If X is of type Reference or ReferenceList, return True, else return False. Note that unlike nearly all other functions, when given a reference this function does not then examine the value being referenced. Some functions and operators return references, and thus ISREF will return True when given their results. X may be a ReferenceList, in which case ISREF returns True.
See also ISNUMBER 6.13.22, ISTEXT 6.13.25
Summary: Return TRUE if the parameter has type Text, else return FALSE.
ISTEXT(X) is equivalent to NOT(ISNONTEXT(X)).
Syntax: ISTEXT( Scalar X )
Returns: Logical
Constraints: None
Semantics: If X is of type Text, returns TRUE, else FALSE. References to empty cells are NOT considered Text. If X is a reference, examines what X references. References to empty cells are NOT considered Text, so a reference to a empty cell will return FALSE. Empty Cell 4.7
See also ISNONTEXT 6.13.21, ISNUMBER 6.13.22, ISLOGICAL 6.13.19
Summary: Return the number of a value.
Syntax: N( Any X )
Returns: Number
Constraints: None
Semantics: If X is a Reference, it is first dereferenced to a scalar. Then its type is examined. If it is of type Number, it is returned. If it is of type Logical, 1 is returned if TRUE else 0 is returned. It is implementation-defined what happens if it is provided a Text value.
See also T 6.20.22, VALUE 6.13.34
Summary: Return the constant Error value #N/A.
Syntax: NA()
Returns: Error
Constraints: Shall have 0 parameters
Semantics: This function takes no arguments and returns the Error NA
See also ERROR.TYPE 6.13.11, ISERROR 6.13.16
Summary: Convert text to number, in a locale-independent way
Syntax: NUMBERVALUE( Text X [ ; Text DecimalSeparator [ ; Text GroupSeparator ] ] )
Returns: Number
Constraints: LEN(DecimalSeparator) = 1, DecimalSeparator shall not appear in GroupSeparator
Semantics: Converts given Text value X into Number. If X is a Reference, it is first dereferenced.
X is transformed according to the following rules:
1)Starting from the beginning, remove all occurrences of the group separator before any decimal separator
2)Starting from the beginning, replace the first occurrence in the text of the decimal separator character with the FULL STOP (U+002E) character
3)Remove all whitespace characters (5.14).
4)If the first character of the resulting string is a period FULL STOP (U+002E) then prepend a zero
5)If the string ends in one or more instances of PERCENT SIGN (U+0025) , remove the percent sign(s)
If the resulting string is a valid xsd:float, then return the number corresponding to that string, according to the definition provided in XML Schema, Part 2, Section 3.2.4. If percent signs were removed in step 5, divide the value of the returned number by 100 for each percent sign removed.
If the string is not a valid xsd:float then return an error.
See also N 6.13.26, T 6.20.22, DATEVALUE 6.10.4, TIMEVALUE 6.10.18, VALUE 6.13.34
Summary: Returns the row number(s) of a reference
Syntax: ROW( [ Reference R ] )
Returns: Number
Constraints: AREAS(R) = 1
Semantics: Returns the row number of a reference. If no parameter is given, the current cell is used. If a reference has multiple rows, an array of numbers is returned with all of the rows in the reference.
See also COLUMN 6.13.4, SHEET 6.13.31
Summary: Returns the number of rows in a given range
Syntax: ROWS( Reference|Array R )
Returns: Number
Constraints: None
Semantics: Returns the number of rows in the range or array specified. The result is not dependent on the cell content in the range.
See also COLUMNS 6.13.5
Summary: Returns the sheet number of the reference or the string representing a sheet name.
Syntax: SHEET( [ Text|Reference R ] )
Returns: Number >= 1
Constraints: R shall not contain a Source Location (5.8 References)
Semantics: Returns the 1 based sheet number of the given reference or sheet name.
Hidden sheets are not excluded from the sheet count.
If no parameter is given, the result is the sheet number of the sheet containing the formula.
If a Reference is given it is not dereferenced.
If the reference encompasses more than one sheet, the result is the number of the first sheet in the range.
If a reference does not contain a sheet reference, the result is the sheet number of the sheet containing the formula.
If the function is not evaluated within a table cell, an error is returned.
See also COLUMN 6.13.4, ROW 6.13.29, SHEETS 6.13.32
Summary: Returns the number of sheets in a reference or current document
Syntax: SHEETS( [ Reference R ] )
Returns: Number >= 1
Constraints: R shall not contain a Source Location (5.8 References)
Semantics: Returns the number of sheets in the given reference.
If no parameter is given, the number of sheets in the document is returned.
Hidden sheets are not excluded from the sheet count.
See also COLUMNS 6.13.5, ROWS 6.13.30, SHEET 6.13.31
Summary: Returns a number indicating the type of the provided value.
Syntax: TYPE( Any value )
Returns: Number
Constraints: None
Semantics: Returns a number indicating the type of the value given:
|
Value's Type |
TYPE Return |
|
Number |
1 |
|
Text |
2 |
|
Logical |
4 |
|
Error |
16 |
|
Array |
64 |
If a Reference is provided, the reference is first dereferenced, and any formulas are evaluated.
Note: Reliance on the return of 4 for TYPE() will impair the interoperability of a document containing an expression that relies on that value.
See also ERROR.TYPE 6.13.11
Summary: Convert text to number
Syntax: VALUE( Text X )
Returns: Number
Constraints: None
Semantics: Converts given text value X into Number. If X is a Reference, it is first dereferenced. VALUE is only specified if it is given a Text value or a Reference to a single cell containing a Text value; it is implementation-defined what happens if VALUE is given neither a Text value nor a Reference to a Text value. If the Text has a date, time, or datetime format, it is converted into a serial Number. In many cases the conversion of a date or datetime format is locale-dependent.
If the supplied text X cannot be converted into a Number, an Error is returned.
Regardless of the current locale, an evaluator shall accept numbers matching this regular expression (which does not include a decimal point character) and convert it into a Number. If the value ends in %, it shall divide the number by 100:
[+-]? [0-9]+([eE][+-]?[0-9]+)?)%?
VALUE shall accept text representations of numbers in the current locale. In the en_US locale, an evaluator shall accept decimal numbers matching this regular expression and convert it into a Number (the leading “$” is ignored; commas are ignored if they match the rule of a thousands separator; if the value ends in %, it shall divide the number by 100):
[+-]?\$?([0-9]+(,[0-9]{3})*)?(\.[0-9]+)?(([eE][+-]?[0-9]+)|%)?
Evaluators shall accept accept fractional values matching the regular expression:
[+-]? [0-9]+ \ [0-9]+/[1-9][0-9]?
A leading minus sign is considered identifying a negative number for the entire value. There is a space between the integer and the fractional portion; values between 0 and 1 can be represented by using 0 for the integer part.
Evaluators shall support time values in at least the HH:MM and HH:MM:SS formats, where HH is a 1-2 digit value from 0 to 23, MM is a 1-2 digit value from 0 to 59, and SS is a 1-2 digit value from 0 to 59. The hour may be one or two digits when it is less than 10. VALUE converts time values into Numbers ranging from 0 to 1, which is percentage of day that has elapsed by that time. Thus, VALUE("2:00") is the same as 2/24. Evaluators should accept times with fractional seconds as well when expressed in the form HH:MM:SS.ssss...
Evaluators shall accept textual dates in [ISO8601] format (YYYY-MM-DD), converting them into serial numbers based on the current epoch. Evaluators shall, when running in the en_US locale, accept the format MM/DD/YYYY .
In addition, in locale en_US, evaluators shall support the following formats (where YYYY is a 4-digit year, YY a 2-digit year, MM a numerical month, DD a numerical day, mmm a 3-character abbreviated alphabetical name, and mmmmm a full name):
|
Format |
Example |
Comment |
|
MM/DD/YYYY |
5/21/2006 |
LOCALE-DEPENDENT; Long year format with slashes. |
|
MM/DD/YY |
5/21/06 |
LOCALE-DEPENDENT; Short year format with slashes |
|
MM-DD-YYYY |
5-21-2006 |
LOCALE-DEPENDENT; Long year format with dashes (short year may be supported, but it may also be used for years less than 100 . |
|
mmm DD, YYYY |
Oct 29, 2006 |
LOCALE-DEPENDENT; Short alphabetic month day, year. Note: mmm depends on the locale's language. |
|
DD mmm YYYY |
29 Oct 2006 |
LOCALE-DEPENDENT; Short alphabetic day month year |
|
mmmmm DD, YYYY |
October 29, 2006 |
LOCALE-DEPENDENT; Long alphabetic month day, year |
|
DD mmmmm YYYY |
29 October 2006 |
LOCALE-DEPENDENT; Long alphabetic day month year |
Evaluators should support other locales. Many conversions will vary by locale, including the decimal point (comma or period), names of months, date formats (MM/DD vs. DD/MM), and so on. Dates in particular vary by locale.
Evaluators shall support the datetime format, which is a date followed by a time, using either the space character or the literal “T” character as the separator (the “T” is from ISO 8601). Evaluators shall support at least the ISO date format in a datetime format; they may support other date formats in a datetime format as well. Formats such as “YYYY-MM-DD HH:MM” and “YYYY-MM-DDTHH:MM:SS” (where “T” is the literal character T) shall be accepted. The result of accepting a datetime format shall be a representation of that specific time (without removing either the date or the time of day, unlike DATEVALUE or TIMEVALUE).
Evaluators may accept other formats that will convert to numbers, and those conversions may be locale-dependent, as long as they do not conflict with the above. Where no conversion is determined, an Error is returned.
See also N 6.13.26, T 6.20.22, DATEVALUE 6.10.4, TIMEVALUE 6.10.18, NUMBERVALUE 6.13.28
These functions look up information. Note that IF() can be considered a trivial lookup function, but it is listed as a logical function instead.
Summary: Returns a cell address (reference) as text
Syntax: ADDRESS( Integer Row ; Integer Column [ ; Integer Abs = 1 [ ; Logical A1 = TRUE() [ ; Text Sheet ] ] ] )
Returns: Text
Constraints: Row >= 1, Column >= 1, 1 <= Abs <= 4; A1 = TRUE(). Evaluators may evaluate expressions that do not meet the constraint A1 = TRUE().
Semantics: Returns a cell address (reference) as text. The text does not include the surrounding [...] of a reference. If a Sheet name is given, the sheet name in the text returned is followed by a “.” and the column/row reference if A1 is TRUE, or a “!” and the column/row reference if A1 is FALSE; otherwise no “.” respectively “!” is included. Columns are identified using uppercase letters. The value of Abs determines if the column and/or row is absolute or relative. The value of A1 determines if A1 reference style or R1C1 reference style is used.
|
Abs |
Meaning |
A1 = TRUE() |
A1 = FALSE() |
|
1 |
fully absolute |
$A$1 |
R1C1 |
|
2 |
row absolute, column relative |
A$1 |
R1C[1] |
|
3 |
row relative, column absolute |
$A1 |
R[1]C1 |
|
4 |
fully relative |
A1 |
R[1]C[1] |
Note that the INDIRECT function accepts this format.
See also INDIRECT 6.14.7
Summary: Uses an index to return a value from a list of values.
Syntax: CHOOSE( Integer Index ; { Any Value }+ )
Returns: Any
Constraints: Returns an Error if Index < 1 or if there is no corresponding value in the list of Values.
Semantics: Uses Index to determine which value, from a list of values, to return. If Index is 1, CHOOSE returns the first Value; if Index is 2, CHOOSE returns the second value, and so on. Note that the Values may be formula expressions. Expression paths of parameters other than the one chosen are not calculated or evaluated for side effects.
See also IF 6.15.4
Summary: Return a value from a data pilot table.
Syntax: GETPIVOTDATA( Text DataField ; Reference Table { ; Text Field ; Scalar Member }* )
Note: This function knows two different syntaxes. This version of the syntax is distinguished by the second parameter Table being a Reference.
Returns: Any
Semantics: Returns a single result from the calculation of a data pilot table.
The data pilot table is selected by Table, which is a reference to a cell or cell range that's within a data pilot table or contains a data pilot table. If the cell range contains several data pilot tables, the last one in the order of <table:data-pilot-table> elements in the file is used.
DataField selects one of the data pilot table's data fields. It can be the name of the source column, or the given name of the data field (such as “Sum of Sales”).
If no Field/Member pairs are given, the grand total is returned. Otherwise, each pair adds a constraint that the result shall satisfy. Field is the name of a field from the data pilot table. Member is the name of a member (item) from that field. If a member is a number, Member can alternatively be its numerical value.
If the data pilot table contains only a single result value that fulfills all of the constraints, or a subtotal result that summarizes all matching values, that result is returned. If there is no matching result, or several ones without a subtotal for them, an Error is returned. These conditions apply to results that are included in the data pilot table. If the source data contains entries that are hidden by settings of the data pilot table, they are ignored. The order of the Field/Member pairs is not significant. Field and member names are case-insensitive.
If no constraint for a page field is given, the field's selected value is implicitly used. If a constraint for a page field is given, it shall match the field's selected value, or an Error is returned.
Subtotal values from the data pilot table are only used if they use the function “auto” (except when specified in the constraint, see below).
Alternative syntax: GETPIVOTDATA( Reference Table ; Text Constraints )
For compatibility, a second syntax is allowed. Table has the same meaning as above. This version of the syntax is distinguished by the first parameter Table being a Reference.
Constraints is a space-separated list. Entries can be quoted (single quotes). One of the entries can be the data field name. The data field name can be left out if the data pilot table contains only one data field, otherwise it shall be present. Each of the other entries specifies a constraint in the form Field[Member] (with literal characters [ and ]), or only Member if the member name is unique within all fields that are used in the data pilot table. A function name can be added in the form Field[Member;Function], which will cause the constraint to match only subtotal values which use that function. The possible function names are the same as in the table:function attribute of the <table:data-pilot-subtotal> element, case-insensitive.
Summary: Look for a matching value in the first row of the given table, and return the value of the indicated row.
Syntax: HLOOKUP( Any Lookup ; Reference|Array DataSource ; Integer Row [ ; Logical RangeLookup = TRUE() ] )
Returns: Any
Constraints: Row >= 1; Searched portion of DataSource shall not include Logical values. Evaluators may evaluate expressions that do not meet the constraint that the searched portion of a DataSource not include Logical values.
Semantics:
If RangeLookup is omitted or TRUE or not 0, the first row of DataSource is assumed to be sorted in ascending order, with smaller numbers before larger ones, smaller text values before larger ones (e.g., "A" before "B", and "B" before "BA"), and False before True. If the types are mixed, Numbers are sorted before Text, and Text before Logicals; evaluators without a separate Logical type may include a Logical as a Number. The lookup will try to match an entry of value Lookup. If none is found the largest entry less than Lookup is taken as a match. From a sequence of identical values <= Lookup the last entry is taken. If there is no data less than or equal to Lookup, the #N/A Error is returned. If Lookup is of type Text and the value found is of type Number, the #N/A Error is returned. If DataSource is not sorted, the result is undetermined and implementation-dependent. In most cases it will be arbitrary and just plain wrong due to binary search algorithms.
If RangeLookup is FALSE or 0, DataSource does not need to be sorted and an exact match is searched. Each value in the first row of DataSource is examined in order (starting at the left) until its value matches Lookup.
Both methods, if there is a match, return the corresponding value in row Row, relative to the DataSource, where the topmost row in DataSource is 1.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also INDEX 6.14.6, MATCH 6.14.9, OFFSET 6.14.11, VLOOKUP 6.14.12
Summary: Returns a value using a row and column index value (and optionally an area index).
Syntax: INDEX( ReferenceList|Array DataSource ; [ Integer Row ] [ ; [ Integer Column ] ] [ ; Integer AreaNumber = 1 ] )
Returns: Any
Constraints: Row >= 0, Column >= 0,
1 <= AreaNumber <= number of references in DataSource if that is a ReferenceList, else AreaNumber = 1
Semantics:
Given a DataSource, returns the value at the given Row and Column (starting numbering at 1, relative to the top left of the DataSource) of the given area AreaNumber. If AreaNumber is not given, it defaults to 1 (the first and possibly only area). This function is essentially a two-dimensional version of CHOOSE, which does not accept range parameters.
If Row is omitted or an empty parameter (two consecutive ;; semicolons) or 0, an entire column of the given area AreaNumber in DataSource is returned. If Column is omitted or an empty parameter (two consecutive ;; semicolons) or 0, an entire row of the given area AreaNumber in DataSource is returned. If both, Row and Column, are omitted or empty or 0, the entire given area AreaNumber is returned.
If DataSource is a one-dimensional column vector, Column is optional or can be omitted as an empty parameter (two consecutive ;; semicolons). If DataSource is a one-dimensional row vector, Row is optional, which effectively makes Row act as the column offset into the vector, or can be omitted as an empty parameter (two consecutive ;; semicolons).
If Row or Column have a value greater than the dimension of the corresponding given area AreaNumber, an Error is returned.
See also AREAS 6.13.2, CHOOSE 6.14.3
Summary: Return a reference given a string representation of a reference
Syntax: INDIRECT( Text Ref [ ; Logical A1 = TRUE() ] )
Returns: Reference
Constraints: Ref is valid reference
Semantics: Given text for a reference (such as “A3”), returns a reference. If A1 is False, it is interpreted as an R1C1 reference style. For interoperability, if the Ref text includes a sheet name, evaluators should be able to parse both, the “.” dot and the “!” exclamation mark, as the sheet name separator. If evaluators support the A1=FALSE() case of the ADDRESS 6.14.2 function and include the “!” exclamation mark as the sheet name separator, evaluators shall correctly parse that in the A1=FALSE() case of this INDIRECT function. Evaluators shall correctly parse the “.” dot as the sheet name separator in the A1=TRUE() case.
See also ADDRESS 6.14.2
Summary: Look for criterion in an already-sorted array, and return a corresponding result
Syntax: LOOKUP( Any Find ; ForceArray Reference|Array Searched [ ; ForceArray Reference|Array Results ] )
Returns: Any
Constraints: The searched portion of Searched shall be sorted in ascending order; if provided, Results shall have the same length as Searched. The searched portion of Searched shall not include Logical values. Evaluators may evaluate expressions that do not meet the constraint that the searched portion of a Searched not include Logical values.
Semantics: This function searches for Find in a row or column of the previously-sorted array Searched and returns a corresponding value. The match is the largest value in the row/column of Searched that is less than or equal to Find (so an exact match is always preferred over inexact ones). From a sequence of identical values <= Find the last entry is taken. If Find is smaller than the smallest value in the first row or column (depending on the array dimensions), LOOKUP returns the #N/A Error. If Find is of type Text and the value found is of type Number, the #N/A Error is returned.
The searched portion of Searched shall be sorted in ascending order, and so that values of type Number precede values of type Text if both types are included (e.g., -2, 0, 2, “A”, “B”).
There are two major uses for this function; the 3-parameter version (vector) and the 2-parameter version (non-vector array).
Note: Interoperability is improved by use of HLOOKUP or VLOOKUP in expressions over LOOKUP.
When given two parameters, Searched is first examined:
●If Searched is square or is taller than it is wide (more rows than columns), LOOKUP searches in the first column (similar to VLOOKUP), and returns the corresponding value in the last column.
●If Searched covers an area that is wider than it is tall (more columns than rows), LOOKUP searches in the first row (similar to HLOOKUP), and returns the corresponding value in the last row.
When given 3 parameters, Results shall be a vector (either a row or a column) or an Error is raised. The function determines the index of the match in the first column respectively row of Searched, and returns the value in Results with the same index.
Searched is first examined:
●If Searched is square or is taller than it is wide (more rows than columns), LOOKUP searches in the first column (similar to VLOOKUP).
●If Searched covers an area that is wider than it is tall (more columns than rows), LOOKUP searches in the first row (similar to HLOOKUP).
The lengths of the search vector and the result vector do not need to be identical. When the match position falls outside the length of the result vector, an Error is returned if the result vector is given as an array object. If it is a cell range, it gets automatically extended to the length of the searched vector, but in the direction of the result vector. If just a single cell reference was passed, a column vector is generated. If the cell range cannot be extended due to the sheet's size limit, then the #N/A Error is returned.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also HLOOKUP 6.14.5, INDEX 6.14.6, MATCH 6.14.9, OFFSET 6.14.11, VLOOKUP 6.14.12
Summary: Finds a Search item in a sequence, and returns its position (starting from 1).
Syntax: MATCH( Scalar Search ; Reference|Array SearchRegion [ ; Integer MatchType = 1 ] )
Returns: Any
Constraints: -1 <= MatchType <= 1; The searched portion of SearchRegion shall not include Logical values. Evaluators may evaluate expressions that do not meet the constraint that the searched portion of a SearchRegion not include Logical values.
SearchRegion shall be a vector (a single row or column)
Semantics:
●MatchType = -1 finds the smallest value that is greater than or equal to Search in a SearchRegion where values are sorted in descending order. From a sequence of identical values >= Search the last value is taken. If no value >= Search exists, the #N/A Error is returned. If Search is of type Number and the value found is of type Text, the #N/A Error is returned.
●MatchType = 0 finds the first value that is equal to Search. Values in SearchRegion do not need to be sorted. If no value equal to Search exists, the #N/A Error is returned.
●MatchType = 1 or omitted finds the largest value that is less than or equal to Search in a SearchRegion where values are sorted in ascending order. From a sequence of identical values <= Search the last value is taken. If no value <= Search exists, the #N/A Error is returned. If Search is of type Text and the value found is of type Number, the #N/A Error is returned.
If a match is found, MATCH returns the relative position (starting from 1). For Text the comparison is case-insensitive. MatchType determines the type of search; if MatchType is 0, the SearchRegion shall be considered unsorted, and the first match is returned. If MatchType is 1, the SearchRegion may be assumed to be sorted in ascending order, with smaller Numbers before larger ones, smaller Text values before larger ones (e.g., "A" before "B", and "B" before "BA"), and False before True. If the types are mixed, Numbers are sorted before Text, and Text before Logicals; evaluators without a separate Logical type may include a Logical as a Number. If MatchType is -1, then SearchRegion may be assumed to be sorted in descending order (the opposite of the above). If MatchType is 1 or -1, evaluators may use binary search or other techniques so that they do not need to examine every value in linear order. MatchType defaults to 1.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also HLOOKUP 6.14.5, OFFSET 6.14.11, VLOOKUP 6.14.12
Summary: Executes a formula expression while substituting a row reference and a column reference.
Syntax: MULTIPLE.OPERATIONS( Reference FormulaCell ; Reference RowCell ; Reference RowReplacement [ ; Reference ColumnCell ; Reference ColumnReplacement ] )
Returns: Any
Semantics:
•.FormulaCell reference to the cell that contains the formula expression to calculate.
•.RowCell reference that is to be replaced by RowReplacement.
•.RowReplacement reference that replaces RowCell.
•.ColumnCell reference that is to be replaced by ColumnReplacement.
•.ColumnReplacement reference that replaces ColumnCell.
MULTIPLE.OPERATIONS executes the formula expression pointed to by FormulaCell and all formula expressions it depends on while replacing all references to RowCell with references to RowReplacement respectively all references to ColumnCell with references to ColumnReplacement.
If calls to MULTIPLE.OPERATIONS are encountered in dependencies, replacements of target cells shall occur in queued order, with each replacement using the result of the previous replacement.
Note: The function may be used to create tables of expressions that depend on two input parameters.
Example: FormulaCell is B5, RowCell is B3, ColumnCell is B2
Table 22 - MULTIPLE.OPERATIONS
|
|
col_B |
col_C |
col_D |
col_E |
col_F |
|
row_2 |
1 |
|
1 |
2 |
3 |
|
row_3 |
1 |
1 |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C3;$B$2;D$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C3;$B$2;E$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C3;$B$2;F$2) |
|
row_4 |
=B2+B3 |
2 |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C4;$B$2;D$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C4;$B$2;E$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C4;$B$2;F$2) |
|
row_5 |
=B2*B3+B4 |
3 |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C5;$B$2;D$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C5;$B$2;E$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C5;$B$2;F$2) |
|
|
|
4 |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C6;$B$2;D$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C6;$B$2;E$2) |
=MULTIPLE.OPERATIONS($B$5;$B$3;$C6;$B$2;F$2) |
Result:
Table 23 - MULTIPLE.OPERATIONS
|
|
col_B |
col_C |
col_D |
col_E |
col_F |
|
row_2 |
1 |
|
1 |
2 |
3 |
|
row_3 |
1 |
1 |
3 |
5 |
7 |
|
row_4 |
2 |
2 |
5 |
8 |
11 |
|
row_5 |
3 |
3 |
7 |
11 |
15 |
|
|
|
4 |
9 |
14 |
19 |
Note that although only cell B5 is passed as the FormulaCell parameter, also the references to B2 and B3 of the formula in cell B4 are replaced, because B5 depends on B4.
Summary: Modifies a reference's position and dimension.
Syntax: OFFSET( Reference reference ; Integer rowOffset ; Integer columnOffset [ ; [ Integer newHeight ] [ ; [ Integer newWidth ] ] ] )
Returns: Reference
Constraints: newWidth > 0; newHeight > 0
The modified reference shall be in a valid range, starting from column/row one to the maximum column/row.
Semantics: Shifts reference by rowOffset rows and by columnOffset columns. Optionally, the dimension can be set to newWidth and/or newHeight, if omitted the width/height of the original reference is taken. Note that newHeight may be empty (two consecutive semicolons ;;) followed by a given newWidth argument. Returns the modified reference.
See also COLUMN 6.13.4, COLUMNS 6.13.5, ROW 6.13.29, ROWS 6.13.30
Summary: Look for a matching value in the first column of the given table, and return the value of the indicated column.
Syntax: VLOOKUP( Any Lookup ; Reference|Array DataSource ; Integer Column [ ; Logical RangeLookup = TRUE() ] )
Returns: Any
Constraints: Column >= 1; The searched portion of DataSource shall not include Logical values. Evaluators may evaluate expressions that do not meet the constraint that the searched portion of a DataSource not include Logical values.
Semantics:
If RangeLookup is omitted or TRUE or not 0, the first column of DataSource is assumed to be sorted in ascending order, with smaller Numbers before larger ones, smaller Text values before larger ones (e.g., "A" before "B", and "B" before "BA"), and False before True. If the types are mixed, Numbers are sorted before Text, and Text before Logicals; evaluators without a separate Logical type may include a Logical as a Number. The lookup will try to match an entry of value Lookup. From a sequence of identical values <= Lookup the last entry is taken. If none is found the largest entry less than Lookup is taken as a match. If there is no data less than or equal to Lookup, the #N/A Error is returned. If Lookup is of type Text and the value found is of type Number, the #N/A Error is returned. If DataSource is not sorted, the result is undetermined and implementation-dependent. In most cases it will be arbitrary and just plain wrong due to binary search algorithms.
If RangeLookup is FALSE or 0, DataSource does not need to be sorted and an exact match is searched. Each value in the first column of DataSource is examined in order (starting at the top) until its value matches Lookup. If no value matches, the #N/A Error is returned.
Both methods, if there is a match, return the corresponding value in column Column, relative to the DataSource, where the leftmost column in DataSource is 1.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also HLOOKUP 6.14.5, INDEX 6.14.6, MATCH 6.14.9, OFFSET 6.14.11
The logical functions are the constants TRUE() and FALSE(), the functions that compute Logical values NOT(), AND(), and OR(), and the conditional function IF(). The OpenDocument specification mentions "logical operators"; these are another name for the logical functions.
Note that because of Error values, any logical function that accepts parameters can actually produce TRUE, FALSE, or an Error value, instead of TRUE or FALSE.
These are not bitwise operations, e.g., AND(12;10) produces TRUE(), not 8. See the bit operation functions for bitwise operations.
Summary: Compute logical AND of all parameters.
Syntax: AND( { Logical|NumberSequenceList L }+ )
Returns: Logical
Constraints: Shall have 1 or more parameters
Semantics: Computes the logical AND of the parameters. If all parameters are True, returns True; if any are False, returns False. When given one parameter, this has the effect of converting that one parameter into a Logical value. When given zero parameters, evaluators may return a Logical value or an Error.
Also in array context a logical AND of all arguments is computed, range or array parameters are not evaluated as a matrix and no array is returned. This behavior is consistent with functions like SUM. To compute a logical AND of arrays per element use the * operator in array context.
Summary: Returns constant FALSE
Syntax: FALSE()
Returns: Logical
Constraints: Shall have 0 parameters
Semantics: Returns logical constant FALSE. This may be a Number or a distinct type.
See also TRUE 6.15.9, IF 6.15.4
Summary: Return one of two values, depending on a condition
Syntax: IF( Logical Condition [ ; [ Any IfTrue ] [ ; [ Any IfFalse ] ] ] )
Returns: Any
Constraints: None.
Semantics: Computes Condition. If it is TRUE, it returns IfTrue, else it returns IfFalse. If there is only 1 parameter, IfTrue is considered to be TRUE(). If there are less than 3 parameters, IfFalse is considered to be FALSE(). Thus the 1 parameter version converts Condition into a Logical value. If there are 2 or 3 parameters but the second parameter is null (two consecutive ;; semicolons), IfFalse is considered to be 0. If there are 3 parameters but the third parameter is null, IfFalse is considered to be 0. This function only evaluates IfTrue, or ifFalse, and never both; that is to say, it short-circuits.
See also AND 6.15.2, OR 6.15.8
Summary: Return X unless it is an Error, in which case return an alternative value
Syntax: IFERROR( Any X ; Any Alternative )
Returns: Any
Constraints: None.
Semantics: Computes X. If ISERROR(X) is true, return Alternative, else return X.
Note: This is semantically equivalent to IF(ISERROR(X); Alternative; X), except that X is only computed once.
See also IF 6.15.4, ISERROR 6.13.16
Summary: Return X unless it is an NA, in which case return an alternative value
Syntax: IFNA( Any X ; Any Alternative )
Returns: Any
Constraints: None.
Semantics: Computes X. If ISNA(X) is true, return Alternative, else return X.
Note: This is semantically equivalent to IF(ISNA(X); Alternative; X), except that X is only computed once.
See also IF 6.15.4, ISNA 6.13.20
Summary: Compute logical NOT
Syntax: NOT( Logical L )
Returns: Logical
Constraints: Shall have 1 parameter
Semantics: Computes the logical NOT. If given TRUE, returns FALSE; if given FALSE, returns TRUE.
See also AND 6.15.2, IF 6.15.4
Summary: Compute logical OR of all parameters.
Syntax: OR( { Logical|NumberSequenceList L }+ )
Returns: Logical
Constraints: Shall have 1 or more parameters
Semantics: Computes the logical OR of the parameters. If all parameters are False, it shall return False; if any are True, it shall returns True. When given one parameter, this has the effect of converting that one parameter into a Logical value. When given zero parameters, evaluators may return a Logical value or an Error.
Also in array context a logical OR of all arguments is computed, range or array parameters are not evaluated as a matrix and no array is returned. This behavior is consistent with functions like SUM. To compute a logical OR of arrays per element use the + operator in array context.
See also AND 6.15.2, IF 6.15.4
Summary: Returns constant TRUE
Syntax: TRUE()
Returns: Logical
Constraints: Shall have 0 parameters
Semantics: Returns logical constant TRUE. The result of this function may or may not be equal to 1 when compared using “=”. It always has the value of 1 if used in a context requiring Number (because of the automatic conversions), so if ISNUMBER(TRUE()), then it shall have the value 1.
See also FALSE 6.15.3, IF 6.15.4
Summary: Compute a logical XOR of all parameters.
Syntax: XOR( { Logical L }+ )
Returns: Logical
Constraints: Shall have 1 or more parameters.
Semantics: Computes the logical XOR of the parameters such that the result is an addition modulo 2. If an even number of parameters is True it returns False, if an odd number of parameters is True it returns True. When given one parameter, this has the effect of converting that one parameter into a Logical value.
See also AND 6.15.2, OR 6.15.8
This section describes functions for various mathematical functions, including trigonometric functions like SIN 6.16.55). Note that the constraint text presumes that a value of type Number is a real number (no imaginary component). Unless noted otherwise, all angle measurements are in radians.
Summary: Return the absolute (nonnegative) value.
Syntax: ABS( Number N )
Returns: Number
Constraints: None
Semantics: If N < 0, returns -N, otherwise returns N.
See also Prefix Operator “-” 6.4.16
Summary: Returns the principal value of the arc cosine of a number. The angle is returned in radians.
Syntax: ACOS( Number N )
Returns: Number
Constraints: -1.0 <= N <= 1.0.
Semantics: Computes the arc cosine of a number, in radians.
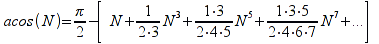
Returns a principal value 0 ≤ result ≤ PI.
See also COS 6.16.19, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the principal value of the inverse hyperbolic cosine
Syntax: ACOSH( Number N )
Returns: Number
Constraints: N >= 1
Semantics: Computes the principal value of the inverse hyperbolic cosine.
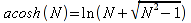
See also COSH 6.16.20, ASINH 6.16.8
Summary: Return the principal value of the arc cotangent of a number. The angle is returned in radians.
Syntax: ACOT( Number N )
Returns: Number
Semantics: Computes the arc cotangent of a number, in radians.
Returns a principal value 0 < result < PI.
See also COT 6.16.21, ATAN 6.16.9, TAN 6.16.69, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the hyperbolic arc cotangent
Syntax: ACOTH( Number N )
Returns: Number
Constraints: ABS(N) > 1
Semantics: Computes the hyperbolic arc cotangent. The hyperbolic arc cotangent is an analog of the ordinary (circular) arc cotangent.
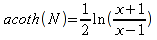
See also COSH 6.16.20, ASINH 6.16.8
Summary: Return the principal value of the arc sine of a number. The angle is returned in radians.
Syntax: ASIN( Number N )
Returns: Number
Constraints: -1 <= N <= 1.
Semantics: Computes the arc sine of a number, in radians.
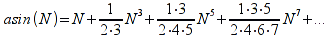
Returns a principal value -PI/2 ≤ result ≤ PI/2.
See also SIN 6.16.55, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the principal value of the inverse hyperbolic sine
Syntax: ASINH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the principal value of the inverse hyperbolic sine.
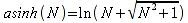
See also SINH 6.16.56, ACOSH 6.16.4
Summary: Return the principal value of the arc tangent of a number. The angle is returned in radians.
Syntax: ATAN( Number N )
Returns: Number
Semantics: Computes the arc tangent of a number, in radians.
Returns a principal value -PI/2 < result < PI/2.
See also ATAN2 6.16.10, TAN 6.16.69, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Returns the principal value of the arc tangent given a coordinate of two numbers.
The angle is returned in radians.
Syntax: ATAN2( Number x ; Number y )
Returns: Number
Constraints: x<>0 or y<>0
Semantics: Computes the arc tangent of two numbers (the x and y coordinates of a point), in radians. This is similar to ATAN(y/x), but the signs of the two numbers are taken into account so that the result covers the full range from -PI() to +PI(). ATAN2(0;0) is implementation-defined, evaluators may return 0 or an Error.
Returns a principal value -PI < result ≤ PI.
See also ATAN 6.16.9, TAN 6.16.69, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the principal value of the inverse hyperbolic tangent
Syntax: ATANH( Number N )
Returns: Number
Constraints: -1 < N < 1
Semantics: Computes the principal value of the inverse hyperbolic tangent.
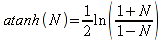
See also COSH 6.16.20, SINH 6.16.56, ASINH 6.16.8, ACOSH 6.16.4, ATAN 6.16.9, ATAN2 6.16.10, FISHER 6.18.26
Summary: Returns the modified Bessel function of integer order In(x).
Syntax: BESSELI( Integer X ; Number N )
Returns: Number
Constraints: N >= 0, INT(N)=N; Evaluators may evaluate expressions where N >= 0 returns a non-error value.
Semantics: Computes the modified Bessel function of integer order In(x). N is also known as the order.
See also BESSELJ 6.16.13, BESSELK 6.16.14, BESSELY 6.16.15
Summary: Returns the Bessel function of integer order Jn(x) (cylinder function)
Syntax: BESSELJ( Integer X ; Number N )
Returns: Number
Constraints: N >= 0, INT(N)=N; Evaluators may evaluate expressions where N >= 0 returns a non-error value.
Semantics: Computes the Bessel function of integer order Jn(x). N is also known as the order.
See also BESSELI 6.16.12, BESSELK 6.16.14, BESSELY 6.16.15
Summary: Returns the modified Bessel function of integer order Kn(x).
Syntax: BESSELK( Integer X ; Number N )
Returns: Number
Constraints: N >= 0, INT (N)=N; Evaluators may evaluate expressions where N >= 0 returns a non-error value.
Semantics: Computes the Bessel function of integer order Kn(x). N is also known as the order.
See also BESSELI 6.16.12, BESSELJ 6.16.13, BESSELY 6.16.15
Summary: Returns the Bessel function of integer order Yn(x), also known as the Neumann function.
Syntax: BESSELY( Integer X ; Number N )
Returns: Number
Constraints: N >= 0, INT(N)=N; Evaluators may evaluate expressions where N >= 0 returns a non-error value.
Semantics: Computes Bessel function of integer order Yn(x), also known as the Neumann function. N is also known as the order.
See also BESSELI 6.16.12, BESSELJ 6.16.13, BESSELK 6.16.14
Summary: Returns the number of different R-length sets that can be selected from N items.
Syntax: COMBIN( Integer N ; Integer R )
Returns: Number
Constraints: N >= 0, R >= 0, R <= N
Semantics: COMBIN returns the binomial coefficient, which is the number of different R-length sets that can be selected from N items. Since they are sets, order in the sets is not relevant. The parameters are truncated (using INT) before use. For example, if a jar contains five marbles, each one a distinct color, the number of different three-marble groups COMBIN(5;3) = 10. The result is
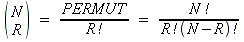
Note that if order is important, use PERMUT instead.
See also PERMUT 6.18.59
Summary: Returns the number of combinations with repetitions.
Syntax: COMBINA( Integer N ; Integer M )
Returns: Number
Constraints: N >= 0, M >= 0, N >= M; Evaluators may evaluate expressions where N >= 0, M >= 0 returns a non-error value.
Semantics: Returns the number of possible combinations of M objects out of N possible ones, with repetitions allowed. Actual arguments that are not integers are truncated (using INT) before use. The result is
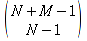
See also COMBIN 6.16.16
Summary: Returns a number converted from one unit system into another
Syntax: CONVERT( Number N ; Text From ; Text Into )
Returns: Number
Constraints: From and Into shall be legal units, and shall be in the same unit group.
Semantics: Returns the number converted from the unit identified by From into the unit identified by Into. A unit is a unit symbol , optionally preceded by a unit prefix (either a decimal prefix or a binary prefix). Units (including both the unit symbol and the optional unit prefix) are case-sensitive.
Evaluators claiming to implement this function shall support at least the following unit symbols (with conversions between them and other units in the same group):
|
Unit group |
Unit symbol |
Description | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Area |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Distance (Length) |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Energy |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Force (Weight) |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Information |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Magnetic Flux Density |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Mass |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Power |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pressure |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Speed |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Temperature |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Time |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Volume |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
If a conversion factor (as listed above) is not exact, an implementation may use a more accurate conversion factor instead.
Implementation-defined unit names should contain a 'FULL STOP' (U+002E) character.
Evaluators shall support decimal prefixes for unit symbols marked with * and binary prefixes for unit symbols marked with †. Evaluators should not support prefixes for other unit symbols.
The unit symbols in parentheses are deprecated unit symbols; evaluators shall support these unit symbols.
Evaluators should use internationally-standardized unit name abbreviations for such additions where possible. Evaluators may support the obsolete symbols “p” and “P” as unit names for Pascals.
For purposes of this function, a year is exactly 365.25 days long.
Evaluators claiming to support this function shall permit the following unit decimal prefixes to be prepended to any unit symbol marked with “*” in the unit table cell above. Adding a unit prefix indicates multiplication of the (scalar) unit by the given prefix value; for example km indicates kilometres, and km2 or km^2 indicate square kilometres.
Table 25 - Decimal Prefixes for use in CONVERT
|
Unit Prefix |
Description |
Prefix Value |
|
"Y" |
yotta |
1E+24 |
|
"Z" |
zetta |
1E+21 |
|
"E" |
exa |
1E+18 |
|
"P" |
peta |
1E+15 |
|
"T" |
tera |
1E+12 |
|
"G" |
giga |
1E+09 |
|
"M" |
mega |
1E+06 |
|
"k" |
kilo |
1E+03 |
|
"h" |
hecto |
1E+02 |
|
“da” or "e" |
deka ( Note: “e” is not a standard SI prefix |
1E+01 |
|
"d" |
deci |
1E-01 |
|
"c" |
centi |
1E-02 |
|
"m" |
milli |
1E-03 |
|
"u" |
micro Note: this is “u”, not the standard SI µ |
1E-06 |
|
"n" |
nano |
1E-09 |
|
"p" |
pico |
1E-12 |
|
"f" |
femto |
1E-15 |
|
"a" |
atto |
1E-18 |
|
"z" |
zepto |
1E-21 |
|
"y" |
yocto |
1E-24 |
The prefix “e” for 10 1 is nonstandard and included for backward compatibility with legacy applications and documents.
The unit names marked with † in the unit symbol table above (see the Information group) shall also support the following binary prefixes per IEC 60027-2:
Table 26 - Binary prefixes for use in CONVERT
|
Binary Unit Prefix |
Description |
Prefix Value |
Derived from |
|
"Yi" |
yobi |
2^80 = 1 208 925 819 614 629 174 706 176 |
yotta |
|
"Zi" |
zebi |
2^70 = 1 180 591 620 717 411 303 424 |
zetta |
|
"Ei" |
exbi |
2^60 = 1 152 921 504 606 846 976 |
exa |
|
"Pi" |
pebi |
2^50 = 1 125 899 906 842 624 |
peta |
|
"Ti" |
tebi |
2^40 = 1 099 511 627 776 |
tera |
|
"Gi" |
gibi |
2^30 = 1 073 741 824 |
giga |
|
"Mi" |
mebi |
2^20 = 1 048 576 |
mega |
|
"Ki" |
kibi |
2^10 = 1024 |
kilo |
In the case where there is a naming conflict (a unit name with a prefix is the same as an unprefixed name), the unprefixed name shall take precedence.
Evaluators may implement this conversion by first converting to some SI unit (e.g., meter and kilogram), and then convert again to the final unit.
See also EUROCONVERT 6.16.29
Summary: Return the cosine of an angle specified in radians.
Syntax: COS( Number N )
Returns: Number
Constraints: None
Semantics: Computes the cosine of an angle specified in radians.
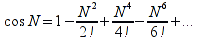
See also ACOS 6.16.3, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the hyperbolic cosine of the given hyperbolic angle
Syntax: COSH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic cosine of a hyperbolic angle. The hyperbolic cosine is an analog of the ordinary (circular) cosine. The points (cosh t, sinh t) define the right half of the equilateral hyperbola, just as the points (cos t, sin t) define the points of a circle.
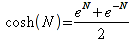
See also ACOSH 6.16.4, SINH 6.16.56, TANH 6.16.70
Summary: Return the cotangent of an angle specified in radians
Syntax: COT( Number N )
Returns: Number
Constraints: None
Semantics: Computes the cotangent of an angle specified in radians.
COT(x) = 1 / TAN(x)
See also ACOT 6.16.5, TAN 6.16.69, RADIANS 6.16.49, DEGREES 6.16.25, SIN 6.16.55, COS 6.16.19
Summary: Return the hyperbolic cotangent of the given hyperbolic angle
Syntax: COTH( Number N )
Returns: Number
Constraints: N<>0
Semantics: Computes the hyperbolic cotangent of a hyperbolic angle. The hyperbolic cotangent is an analog of the ordinary (circular) cotangent.
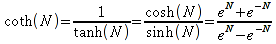
See also ACOSH 6.16.4, SINH 6.16.56, TANH 6.16.70
Summary: Return the cosecant of an angle specified in radians.
Syntax: CSC( Number N )
Returns: Number
Constraints: None
Semantics: Computes the cosecant cosine of an angle specified in radians. Equivalent to:
1/SIN(N)
See also SIN 6.16.55
Summary: Return the hyperbolic cosecant of the given angle specified in radians
Syntax: CSCH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic cosecant of a hyperbolic angle. This is equivalent to:
1/SINH(N)
See also SINH 6.16.56, CSCH
Summary: Convert radians to degrees.
Syntax: DEGREES( Number N )
Returns: Number
Constraints: None
Semantics: Converts a number in radians into a number in degrees. DEGREES(N) is equal to N*180/PI().
See also RADIANS 6.16.49, PI 6.16.45
Summary: Report if two numbers are equal, returns 1 if they are equal.
Syntax: DELTA( Number X [ ; Number Y = 0 ] )
Returns: Number
Constraints: None
Semantics: If X and Y are equal, return 1, else 0. Y is set to 0 if omitted.
See also Infix operator “=” 6.4.7
Summary: Calculates the error function.
Syntax: ERF( Number z0 [ ; Number z1 ] )
Returns: Number
Constraints: None
Semantics: With a single argument, returns the error function of z0:
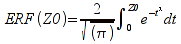
With two arguments, returns
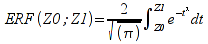
See also ERFC 6.16.28
Summary: Calculates the complementary error function.
Syntax: ERFC( Number z )
Returns: Number
Constraints: None
Semantics: returns the complementary error function of z: ERFC(z) = 1 – ERF(z)
See also ERF 6.16.27
Summary: Converts a Number, representing a value in one European currency, to an equivalent value in another European currency, according to the fixed conversion rates defined by the Council of the European Union.
Syntax: EUROCONVERT( Number N ; Text From ; Text To [ ; Logical FullPrecision = FALSE() [ ; Integer TriangulationPrecision ] ] )
Returns: Currency
Constraints: From and To shall be known to the evaluator. TriangulationPrecision shall be >= 3, if not omitted.
If an evaluator does not support the parameters FullPrecision and TriangulationPrecision, FullPrecision should be assumed to be false.
Semantics: Returns the given money value of a conversion from From currency into To currency. Both From and To shall be the official [ISO4217] abbreviation for the given currency; note that these are in upper case, but the function accepts lower case or mixed case as well. If From and To are equal currencies, the value N is returned, no precision or triangulation is applied.
The function shall use the rates of exchange as set by the European Commission, as follows:
|
From |
To |
Rate |
Currency |
Decimals |
|
"EUR" |
"ATS" |
13.7603 |
Austrian Schilling |
2 |
|
"EUR" |
"BEF" |
40.3399 |
Belgian Franc |
0 |
|
"EUR" |
"DEM" |
1.95583 |
German Mark |
2 |
|
"EUR" |
"ESP" |
166.386 |
Spanish Peseta |
0 |
|
"EUR" |
"FIM" |
5.94573 |
Finnish Markka |
2 |
|
"EUR" |
"FRF" |
6.55957 |
French Franc |
2 |
|
"EUR" |
"IEP" |
0.787564 |
Irish Pound |
2 |
|
"EUR" |
"ITL" |
1936.27 |
Italian Lira |
0 |
|
"EUR" |
"LUF" |
40.3399 |
Luxembourg Franc |
0 |
|
"EUR" |
"NLG" |
2.20371 |
Dutch Guilder |
2 |
|
"EUR" |
"PTE" |
200.482 |
Portuguese Escudo |
2 |
|
"EUR" |
"GRD" |
340.750 |
Greek Drachma |
2 |
|
"EUR" |
"SIT" |
239.640 |
Slovenian Tolar |
2 |
|
“EUR” |
“MTL” |
0.429300 |
Maltese Lira |
2 |
|
“EUR” |
“CYP” |
0.585274 |
Cypriot Pound |
2 |
|
"EUR" |
"SKK" |
30.1260 |
Slovak Koruna |
2 |
As new member countries adopt the Euro, new conversion rates will become active and evaluators may add them using the respective [ISO4217] codes and fixed rates as defined by the European Council, on the basis of a European Commission proposal.
Note:
The European Commission's Euro entry page is http://ec.europa.eu/euro/
The conversion rates and triangulation rules are available at http://ec.europa.eu/economy_finance/euro/adoption/conversion/index_en.htm with links to the European Council Regulation legal documents at the http://eur-lex.europa.eu/ European Union law database server.
If FullPrecision is omitted or False, the result is rounded according to the decimals of the To currency. If FullPrecision is True the result is not rounded.
If TriangulationPrecision is given and >=3, the intermediate result of a triangular conversion (currency1,EUR,currency2) is rounded to that precision. If TriangulationPrecision is omitted, the intermediate result is not rounded. Also if To currency is “EUR”, TriangulationPrecision precision is used as if triangulation was needed and conversion from EUR to EUR was applied.
See also CONVERT
Summary: Rounds a number up to the nearest even integer. Rounding is away from zero.
Syntax: EVEN( Number N )
Returns: Number
Constraints: None
Semantics: Returns the even integer whose sign is the same as N's and whose absolute value is greater than or equal to the absolute value of N.
See also ODD 6.16.44
Summary: Returns e raised by the given number.
Syntax: EXP( Number X )
Returns: Number
Constraints: None
Semantics: Computes
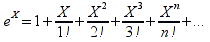
See also LOG 6.16.40, LN 6.16.39
Summary: Return factorial (!).
Syntax: FACT( Integer F )
Returns: Number
Constraints: F >= 0
Semantics: Return the factorial
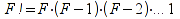
F(0)=F(1)=1.
See also Infix Operator "*" 6.4.4, GAMMA 6.16.34
Summary: Returns double factorial (!!).
Syntax: FACTDOUBLE( Integer F )
Returns: Number
Constraints: F >= 0
Semantics: Return
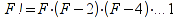
Double factorial is computed by multiplying every other number in the 1..N range, with N always being included.
See also Infix Operator "*" 6.4.4, GAMMA 6.16.34, FACT 6.16.32
Summary: Return gamma function value.
Syntax: GAMMA( Number N )
Returns: Number
Constraints: N<>0 and N not a negative integer.
Semantics: Return
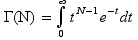
with Γ(N+1) = N * Γ(N). Note that for non-negative integers N, Γ(N+1) = N! = FACT(N). Note that GAMMA can accept non-integers.
See also FACT 6.16.32
Summary: Returns the natural logarithm of the GAMMA function.
Syntax: GAMMALN( Number X )
Returns: Number
Constraints: For each X, X > 0
Semantics: Returns the same value as =LN(GAMMA(X))
See also GAMMA 6.16.34, FACT 6.16.32
Summary: Returns the greatest common divisor (GCD)
Syntax: GCD( { NumberSequenceList X }+ )
Returns: Number
Constraints: For all a in X: INT(a) >= 0 and for at least one a in X: INT(a)>0
Semantics: Return the largest integer N such that for every a in X: INT(a) is a multiple of N.
Note: If for all a in X: INT(a)=0 the return value is implementation-defined but is either an Error or 0.
See also LCM 6.16.38
Summary: Returns 1 if a number is greater than or equal to another number, else returns 0.
Syntax: GESTEP( Number X [ ; Number Step = 0 ] )
Returns: Number
Semantics: Number X is tested against number Step. If greater or equal 1 is returned, else 0. The second parameter is assumed 0 if omitted. If one of the parameters is not a Number, the function results in an Error.
See also
Summary: Returns the least common multiplier
Syntax: LCM( { NumberSequenceList X }+ )
Returns: Number
Constraints: For all in X: INT(X)=X, X >= 0
Semantics: Return the smallest integer that is the multiple of the given values. Each value has INT applied to it first. Note that if given two numbers, ABS(a*b)=LCM(a;b)*GCD(a;b).
See also GCD 6.16.36
Summary: Return the natural logarithm of a number.
Syntax: LN( Number X )
Returns: Number
Constraints: X>0
Semantics: Computes the natural logarithm (base e) of the given number.
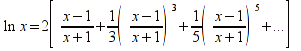
See also LOG 6.16.40, LOG10 6.16.41, POWER 6.16.46, EXP 6.16.31
Summary: Return the logarithm of a number in a specified base.
Syntax: LOG( Number N [ ; Number Base = 10 ] )
Returns: Number
Constraints: N > 0
Semantics: Computes the logarithm of a number in the specified base. Note that if the base is not specified, the logarithm base 10 is returned.
See also LOG10 6.16.41, LN 6.16.39, POWER 6.16.46, EXP 6.16.31
Summary: Return the base 10 logarithm of a number.
Syntax: LOG10( Number N )
Returns: Number
Constraints: N > 0
Semantics: Computes the base 10 logarithm of a number.
See also LOG 6.16.40, LN 6.16.39, POWER 6.16.46, EXP 6.16.31
Summary: Return the remainder when one number is divided by another number.
Syntax: MOD( Number a ; Number b )
Returns: Number
Constraints: b != 0
Semantics: Computes the remainder of a/b. The remainder has the same sign as b.
See also Infix Operator "/" 6.4.5, QUOTIENT 6.16.48
Summary: Returns the multinomial for the given values.
Syntax: MULTINOMIAL( { NumberSequence A }+ )
Returns: Number
Constraints: None
Semantics: Returns the multinomial of the sequence A = (a1, a2, ..., an). Multinomial is defined as FACT(a1+a2+...+an) / (FACT(a1)*FACT(a2)*...*FACT(an))
See also FACT 6.16.32
Summary: Rounds a number up to the nearest odd integer, where "up" means "away from 0".
Syntax: ODD( Number N )
Returns: Number
Constraints: None
Semantics: Returns the odd integer whose sign is the same as N's and whose absolute value is greater than or equal to the absolute value of N. In other words, any "rounding" is away from zero. By definition, ODD(0) is 1.
See also EVEN 6.16.30
Summary: Return the approximate value of Pi.
Syntax: PI()
Returns: Number
Constraints: None.
Semantics: This function takes no arguments and returns the (approximate) value of pi. Evaluators should use the closest possible numerical representation that is possible in their representation of numbers.
See also SIN 6.16.55, COS 6.16.19
Summary: Return the value of one number raised to the power of another number.
Syntax: POWER( Number a ; Number b )
Returns: Number
Constraints: None
Semantics: Computes a raised to the power b.
•.POWER(0,0) is implementation-defined, but shall be one of 0,1, or an Error.
•.POWER(0,b), where b < 0, shall return an Error.
•.POWER(a,b), where a<=0 and INT(b)!=b, is implementation-defined.
See also LOG 6.16.40, LOG10 6.16.41, LN 6.16.39, EXP 6.16.31
Summary: Multiply the set of numbers, including all numbers inside ranges
Syntax: PRODUCT( { NumberSequence N }+ )
Returns: Number
Constraints: None
Semantics: Returns the product of the Numbers (and only the Numbers, i.e., not Text inside ranges). This is equivalent to SUM except that it uses the * operator instead of +.
See also SUM 6.16.61
Summary: Return the integer portion of a division.
Syntax: QUOTIENT( Number A ; Number B )
Returns: Number
Constraints: B <> 0
Semantics: Return the integer portion of a division.
See also MOD 6.16.42
Summary: Convert degrees to radians.
Syntax: RADIANS( Number N )
Returns: Number
Constraints: None
Semantics: Converts a number in degrees into a number in radians. RADIANS(N) is equal to N*PI()/180.
See also DEGREES 6.16.25, PI 6.16.45
Summary: Return a random number between 0 (inclusive) and 1 (exclusive).
Syntax: RAND()
Returns: Number
Semantics: This function takes no arguments and returns a random number between 0 (inclusive) and 1 (exclusive). Note that unlike most functions, this function will typically return different values when called each time with the same (empty set of) parameters.
See also RANDBETWEEN 6.16.51
Summary: Return a random integer number between A and B.
Syntax: RANDBETWEEN( Integer A ; Integer B )
Returns: Integer
Constraints: A <= B
Semantics: The function returns a random integer number between A and B inclusive. Note that unlike most functions, this function will often return different values when called each time with the same parameters.
See also RAND 6.16.50
Summary: Return the secant of an angle specified in radians.
Syntax: SEC( Number N )
Returns: Number
Constraints: None
Semantics: Computes the secant cosine of an angle specified in radians. Equivalent to:
1/COS(N)
See also SIN 6.16.55
Summary: Returns the sum of a power series.
Syntax: SERIESSUM( Number X ; Number N ; Number M ; Array Coefficients )
●X: the independent variable of the power series.
●N: the initial power to which X is to be raised.
●M: the increment by which to increase N for each term in the series.
●Coefficients: a set of coefficients by which each successive power of the variable X is multiplied.
Returns: Number
Constraints:
All elements of Coefficients are of type Number.
X < > 0 if any of the exponents, which are generated from N and M, are negative.
Semantics: Returns a sum of powers of the number X.
With C being the number of coefficients the function is computed as:
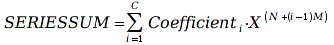
Summary: Return the sign of a number
Syntax: SIGN( Number N )
Returns: Number
Constraints: None
Semantics: If N < 0, returns -1; if N > 0, returns +1; if N == 0, returns 0.
See also ABS 6.16.2
Summary: Return the sine of an angle specified in radians
Syntax: SIN( Number N )
Returns: Number
Constraints: None
Semantics: Computes the sine of an angle specified in radians.
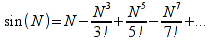
See also ASIN 6.16.7, RADIANS 6.16.49, DEGREES 6.16.25
Summary: Return the hyperbolic sine of the given hyperbolic angle
Syntax: SINH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic sine of a hyperbolic angle. The hyperbolic sine is an analog of the ordinary (circular) sine. The points (cosh t, sinh t) define the right half of the equilateral hyperbola, just as the points (cos t, sin t) define the points of a circle.
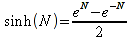
See also ASINH 6.16.8, COSH 6.16.20, TANH 6.16.70
Summary: Return the hyperbolic secant of the given angle specified in radians
Syntax: SECH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic secant of a hyperbolic angle. This is equivalent to:
1/COSH(N)
See also SINH 6.16.56, CSCH
Summary: Return the square root of a number
Syntax: SQRT( Number N )
Returns: Number
Constraints: N>=0
Semantics: Returns the square root of a non-negative number. This function shall produce an Error if given a negative number; for producing complex numbers, see IMSQRT.
See also POWER 6.16.46, IMSQRT 6.8.24, SQRTPI 6.16.59
Summary: Return the square root of a number multiplied by pi.
Syntax: SQRTPI( Number N )
Returns: Number
Constraints: N>=0
Semantics: Returns the square root of a non-negative number after it was first multiplied by PI, that is, SQRT(N*PI()). This function shall produce an Error if given a negative number; for producing complex numbers, see IMSQRT.
See also POWER 6.16.46, SQRT 6.16.58, PI 6.16.45, IMSQRT 6.8.24
Summary: Evaluates a function on a range.
Syntax: SUBTOTAL( Integer function ; NumberSequence sequence )
Returns: Number
Constraints: None
Semantics: Computes a given function on a number sequence. Function is denoted by the first parameter: The difference from standard functions is that all members of the sequence are excluded which:
●include a call to SUBTOTAL in their formula
●are in a row that is hidden by a table:visibility=”filter” attribute of the <table:table-row> element.
●are in a row that is hidden by a table:visibility=”collapse” attribute of the <table:table-row> element if the function ID is one of 101...111.
|
Function |
Exclude hidden by filter |
Exclude hidden by filter or collapsed |
|
AVERAGE |
1 |
101 |
|
COUNT |
2 |
102 |
|
COUNTA |
3 |
103 |
|
MAX |
4 |
104 |
|
MIN |
5 |
105 |
|
PRODUCT |
6 |
106 |
|
STDEV |
7 |
107 |
|
STDEVP |
8 |
108 |
|
SUM |
9 |
109 |
|
VAR |
10 |
110 |
|
VARP |
11 |
111 |
See also SUM 6.16.61, AVERAGE 6.18.3
Summary: Sum (add) the set of numbers, including all numbers in ranges
Syntax: SUM( { NumberSequenceList N }+ )
Returns: Number
Constraints: N != {}; Evaluators may evaluate expressions that do not meet this constraint.
Semantics: Adds Numbers (and only Numbers) together (see the text on conversions).
See also AVERAGE 6.18.3
Summary: Sum the values of cells in a range that meet a criteria.
Syntax: SUMIF( ReferenceList|Reference R ; Criterion C [ ; Reference S ] )
Returns: Number
Constraints: Does not accept constant values as the range parameter.
Semantics: Sums the values of type Number in the range R or S that meet the Criterion C (4.11.8).
If S is not given, R may be a reference list. If S is given, R shall not be a reference list with more than 1 references and an Error be generated if it was.
If the optional range S is included, then the values of S starting from the top left cell and matching the geometry of R (same number of rows and columns) are summed if the corresponding value in R meets the Criterion. The actual range S is not considered. If the resulting range exceeds the sheet bounds, column numbers larger than the maximum column and row numbers larger than the maximum row are silently ignored, no Error is generated for this case.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also COUNTIF 6.13.9, SUM 6.16.61, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: Sum the values of cells in a range that meet multiple criteria in multiple ranges.
Syntax: SUMIFS( Reference R ; Reference R1 ; Criterion C1 [ ; Reference R2 ; Criterion C2 ]... )
Returns: Number
Constraints: Does not accept constant values as the reference parameter.
Semantics: Sums the value of cells in range R that meet the Criterion C1 in the reference range R1 and the Criterion C2 in the reference range R2, and so on (4.11.8). All reference ranges shall have the same dimension and size, else an Error is returned. A logical AND is applied between each array result of each selection; an entry is counted only if the same position in each array is the result of a criteria match.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also AVERAGEIFS 6.18.6, COUNTIFS 6.13.10, SUMIF 6.16.62, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: Returns the sum of the products of the matrix elements.
Syntax: SUMPRODUCT( { ForceArray Array A }+ )
Returns: Number
Constraints: All matrices shall have the same dimensions.
Semantics: Multiplies the corresponding elements of all matrices and returns the sum of them.
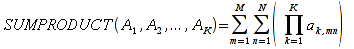
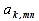
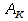
Summary: Sum (add) the set of squares of numbers, including all numbers in ranges
Syntax: SUMSQ( { NumberSequence N }+ )
Returns: Number
Constraints: N != {}; Evaluators may evaluate expressions that do not meet this constraint.
Semantics: Adds squares of Numbers (and only Numbers) together. See the text on conversions.
Summary: Returns the sum of the difference between the squares of the matrices A and B.
Syntax: SUMX2MY2( ForceArray Array A ; ForceArray Array B )
Returns: Number
Constraints: Both matrices shall have the same dimensions.
Semantics: Sums up the differences of the corresponding elements squares for two matrices.
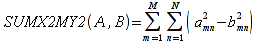
Summary: Returns the total sum of the squares of the matrices A and B.
Syntax: SUMX2PY2( ForceArray Array A ; ForceArray Array B )
Returns: Number
Constraints: Both matrices shall have the same dimensions.
Semantics: Sums up the squares of each element of the two matrices.
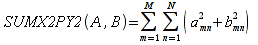
Summary: Returns the sum of the squares of the differences between matrix A and B.
Syntax: SUMXMY2( ForceArray Array A ; ForceArray Array B )
Returns: Number
Constraints: Both matrices shall have the same dimensions.
Semantics: Sums up the squares of the differences of the corresponding elements for two matrices.
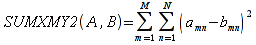
Summary: Return the tangent of an angle specified in radians
Syntax: TAN( Number N )
Returns: Number
Constraints: None
Semantics: Computes the tangent of an angle specified in radians.
TAN(x) = SIN(x) / COS(x)
See also ATAN 6.16.9, ATAN2 6.16.10, RADIANS 6.16.49, DEGREES 6.16.25, SIN 6.16.55, COS 6.16.19, COT 6.16.21
Summary: Return the hyperbolic tangent of the given hyperbolic angle
Syntax: TANH( Number N )
Returns: Number
Constraints: None
Semantics: Computes the hyperbolic tangent of a hyperbolic angle. The hyperbolic tangent is an analog of the ordinary (circular) tangent. The points (cosh t, sinh t) define the right half of the equilateral hyperbola, just as the points (cos t, sin t) define the points of a circle.

See also ATANH 6.16.11, SINH 6.16.56, COSH 6.16.20, FISHERINV 6.18.27
Summary: Round a number N up to the nearest multiple of the second parameter, significance.
Syntax: CEILING( Number N [ ; [ Number significance ] [ ; Number mode ] ] )
Returns: Number
Constraints: Both N and significance shall be numeric and have the same sign if not 0.
Semantics: Rounds a number up to a multiple of the second number. If significance is omitted or an empty parameter (two consecutive ;; semicolons) it is assumed to be -1 if N is negative and +1 if N is non-negative, making the function act like the normal mathematical ceiling function if mode is not given or zero. If mode is given and not equal to zero, the absolute value of N is rounded away from zero to a multiple of the absolute value of significance and then the sign applied . If mode is omitted or zero, rounding is toward positive infinity; the number is rounded to the smallest multiple of significance that is equal-to or greater than N. If any of the two parameters N or significance is zero, the result is zero.
Note: Many application user interfaces have a CEILING function with only two parameters, and somewhat different semantics than given here (e.g., they operate as if there was a non-zero mode value). These CEILING functions are inconsistent with the standard mathematical definition of CEILING.
See also FLOOR 6.17.3, INT 6.17.2
Summary: Rounds a number down to the nearest integer.
Syntax: INT( Number N )
Returns: Number
Constraints: None
Semantics: Returns the nearest integer whose value is less than or equal to N. Rounding is towards negative infinity.
See also ROUND 6.17.5, TRUNC 6.17.8
Summary: Round a number N down to the nearest multiple of the second parameter, significance.
Syntax: FLOOR( Number N [ ; [ Number significance ] [ ; Number mode ] ] )
Returns: Number
Constraints: Both N and significance shall be numeric and have the same sign.
Semantics: Rounds a number down to a multiple of the second number. If significance is omitted or an empty parameter (two consecutive ;; semicolons) it is assumed to be -1 if N is negative and +1 if N is non-negative, making the function act like the normal mathematical floor function if mode is not given or zero. If mode is given and not equal to zero, the absolute value of N is rounded away from zero to a multiple of the absolute value of significance and then the sign applied . Otherwise, it rounds toward negative infinity, and the result is the largest multiple of significance that is less than or equal to N. If any of the two parameters N or significance is zero, the result is zero.
Note: Many application user interfaces have a FLOOR function with only two parameters, and somewhat different semantics than given here (e.g., they operate as if there was a non-zero mode value). These FLOOR functions are inconsistent with the standard mathematical definition of FLOOR.
See also CEILING 6.17.1, INT 6.17.2
Summary: Rounds the number to given multiple.
Syntax: MROUND( Number a ; Number b )
Returns: Number
Constraints: None
Semantics: Returns the number X, for which the following holds: X/b=INT(X/b) (b divides X), and for any other Y with the same property, ABS(Y-a)>=ABS(X-a). In case that two such X exist, the greater one is the result. In less formal language, this function rounds the number a to multiples of b.
See also ROUND 6.17.5
Summary: Rounds the value X to the nearest multiple of the power of 10 specified by Digits.
Syntax: ROUND( Number X [ ; Number Digits = 0 ] )
Returns: Number
Constraints: None
Semantics: Round number X to the precision specified by Digits. The number X is rounded to the nearest power of 10 given by 10 −Digits. If Digits is zero, or absent, round to the nearest decimal integer. If Digits is non-negative, round to the specified number of decimal places. If Digits is negative, round to the left of the decimal point by -Digits places. If X is halfway between the two nearest values, the result shall round away from zero. Note that if X is a Number, and Digits <= 0, the results will always be an integer (without a fractional component).
See also TRUNC 6.17.8, INT 6.17.2
Summary: Rounds the value X towards zero to the number of digits specified by Digits
Syntax: ROUNDDOWN( Number X [ ; Integer Digits = 0 ] )
Returns: Number
Constraints: None
Semantics: Round X towards zero, to the precision specified by Digits. The number returned is a multiple of 10−Digits. If Digits is zero, or absent, round to the largest decimal integer whose absolute value is smaller or equal to the absolute value of X.
If Digits is positive, round towards zero to the specified number of decimal places. If Digits is negative, round towards zero to the left of the decimal point by -Digits places.
See also TRUNC 6.17.8, INT 6.17.2, ROUND 6.17.5, ROUNDUP 6.17.7
Summary: Rounds the value X away from zero to the number of digits specified by Digits
Syntax: ROUNDUP( Number X [ ; Integer Digits = 0 ] )
Returns: Number
Constraints: None
Semantics: Round X away from zero, to the precision specified by Digits. The number returned is a multiple of 10−Digits. If Digits is zero, or absent, round to the smallest decimal integer whose absolute value is larger or equal to the absolute value of X. If Digits is positive, round away from zero to the specified number of decimal places. If Digits is negative, round away from zero to the left of the decimal point by -Digits places.
See also TRUNC 6.17.8, INT 6.17.2, ROUND 6.17.5, ROUNDDOWN 6.17.6
Summary: Truncate a number to a specified number of digits.
Syntax: TRUNC( Number a ; Integer b )
Returns: Number
Constraints: None
Semantics: Truncate number a to the number of digits specified by b. If b is zero, or absent, truncate to a decimal integer. If b is positive, truncate to the specified number of decimal places. If b is negative, truncate to the left of the decimal point.
See also ROUND 6.17.5, INT 6.17.2
The following are statistical functions (functions that report information on a set of numbers). Some functions that could also be considered statistical functions, such as SUM, are listed elsewhere.
Summary: Calculates the average of the absolute deviations of the values in list.
Syntax: AVEDEV( { NumberSequenceList N }+ )
Returns: Number
Constraints: None.
Semantics:
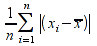
See also SUM, AVERAGE
Summary: Average the set of numbers
Syntax: AVERAGE( { NumberSequence N }+ )
Returns: Number
Constraints: At least one Number included. Returns an Error if no Numbers provided.
Semantics: Computes SUM(List) / COUNT(List).
See also SUM 6.16.61, COUNT 6.13.6
Summary: Average values, including values of type Text and Logical.
Syntax: AVERAGEA( { Any N }+ )
Returns: Number
Constraints: At least one value included. Returns an Error if no value provided.
Semantics: A variant of the AVERAGE function that includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1 and False is treated as 0. Empty cells are not included. Any N may be of type ReferenceList.
See also AVERAGE 6.18.3
Summary: Average the values of cells in a range that meet a criteria.
Syntax: AVERAGEIF( Reference R ; Criterion C [ ; Reference A ] )
Returns: Number
Constraints: Does not accept constant values as reference parameters.
Semantics: If reference A is omitted, averages the values of cells in the reference range R that meet the Criterion C (4.11.8). If reference A is given, averages the values of cells of a range that is constructed using the top left cell of reference A and applying the dimensions, shape and size, of reference R. If no cell in range R matches the Criterion C, an Error is returned. If no Numbers are in the range to be averaged, an Error is returned.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also AVERAGEIFS 6.18.6, COUNTIF 6.13.9, SUMIF 6.16.62, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: Average the values of cells that meet multiple criteria in multiple ranges.
Syntax: AVERAGEIFS( Reference A ; Reference R1 ; Criterion C1 [ ; Reference R2 ; Criterion C2 ]... )
Returns: Number
Constraints: Does not accept constant values as reference parameters.
Semantics: Averages the values of cells in the reference range A that meet the Criterion C1 in the reference range R1 and the Criterion C2 in the reference range R2, and so on (4.11.8). All reference ranges shall have the same dimension and size, else an Error is returned. A logical AND is applied between each array result of each selection; a cell of reference range A is evaluated only if the same position in each array is the result of a Criterion match. If no numbers are in the result set to be averaged, an Error is returned.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS or HOST-SEARCH-CRITERIA-MUST-APPLY-TO-WHOLE-CELL properties. 3.4
See also AVERAGEIF 6.18.5, COUNTIFS 6.13.10, SUMIFS 6.16.63, Infix Operator "=" 6.4.7, Infix Operator "<>" 6.4.8, Infix Operator Ordered Comparison ("<", "<=", ">", ">=") 6.4.9
Summary: returns the value of the probability density function or the cumulative distribution function for the beta distribution.
Syntax: BETADIST( Number x ; Number a ; Number b [ ; Number a = 0 [ ; Number b = 1 [ ; Logical Cumulative = TRUE() ] ] ] )
Returns: Number
Constraints: a > 0, b > 0, a < b,
If a < 1, then the density function has a pole at x = a.
If b < 1, then the density function has a pole at x = b.
In both cases, if x=a respectively x=b and Cumulative=FALSE(), an Error is returned.
Semantics: If Cumulative is FALSE(), BETADIST returns 0 if x < a or x > b and the value
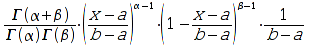
otherwise.
If Cumulative is TRUE(), BETADIST returns 0 if x < a, 1 if x > b, and the value
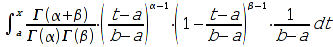
otherwise.
Note: With substitution
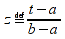
the term can be written as
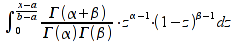
See also BETAINV 6.18.8
Summary: returns the inverse of BETADIST(x;a;b;a;b;TRUE()).
Syntax: BETAINV( Number p ; Number a ; Number b [ ; Number a = 0 [ ; Number b = 1 ] ] )
Returns: Number
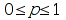
Semantics: BETAINV returns the unique number x in the closed interval from a to b such that BETADIST(x;a;b;a;b) = p.
See also BETADIST 6.18.7
Summary: Returns the probability of a trial result using binomial distribution.
Syntax: BINOM.DIST.RANGE( Integer N ; Number P ; Integer S [ ; Integer S2 ] )
Returns: Number
Constraints: 0<=P<=1, 0<=S<=S2<=N
Semantics: Let N be a total number of independent trials, and P be a probability of success for each trial. This function returns the probability that the number of successful trials shall be exactly S. If the optional parameter S2 is provided, this function returns the probability that the number of successful trials shall lie between S and S2 inclusive.
This function is computed as follows:
If S2 is not given, let S2:=S. Then the function returns the value of
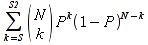
See also BINOMDIST 6.18.10
Summary: Returns the binomial distribution.
Syntax: BINOMDIST( Integer S ; Integer N ; Number P ; Logical Cumulative )
Returns: Number
Constraints: 0 <= P <= 1; 0 <= S <= N
Semantics: If Cumulative is FALSE(), this function returns the same result as BINOM.DIST.RANGE(N;P;S). If Cumulative is TRUE(), it is equivalent to calling BINOM.DIST.RANGE(N;P;0;S).
See also BINOM.DIST.RANGE 6.18.9
Summary: returns the right-tail probability for the c2-distribution.
Syntax: LEGACY.CHIDIST( Number x ; Number DegreesOfFreedom )
Returns: Number
Constraints: DegreesOfFreedom is a positive integer.
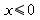
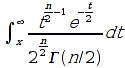
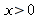
See also CHISQDIST 6.18.12, LEGACY.CHITEST 6.18.15
Summary: returns the value of the probability density function or the cumulative distribution function for the c2-distribution.
Syntax: CHISQDIST( Number x ; Number DegreesOfFreedom [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: DegreesOfFreedom is a positive integer.
Semantics: In the following n is DegreesOfFreedom.
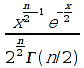
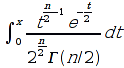
See also LEGACY.CHIDIST 6.18.11
Summary: returns the inverse of LEGACY.CHIDIST(x; DegreesOfFreedom).
Syntax: LEGACY.CHIINV( Number p ; Number DegreesOfFreedom )
Returns: Number
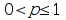
Semantics: LEGACY.CHIINV returns the unique number x such that LEGACY.CHIDIST(x; DegreesOfFreedom) = p.
See also LEGACY.CHIDIST 6.18.11
Summary: returns the inverse of CHISQDIST(x; DegreesOfFreedom; TRUE()).
Syntax: CHISQINV( Number p ; Number DegreesOfFreedom )
Returns: Number
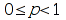
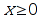
See also CHISQDIST 6.18.12
Summary: Returns some Chi square goodness-for-fit test.
Syntax: LEGACY.CHITEST( ForceArray Array A ; ForceArray Array E )
Returns: Number
Constraints:
ROWS(A) == ROWS(E)
COLUMNS(A) == COLUMNS(E)
COLUMNS(A) * ROWS(A) > 1
Semantics:
For an empty element or an element of type Text or Boolean in A the element at the corresponding position of E is ignored, and vice versa.
●A actual observation data.
●E expected values.
First a Chi square statistic is calculated:
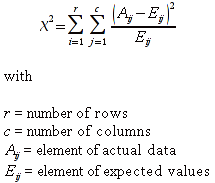
Then LEGACY.CHIDIST is called with the Chi-square value and a degree of freedom (df):
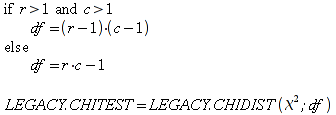
See also LEGACY.CHIDIST 6.18.11
Summary: Returns the confidence interval for a population mean.
Syntax: CONFIDENCE( Number alpha ; Number stddev ; Number size )
Returns: Number
Constraints: 0 < alpha < 1; stddev > 0, size >= 1
Semantics: Calling this function is equivalent to calling NORMINV(1 - alpha / 2; 0; 1) * stddev / SQRT (size)
Summary: Calculates the correlation coefficient of values in N1 and N2.
Syntax: CORREL( ForceArray Array N1 ; ForceArray Array N2 )
Returns: Number
Constraints: COLUMNS(N1) = COLUMNS(N2), ROWS(N1) = ROWS(N2), both sequences shall contain at least one number at corresponding positions each.
Semantics: Has the same value as COVAR(N1;N2)/STDEVP(N1)*(STDEVP(N2)). The CORREL function actually is identical to the PEARSON function.
For an empty element or an element of type Text or Boolean in N1 the element at the corresponding position of N2 is ignored, and vice versa.
See also PEARSON 6.18.56
Summary: Calculates covariance of two cell ranges.
Syntax: COVAR( ForceArray Array n1 ; ForceArray Array n2 )
Returns: Number
Constraints: COLUMNS(n1) = COLUMNS(n2), ROWS(n1) = ROWS(n2), both sequences shall contain at least one number at corresponding positions each.
Semantics: returns
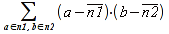
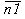
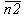
For an empty element or an element of type Text or Boolean in n1 the element at the corresponding position of n2 is ignored, and vice versa.
Summary: Returns the smallest value for which the cumulative binomial distribution is greater than or equal to a criterion value.
Syntax: CRITBINOM( Number Trials ; Number SP ; Number Alpha )
Returns: Number
Constraints: Trials >=0, 0 <= SP <= 1, Alpha >= 1
Semantics:
Trials is the total number of trials.
SP is the probability of success for one trial.
Alpha is the threshold probability to be reached or exceeded.
Summary: Calculates sum of squares of deviations.
Syntax: DEVSQ( { NumberSequence n }+ )
Returns: Number
Semantics: returns
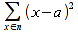
where a is the result of calling AVERAGE(n).
Summary: returns the value of the probability density function or the cumulative distribution function for the exponential distribution.
Syntax: EXPONDIST( Number x ; Number l [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: l > 0
Semantics: If Cumulative is FALSE(), EXPONDIST returns 0 if x < 0 and the value
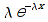
otherwise.
If Cumulative is TRUE(), EXPONDIST returns 0 if x < 0 and the value
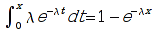
otherwise.
Summary: returns the value of the probability density function or the cumulative distribution function for the F-distribution.
Syntax: FDIST( Number x ; Number r1 ; Number r2 [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: r1 and r2 are positive integers
Semantics:
r1 is the degrees of freedom in the numerator of the F distribution.
r2 is the degrees of freedom in the denominator of the F distribution.
If Cumulative is FALSE(), FDIST returns 0 if x < 0, an Error if the numerator degrees of freedom r1 = 1 and x = 0, and the value
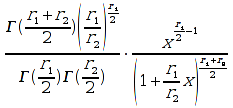
otherwise.
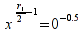
If Cumulative is TRUE(), FDIST returns 0 if x < 0 and the value
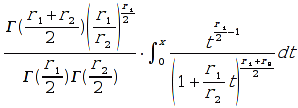
otherwise.
See also LEGACY.FDIST 6.18.23
Summary: returns the area of the right tail of the probability density function for the F-distribution.
Syntax: LEGACY.FDIST( Number x ; Number r1 ; Number r2 )
Returns: Number
Constraints: r1 and r2 are positive integers
Semantics:
LEGACY.FDIST returns Error if x < 0 and the value
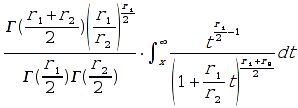
otherwise.
Note that the latter is (1-FDIST(x; r1; r2;TRUE())).
See also FDIST 6.18.22
Summary: returns the inverse of FDIST(x;r1;r2;TRUE()).
Syntax: FINV( Number p ; Number r1 ; Number r2 )
Returns: Number
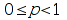
Semantics: FINV returns the unique non-negative number x such that FDIST(x;r1;r2) = p.
See also FDIST 6.18.22, LEGACY.FDIST 6.18.23, LEGACY.FINV 6.18.25
Summary: returns the inverse of LEGACY.FDIST(x;r1;r2).
Syntax: LEGACY.FINV( Number p ; Number r1 ; Number r2 )
Returns: Number
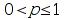
Semantics: LEGACY.FINV returns the unique non-negative number x such that LEGACY.FDIST(x;r1;r2) = p.
See also FDIST 6.18.22, LEGACY.FDIST 6.18.23, FINV 6.18.24
Summary: returns the Fisher transformation.
Syntax: FISHER( Number r )
Returns: Number
Constraints: -1 < r < 1
Semantics: Returns the Fisher transformation with a sample correlation r. This function computes
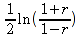
where ln is the natural logarithm function.
FISHER is a synonym for ATANH.
See also ATANH 6.16.11
Summary: returns the inverse Fisher transformation.
Syntax: FISHERINV( Number r )
Returns: Number
Constraints: none
Semantics: Returns the inverse Fisher transformation. This function computes
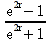
FISHERINV is a synonym for TANH.
See also TANH 6.16.70
Summary: Extrapolates future values based on existing x and y values.
Syntax: FORECAST( Number Value ; ForceArray Array Data_Y ; ForceArray Array Data_X )
Returns: Number
Constraints: COLUMNS(Data_Y) = COLUMNS(Data_X), ROWS(Data_Y) = ROWS(Data_X)
Semantics:
Value is the x-value, for which the y-value on the linear regression is to be returned.
Data_Y is the array or range of known y-values.
Data_X is the array or range of known x-values.
For an empty element or an element of type Text or Boolean in Data_Y the element at the corresponding position of Data_X is ignored, and vice versa.
Summary: Categorizes values into intervals and counts the number of values in each interval.
Syntax: FREQUENCY( NumberSequenceList data ; NumberSequenceList bins )
Returns: Array
Constraints: Values in bins shall be sorted in ascending order and bins shall be a column vector. Evaluators may accept unsorted values in bins.
Semantics: Counts the number of values for each interval given by the border values in bins .
The values in bins determine the upper boundaries of the intervals. The intervals include the upper boundaries. The returned array is a column vector and has one more element than bins ; the last element represents the number of all elements greater than the last value in bins . If bins is empty, all values in data are counted. The values in the result array are ordered matching the original order of bins . If the values in bins are not sorted in ascending order, they are sorted internally to form category intervals and the counts of data values are "unsorted" to the original order of bins. If data is empty, the value of all elements in the returned array is 0.
data The data, that should be categorized and counted according to the given intervals.
bins The upper boundaries determining the intervals the values in data should be grouped by.
Summary: Calculates the probability of an F-test.
Syntax: FTEST( ForceArray NumberSequence Data_1 ; ForceArray NumberSequence Data_2 )
Returns: Number
Constraints: Data_1 and Data_2 shall both contain at least 2 numbers and shall both have nonzero variances
Semantics: Calculates the two-tailed probability that, based on two samples from two normal distributions, these normal distributions have different variances.
Suppose the first sample has size n1 and sample variance s1^2 and the second sample has size n2 and sample variance s2^2. If s1^2>s^2 FDIST returns twice the area of the right tail of the F-distribution with degrees of freedom n1-1,n2-1 beyond s^1/s^2. If s1^2<s^2 FDIST returns twice the area of the left tail of the F-distribution with degrees of freedom n1-1,n2-1 below s^1/s^2.
See also TTEST 6.18.81
Summary: returns the value of the probability density function or the cumulative distribution function for the Gamma distribution.
Syntax: GAMMADIST( Number x ; Number a ; Number [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: a > 0, > 0
Semantics: If Cumulative is FALSE(), GAMMADIST returns 0 if x < 0 and the value
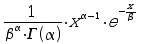
otherwise.
If Cumulative is TRUE(), GAMMADIST returns 0 if x < 0 and the value
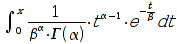
otherwise.
See also GAMMAINV 6.18.32
Summary: returns the inverse of GAMMADIST(x;a;;TRUE()).
Syntax: GAMMAINV( Number p ; Number a ; Number )
Returns: Number
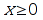
See also GAMMADIST 6.18.31
Summary: Returns 0.5 less than the standard normal cumulative distribution
Syntax: GAUSS( Number x )
Returns: Number
Semantics: Returns NORMDIST(x;0;1;TRUE())-0.5
See also NORMDIST 6.18.52
Summary: returns the geometric mean of a sequence
Syntax: GEOMEAN( { NumberSequenceList N }+ )
Returns: Number
Semantics: Returns the geometric mean of a given sequence. That means
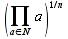
where n is a result of calling COUNT(N).
Summary: Returns predicted values based on an exponential regression.
Syntax: GROWTH( Array knownY [ ; [ Array knownX ] [ ; [ Array newX ] [ ; Logical Const = TRUE() ] ] ] )
Returns: Array
Constraints: (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = 1 and ROWS(knownY) = ROWS(knownX) and COLUMNS(knownX) = COLUMNS(newX)) or (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = 1 and ROWS(knownX) = ROWS(newX))
Semantics:
knownY: The set of known y-values to be used to determine the regression equation
 formula
formula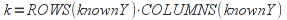 formula
formula formula
formulaConst: If set to FALSE(), the model constant a is equal to 0.
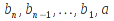 formula
formula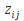 formula
formula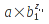 formula
formula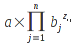 formula
formula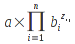 formula
formulaSee also TREND 6.18.79
Summary: returns the harmonic mean of a sequence
Syntax: HARMEAN( { NumberSequenceList N }+ )
Returns: Number
Semantics: Returns the harmonic mean of a given sequence. That means
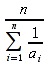
where a1,a2,...,an are the numbers of the sequence N and n is a result of calling COUNT(N).
Summary: The hypergeometric distribution returns the number of successes in a sequence of n draws from a finite population without replacement.
Syntax: HYPGEOMDIST( Integer x ; Integer n ; Integer M ; Integer N [ ; Logical Cumulative = FALSE() ] )
Returns: Number
Constraints: 0 <= x <= n <= N, 0 <= M <= N
Semantics:
x is the number of successes in n trials
n is the number of trials
M is the number of successes in the population
N is the total population
cumulative is a Logical parameter. If cumulative is FALSE(), return the probability of exactly x successes. If cumulative is TRUE(), return the probability of at most x successes. If omitted, FALSE() is assumed.
If Cumulative is FALSE(), HYPGEOMDIST returns
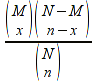
If Cumulative is TRUE(), HYPGEOMDIST returns
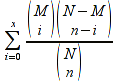
Note:
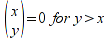
Summary: Returns the y-intercept of the linear regression line for the given data.
Syntax: INTERCEPT( ForceArray Array Data_Y ; ForceArray Array Data_X )
Returns: Number
Constraints: COLUMNS(Data_X) = COLUMNS(Data_Y), ROWS(Data_X) = ROWS(Data_Y)
Semantics:
INTERCEPT returns the intercept (a) calculated as described in 5.18.41 for the function call LINEST(DATA_Y,DATA_X,FALSE()).
For an empty element or an element of type Text or Boolean in Data_Y the element at the corresponding position of Data_X is ignored, and vice versa.
Summary: Return the kurtosis (“peakedness”) of a data set.
Syntax: KURT( { NumberSequenceList X } + )
Returns: Number
Constraints: #Numbers>=4, STDEV(X) <> 0
Semantics:
Kurtosis characterizes the relative peakedness or flatness of a distribution compared with the normal distribution. Positive kurtosis indicates a relatively peaked distribution (compared to the normal distribution), while negative kurtosis indicates a relatively flat distribution.
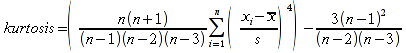
where s is the sample standard deviation, and n is the number of numbers.
Summary: Finds the nth largest value in a list.
Syntax: LARGE( NumberSequenceList List ; Number|Array N )
Returns: Number or Array
Constraints: ROUNDUP(N;0)=N. If the resulting N is <1 or larger than the size of List, Error is returned
Semantics: If N is an array of numbers, an array of largest values is returned.
See also SMALL 6.18.70, ROUNDUP 6.17.7
Summary: Returns the parameters of the (simple or multiple) linear regression equation for the given data and, optionally, statistics on this regression.
Syntax: LINEST( Array knownY [ ; [ Array knownX ] [ ; Logical Const = TRUE() [ ; Logical Stats = FALSE() ] ] ] )
Returns: Array
Constraints: (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = 1 and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = 1)
Semantics:
knownY: The set of y-values for the equation
formulaformulaConst: If set to FALSE(), the model constant a is equal to 0.
Stats: If FALSE(), only the regression coefficient is to be calculated. If set to TRUE(), the result will include other statistical data.
If any of the entries in knownY and knownX do not convert to Number, LINEST returns an error.
The result created by LINEST if STATS is TRUE() is given in Table 28 - LINEST. If STATS is FALSE() it is just the first row of Table 28 - LINEST. The empty cells in this table are returned as empty or as containing an error.
|
bn |
bn-1 |
… |
b1 |
a |
 formula formula |
 formula formula |
… |
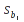 formula formula |
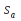 formula formula |
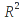 formula formula |
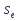 formula formula |
|
|
|
|
F |
df |
|
|
|
|
SSreg |
SSresid |
|
|
|
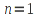 formulaformula
formulaformula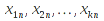 formula
formula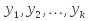 formula
formula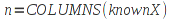 formula
formula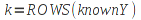 formula
formula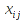 formula
formula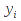 formula
formula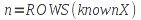 formula
formula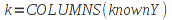 formula
formula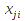 formula
formula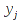 formula
formula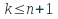 formula
formula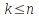 formula
formula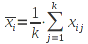 formula
formula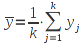 formula
formula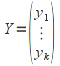 formula
formula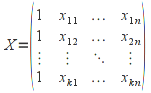 formula
formula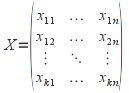 formula
formula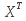 formula
formula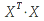 formulaformulaformula
formulaformulaformula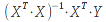 formula
formula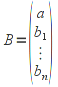 formula
formula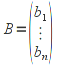 formula
formula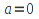 formula
formula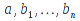 formula
formulaThe statistics in the 2nd to 5th rows of Table 28 - LINEST are as follows:
If Const is TRUE():
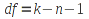 formula
formula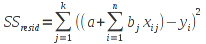 formula
formula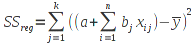 formula
formula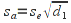 formula
formula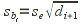 formula
formula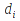 formula
formula formula
formula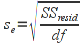 formula
formula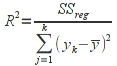 formula
formula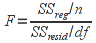 formula
formulaIf Const is FALSE():
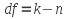 formula
formula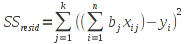 formula
formula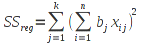 formula
formula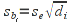 formula
formula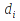 formulaformulaformula
formulaformulaformula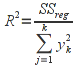 formulaformula
formulaformula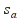 formulaformula
formulaformula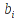 formula
formulaSummary: Returns the parameters of an exponential regression equation for the given data obtained by linearizing this intrinsically linear response function and returns, optionally, statistics on this regression.
Syntax: LOGEST( Array knownY [ ; [ Array knownX ] [ ; Logical Const = TRUE() [ ; Logical Stats = FALSE() ] ] ] )
Returns: Array
Constraints: (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = 1 and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = 1)
Semantics:
knownY: The set of y-values for the equation
formulaformulaConst: If set to FALSE(), the model constant a is equal to 0.
Stats: If FALSE(), only the regression coefficient is to be calculated. If set to TRUE(), the result will include other statistical data.
If any of the entries in knownY and knownX do not convert to Number or if any of the entries in knownY is negative, LOGEST returns an error.
The result created by LOGEST if STATS is TRUE() is given in Table 29 - LOGEST. If STATS is FALSE() it is just the first row of Table 29 - LOGEST. The empty cells in this table are returned as empty or as containing an error.
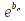 formula formula |
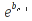 formula formula |
… |
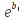 formula formula |
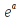 formula formula |
|
formula |
formula |
… |
formula |
formula |
|
formula |
formula |
|
|
|
|
F |
df |
|
|
|
|
SSreg |
SSresid |
|
|
|
formulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformula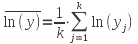 formula
formula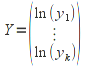 formulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformula
formulaformulaformulaformulaformulaformulaformulaformulaformulaformulaformula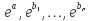 formula
formulaThe statistics in the 2nd to 5th rows of Table 1 - Operators are as follows:
If Const is TRUE():
formula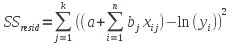 formula
formula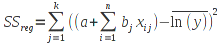 formulaformulaformulaformulaformulaformula
formulaformulaformulaformulaformulaformula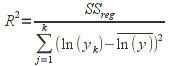 formulaformula
formulaformulaIf Const is FALSE():
formula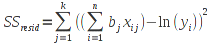 formulaformulaformulaformulaformulaformula
formulaformulaformulaformulaformulaformula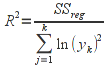 formulaformulaformulaformula
formulaformulaformulaformula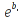 formula
formulaSummary: returns the inverse of LOGNORMDIST(x;Mean;StandardDeviation,TRUE()).
Syntax: LOGINV( Number p [ ; Number Mean = 0 [ ; Number StandardDeviation = 1 ] ] )
Returns: Number
Constraints: StandardDeviation > 0 and 0 < p < 1.
Semantics: LOGINV returns the unique number x such that LOGNORMDIST(x;Mean;StandardDeviation;TRUE()) = p.
See also LOGNORMDIST 6.18.44
Summary: returns the value of the probability density function or the cumulative distribution function for the lognormal distribution with the mean and standard deviation given.
Syntax: LOGNORMDIST( Number x [ ; Number m = 0 [ ; Number s = 1 [ ; Logical Cumulative = TRUE() ] ] ] )
Returns: Number
Constraints: s > 0; x > 0 if Cumulative is FALSE()
Semantics: If Cumulative is FALSE(), LOGNORMDIST returns the value
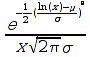
If Cumulative is TRUE(), LOGNORMDIST returns the value
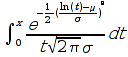
if X > 0 and 0 otherwise.
Summary: Return the maximum from a set of numbers.
Syntax: MAX( { NumberSequenceList N }+ )
Returns: Number
Constraints: None.
Semantics: Returns the value of the maximum number in the list passed in. Non-numbers are ignored. Note that if Logical types are a distinct type, they are not included. What happens when MAX is provided 0 parameters is implementation-defined, but MAX with no parameters should return 0.
See also MAXA 6.18.46, MIN 6.18.48
Summary: Return the maximum from a set of values, including values of type Text and Logical.
Syntax: MAXA( { Any N }+ )
Returns: Number
Constraints: None.
Semantics: A variation of the MAX function that includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included. What happens when MAXA is provided 0 parameters is implementation-defined. Any N may be of type ReferenceList.
See also MAX 6.18.45, MIN 6.18.48, MINA 6.18.49
Summary: Returns the median (middle) value in the list.
Syntax: MEDIAN( { NumberSequenceList X}+ )
Returns: Number
Semantics:
MEDIAN logically ranks the numbers (lowest to highest). If given an odd number of values, MEDIAN returns the middle value. If given an even number of values, MEDIAN returns the arithmetic average of the two middle values.
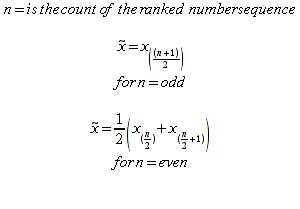
Summary: Return the minimum from a set of numbers.
Syntax: MIN( { NumberSequenceList N }+ )
Returns: Number
Constraints: None.
Semantics: Returns the value of the minimum number in the list passed in. Returns zero if no numbers are provided in the list. What happens when MIN is provided 0 parameters is implementation-defined, but MIN() with no parameters should return 0.
See also MAX 6.18.45, MINA 6.18.49
Summary: Return the minimum from a set of values, including values of type Text and Logical.
Syntax: MINA( { Any N }+ )
Returns: Number
Constraints: None.
Semantics: A variation of the MIN function that includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included. What happens when MINA is provided 0 parameters is implementation-defined. Any N may be of type ReferenceList.
See also MIN 6.18.48, MAXA 6.18.46
Summary: Returns the most common value in a data set.
Syntax: MODE( { ForceArray NumberSequence N }+ )
Semantics: Returns the most common value in a data set. If there are more than one values with the same largest frequency, returns the smallest value. If the number sequence does no contain at least two equal values, the MODE is not defined as no most common value can be found. Therefore an Error message has to be shown.
Summary: Returns the negative binomial distribution.
Syntax: NEGBINOMDIST( Integer x ; Integer r ; Number p )
●x The number of failures.
●r The threshold number of successes.
●p The probability of a success.
Returns: Number
Constraints:
●If (x + r - 1) <= 0 NEGBINOMDIST returns an Error.
●If p < 0 or p > 1 NEGBINOMDIST returns an Error.
Semantics:
NEGBINOMDIST returns the probability that there will be x failures before the r-th success, when the constant probability of a success is p.
Note: This function is similar to the binomial distribution, except that the number of successes is fixed, and the number of trials is variable. Like the binomial, trials are assumed to be independent.
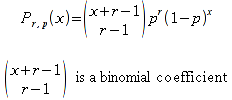
Summary: returns the value of the probability density function or the cumulative distribution function for the normal distribution with the mean and standard deviation given.
Syntax: NORMDIST( Number x ; Number Mean ; Number StandardDeviation [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: StandardDeviation > 0.
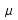
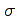
If Cumulative is FALSE(), NORMDIST returns the value
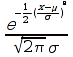
If Cumulative is TRUE(), NORMDIST returns the value
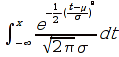
See also LEGACY.NORMSDIST 6.18.54
Summary: returns the inverse of NORMDIST(x;Mean;StandardDeviation,TRUE()).
Syntax: NORMINV( Number p ; Number Mean ; Number StandardDeviation )
Returns: Number
Constraints: StandardDeviation > 0 and 0 < p < 1.
Semantics: NORMINV returns the unique number x such that NORMDIST(x;Mean;StandardDeviation;TRUE()) = p.
See also NORMDIST 6.18.52
Summary: returns the value of the cumulative distribution function for the standard normal distribution.
Syntax: LEGACY.NORMSDIST( Number x )
Returns: Number
Constraints: None
Semantics: LEGACY.NORMSDIST returns the value
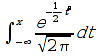
This is exactly NORMDIST(x;0;1;TRUE()).
See also NORMDIST 6.18.52, LEGACY.NORMSINV 6.18.55
Summary: returns the inverse of LEGACY.NORMSDIST(x).
Syntax: LEGACY.NORMSINV( Number p )
Returns: Number
Constraints: 0 < p < 1.
Semantics: LEGACY.NORMSINV returns NORMINV (p).
See also NORMINV 6.18.53, LEGACY.NORMSDIST 6.18.54
Summary: PEARSON returns the Pearson correlation coefficient of two data sets
Syntax: PEARSON( ForceArray Array independent_Values ; ForceArray Array dependent_Values )
Returns: Number
Constraints: COLUMNS(independent_Values) = COLUMNS(dependent_Values), ROWS(independent_Values) = ROWS(dependent_Values), both sequences shall contain at least one number at corresponding positions each.
Semantics:
independent_Values represents the array of the first data set. (X-Values)
dependent_Values represents the array of the second data set. (Y-Values)
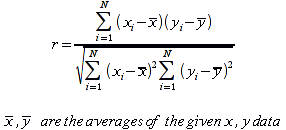
For an empty element or an element of type Text or Boolean in independent_Values the element at the corresponding position of dependent_Values is ignored, and vice versa.
Summary: Calculates the x-th sample percentile among the values in range.
Syntax: PERCENTILE( NumberSequenceList Data ; Number x )
Returns: Number
Constraints:
●COUNT(Data) > 0
●0 <= x <= 1
Semantics:
●Data The array or range of values to get the percentile from.
Returns the x -th sample percentile of data values in Data . A percentile returns the scale value for a data series which goes from the smallest (Alpha=0) to the largest value (Alpha=1) of a data series. For Alpha = 25%, the percentile means the first quartile; Alpha = 50% is the MEDIAN.

See also MAX 6.18.45, MEDIAN 6.18.47, MIN 6.18.48, PERCENTRANK 6.18.58, QUARTILE 6.18.64, RANK 6.18.65
Summary: Returns the percentage rank of a value in a sample.
Syntax: PERCENTRANK( NumberSequenceList Data ; Number X [ ; Integer Significance = 3 ] )
Returns: Number
Constraints:
●COUNT(Data) > 0
●MIN(Data) <= X <= MAX(Data)
●INT(Significance) = Significance; Significance >= 1
Semantics:
●Data is the array or range of data with numeric values.
●X is the value whose rank is to be determined.
●Significance is an optional value that identifies the number of significant digits for the returned percentage value. If omitted, a value of 3 is used (0.xxx).
Returns the rank of a value in a data set Data as a percentage of the data set, a value between 0 and 1, inclusive. This function can be used to evaluate the relative standing of a value within a data set.
For COUNT(Data) > 1, PERCENTRANK returns r / (COUNT(Data) -1), where r is the rank of X in Data. The rank of the lowest number in Data is 0, and of the next lowest number 1, and so on. If X is not in Data, it is assigned a fractional rank proportionately between the rank of the numbers on either side. Specifically, if X lies between Y and Z=Y+1 (Y < X < Z) with Y being the largest number smaller than X and Z the smallest number larger than X, and where Y has rank ry, the rank of X is calculated as
In the special case where COUNT(Data) == 1, the only valid value for X is the single value in Data, in which case PERCENTRANK returns 1.
See also PERCENTILE 6.18.57, RANK 6.18.65
Summary: returns the number of permutations of k objects taken from n objects.
Syntax: PERMUT( Integer n ; Integer k )
Returns: Number
Constraints: n >= 0; k >= 0; n >= k
Semantics: PERMUT returns

respectively
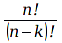
Summary: Returns the number of permutations for a given number of objects (repetition allowed).
Syntax: PERMUTATIONA( Integer Total ; Integer Chosen )
Returns: Number
Constraints: Total >= 0, Chosen >= 0
Semantics: Given Total number of objects, return the number of permutations containing Chosen number of objects, with repetition permitted. The result is 1 if Total = 0 and Chosen = 0, otherwise the result is
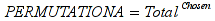
Summary: Returns the values of the density function for a standard normal distribution.
Syntax: PHI( Number N )
Returns: Number
Semantics: PHI(N) is a synonym for NORMDIST(N,0,1,FALSE()).
Summary: returns the probability or the cumulative distribution function for the Poisson distribution
Syntax: POISSON( Integer x ; Number l [ ; Logical Cumulative = TRUE() ] )
Returns: Number
Constraints: l > 0, x >= 0
Semantics: If Cumulative is FALSE(), POISSON returns the value
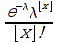
If Cumulative is TRUE(), POISSON returns the value
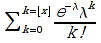
Summary: Returns the probability that a discrete random variable lies between two limits.
Syntax: PROB( ForceArray Array Data ; ForceArray Array Probability ; Number Start [ ; Number End ] )
Returns: Number
Constraints:
●The sum of the probabilities in Probability shall equal 1.
●All values in Probability shall be > 0 and <= 1.
●COUNT(Data) = COUNT(Probability)
Semantics:
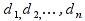
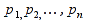
●Start is the start value (lower bound) of the interval whose probabilities are to be summed.
●End (optional) is the end value (upper bound) of the interval whose probabilities are to be summed. If omitted, End = Start is used.
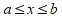
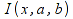
Then PROB returns
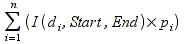
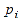
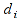
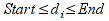

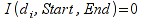
See also
Summary: Returns a quartile of a set of data points.
Syntax: QUARTILE( NumberSequence Data ; Integer Quart )
Returns: Number
Constraints:
●COUNT(Data) > 0
●0 <= Quart <= 4
Semantics:
●Data The cell range or data array of numeric values.
●Quart The number of the quartile to return.
If Quart = 0, the minimum value is returned, which is equivalent to the MIN() function.
If Quart = 1, the value of the 25th percentile is returned.
If Quart = 2, the value of the 50th percentile is returned, which is equivalent to the MEDIAN() function.
If Quart = 3, the value of the 75th percentile is returned.
If Quart = 4, the maximum value is returned, which is equivalent to the MAX() function.
Based on the statistical rank of the data points in Data, QUARTILE returns the percentile value indicated by Quart. The percentile is calculated as Quart divided by 4. An algorithm to calculate the percentile for a set of data points is given in the definition of PERCENTILE.
See also MAX 6.18.45, MEDIAN 6.18.47, MIN 6.18.48, PERCENTILE 6.18.57, PERCENTRANK 6.18.58, RANK 6.18.65
Summary: Returns the rank of a number in a list of numbers.
Syntax: RANK( Number Value ; NumberSequenceList Data [ ; Number Order = 0 ] )
Returns: Number
Constraints: Value shall exist in Data.
Semantics: The RANK function returns the rank of a value within a list.
●Value the number for which to determine the rank.
●Data numbers used to determine the ranking.
●Order specifies how to rank the numbers:
If 0 or omitted, Data is ranked in descending order.
If not 0, Data is ranked in ascending order.
If a number in Data occurs more than once it is given the same rank, but increments the rank for subsequent different numbers. If Value does not exist in Data an Error is returned.
Summary: Returns the square of the Pearson product moment correlation coefficient through data points in known_y's and known_x's.
Syntax: RSQ( ForceArray Array arrayY ; ForceArray Array arrayX )
Returns: Number
Constraints:
The arguments shall be either numbers or names, arrays, or references that contain numbers.
If an array or reference argument contains Text, Logical values, or empty cells, those values are ignored; however, cells with the value zero are included.
If "arrayY" and "arrayX" are empty or have a different number of data points, then #N/A is returned.
COLUMNS(arrayY) = COLUMNS(arrayX), ROWS(arrayY) = ROWS(arrayX)
Semantics: The r-squared value can be interpreted as the proportion of the variance in y attributable to the variance in x.
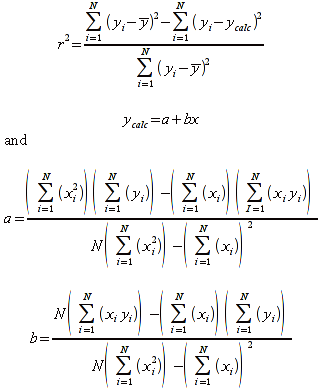
The result of the RSQ function is the same as PEARSON * PEARSON.
For an empty element or an element of type Text or Boolean in arrayY the element at the corresponding position of arrayX is ignored, and vice versa.
See also PEARSON 6.18.56
Summary: Estimates the skewness of a distribution using a sample set of numbers.
Syntax: SKEW( { NumberSequenceList sample }+ )
Returns: Number
Constraints: The sequence shall contain three numbers at least.
Semantics: Estimates the skewness of a distribution using a sample set of numbers.
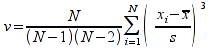
See also SKEWP 6.18.68
Summary: Calculates the skewness of a distribution using the population of a random variable.
Syntax: SKEWP( { NumberSequence population }+ )
Returns: Number
Constraints: The sequence shall contain three numbers at least.
Semantics: Calculates the skewness of a distribution using the population, i.e. the possible outcomes, of a random variable.
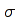
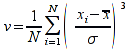
See also SKEW 6.18.67
Summary: Calculates the slope of the linear regression line.
Syntax: SLOPE( ForceArray Array y ; ForceArray Array x )
Returns: Number
Constraints: COLUMNS(y) = COLUMNS(x), ROWS(y) = ROWS(x), both sequences shall contain at least one number at corresponding positions each.
Semantics: Calculates the slope of the linear regression line.
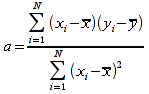
For an empty element or an element of type Text or Boolean in y the element at the corresponding position of x is ignored, and vice versa.
See also INTERCEPT 6.18.38, STEYX 6.18.76
Summary: Finds the nth smallest value in a list.
Syntax: SMALL( NumberSequenceList List ; Integer|Array N )
Returns: Number or Array
Constraints: ROUNDDOWN(N;0)=N, effectively being INT(N)=N for positive numbers. If the resulting N is <1 or larger than the size of List, Error is returned.
Semantics: If N is an array of numbers, an array of smallest values is returned.
See also LARGE 6.18.40, ROUNDDOWN 6.17.6
Summary: Calculates a normalized value of a random variable.
Syntax: STANDARDIZE( Number value ; Number mean ; Number sigma )
Returns: Number
Constraints: sigma > 0
Semantics: Calculates a normalized value of a random variable.
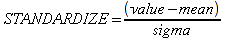
See also GAUSS 6.18.33
Summary: Compute the sample standard deviation of a set of numbers.
Syntax: STDEV( { NumberSequenceList N }+ )
Returns: Number
Constraints: At least two numbers shall be included. Returns an Error if less than two Numbers are provided.
Semantics: Computes the sample standard deviation s, where
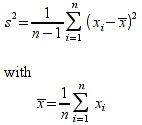
Note that s is not the same as the standard deviation of the set, σ, which uses n rather than n − 1.
See also STDEVP 6.18.74, AVERAGE 6.18.3
Summary: Calculate the standard deviation using a sample set of values, including values of type Text and Logical.
Syntax: STDEVA( { Any sample }+ )
Returns: Number
Constraints: COUNTA(sample) > 1.
Semantics: Unlike the STDEV function, includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included.
The handling of string constants as parameters is implementation-defined. Either, string constants are converted to numbers, if possible and otherwise, they are treated as zero, or string constants are always treated as zero.
Suppose the resulting sequence of values is x1, x2, …, xn. Then let
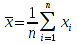
STDEVA returns
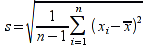
See also STDEV 6.18.72
Summary: Calculates the standard deviation using the population of a random variable, including values of type Text and Logical.
Syntax: STDEVP( { NumberSequence N }+ )
Returns: Number
Constraints: None.
Semantics: Computes the standard deviation of the set σ, where
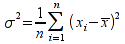
Note that σ is not the same as the sample standard deviation, s, which uses n − 1 rather than n.
See also STDEV 6.18.72, AVERAGE 6.18.3
Summary: Calculates the standard deviation using the population of a random variable, including values of type Text and Logical.
Syntax: STDEVPA( { Any sample }+ )
Returns: Number
Constraints: None.
Semantics: Unlike the STDEV function, includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included.
In the sequence, only Numbers and Logical types are considered; cells with Text are converted to 0; other types are ignored. If Logical types are a distinct type, they are still included, with True considered 1 and False considered 0. Any sample may be of type ReferenceList.
The handling of string constants as parameters is implementation-defined. Either, string constants are converted to numbers, if possible and otherwise, they are treated as zero, or string constants are always treated as zero.
See also STDEVP 6.18.74
Summary: Calculates the standard error of the predicted y value for each x in the regression.
Syntax: STEYX( ForceArray Array measuredY ; ForceArray Array X )
Returns: Number
Constraints: COLUMNS(measuredY) = COLUMNS(X), ROWS(measuredY) = ROWS(X), both sequences shall contain at least three numbers at corresponding positions each.
Semantics: Calculates the standard error of the predicted y value for each x in the regression.
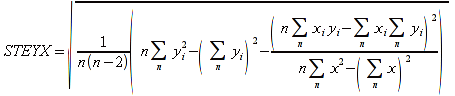
For an empty element or an element of type Text or Boolean in measuredY the element at the corresponding position of X is ignored, and vice versa.
See also INTERCEPT 6.18.38, SLOPE 6.18.69
Summary: Returns the area to the tail or tails of the probability density function of the t-distribution.
Syntax: LEGACY.TDIST( Number x ; Integer df ; Integer tails)
Returns: Number
Constraints: x≥0, df ≥ 1, tails = 1 or 2
Semantics: Then LEGACY.TDIST returns
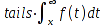
where
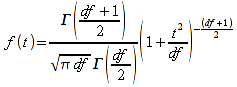
Note that df denotes the degrees of freedom of the t-distribution and Γ is the Gamma function.
See also BETADIST 6.18.7, BINOMDIST 6.18.10, CHISQDIST 6.18.12, EXPONDIST 6.18.21, FDIST 6.18.22, GAMMADIST 6.18.31, GAUSS 6.18.33, HYPGEOMDIST 6.18.37, LOGNORMDIST 6.18.44, NEGBINOMDIST 6.18.51, NORMDIST 6.18.52, POISSON 6.18.62, WEIBULL 6.18.86
Summary: Calculates the inverse of the two-tailed t-distribution.
Syntax: TINV( Number probability ; Integer degreeOfFreedom )
Returns: Number
Constraints: 0 < probability <= 1, degreeOfFreedom >= 1
Semantics: Calculates the inverse of the two-tailed t-distribution.
See also LEGACY.TDIST 6.18.77
Summary: Returns predicted values based on a simple or multiple linear regression.
Syntax: TREND( Array knownY [ ; [ Array knownX ] [ ; [ Array newX ] [ ; Logical Const = TRUE() ] ] ] )
Returns: Array
Constraints: (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = ROWS(knownX)) or (COLUMNS(knownY) = 1 and ROWS(knownY) = ROWS(knownX) and COLUMNS(knownX) = COLUMNS(newX)) or (COLUMNS(knownY) = COLUMNS(knownX) and ROWS(knownY) = 1 and ROWS(knownX) = ROWS(newX))
Semantics:
knownY: The set of known y-values to be used to determine the regression equation
formulaformulaformulaConst: If set to FALSE(), the model constant a is equal to 0.
formulaformula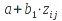 formula
formula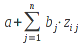 formula
formula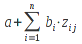 formula
formulaSee also INTERCEPT 6.18.38, SLOPE 6.18.69 , STEYX 6.18.76
Summary: Returns the mean of a data set, ignoring a proportion of high and low values.
Syntax: TRIMMEAN( NumberSequenceList dataSet ; Number cutOffFraction )
Returns: Number
Constraints: 0 ≤ cutOffFraction < 1
Semantics: Returns the mean of a data set, ignoring a proportion of high and low values.
Let n denote the number of elements in the data set and let
be the values in the data set sorted in ascending order. Moreover let
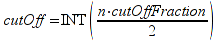
Then TRIMMEAN returns the value
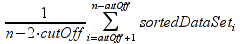
See also AVERAGE 6.18.3 , GEOMEAN 6.18.34 , HARMEAN 6.18.36
Summary: Calculates the p-value of a 2-sample t-test.
Syntax: TTEST( ForceArray Array X ; ForceArray Array Y ; Integer tails ; Integer type )
Returns: Number
Constraints: COUNT(X)>1, COUNT(Y)>1, tails = 1 or 2, type = 1,2, or 3, (COUNT(X)=COUNT(Y) or type ≠1)
COLUMNS(X) = COLUMNS(Y), ROWS(X) = ROWS(Y)
Semantics: Let X1, X2, …,Xn be the numbers in the sequence X and Y1, Y2, …,Ym be the numbers in the sequence Y. Then
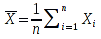
and
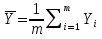
Moreover let
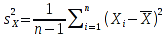
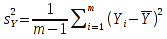
and
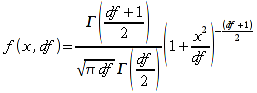
where Γ is the Gamma function.
(1)If type = 1, TTEST calculates the p-value for a paired-sample comparison of means test. Note that in this case due to the above constraints n=m. With
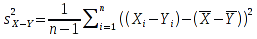
and
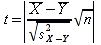
TTEST returns
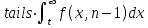
(2)If type = 2, TTEST calculates the p-value of a comparison of means for independent samples from populations with equal variance. With
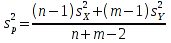
and
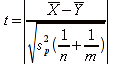
TTEST returns
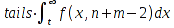
(3)If type = 3, TTEST calculates the p-value of a comparison of means for independent samples from populations with not necessarily equal variances. With
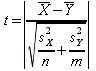
and
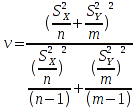
TTEST returns
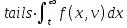
For an empty element or an element of type Text or Boolean in X the element at the corresponding position of Y is ignored, and vice versa.
See also FTEST 6.18.30, LEGACY.TDIST 6.18.77, ZTEST 6.18.87
Summary: Compute the sample variance of a set of numbers.
Syntax: VAR( { NumberSequence N }+ )
Returns: Number
Constraints: At least two numbers shall be included. Returns an Error if less than two Numbers are provided.
Semantics: Computes the sample variance s2, where
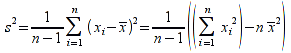
Note that s2 is not the same as the variance of the set, σ2, which uses n rather than n − 1.
See also VARP 6.18.84, STDEV 6.18.72, AVERAGE 6.18.3
Summary: Estimates the variance using a sample set of values, including values of type Text and Logical.
Syntax: VARA( { Any sample }+ )
Returns: Number
Constraints: The sequence shall contain two numbers at least.
Semantics: Unlike the VAR function, includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included.

In the sequence, only Numbers and Logical types are considered; cells with Text are converted to 0; other types are ignored. If Logical types are a distinct type, they are still included, with True considered 1 and False considered 0. Any sample may be of type ReferenceList.
The handling of string constants as parameters is implementation-defined. Either, string constants are converted to numbers, if possible and otherwise, they are treated as zero, or string constants are always treated as zero.
See also VAR 6.18.82
Summary: Compute the variance of the set for a set of numbers.
Syntax: VARP( { NumberSequence N }+ )
Returns: Number
Constraints: COUNT(N)>=1
Semantics: Computes the variance of the set σ2, where
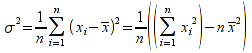
Note that σ2 is not the same as the sample variance, s2, which uses n − 1 rather than n.
If only one number is provided, returns 0.
See also VAR 6.18.82, STDEVP 6.18.74, AVERAGE 6.18.3
Summary: Calculates the variance using the population of the distribution, including values of type Text and Logical.
Syntax: VARPA( { Any sample }+ )
Returns: Number
Constraints: None
Semantics: Unlike the VARP function, includes values of type Text and Logical. Text values are treated as number 0. Logical True is treated as 1, and False is treated as 0. Empty cells are not included.
In the sequence, only Numbers and Logical types are considered; cells with Text are converted to 0; other types are ignored. If Logical types are a distinct type, they are still included, with True considered 1 and False considered 0. Any sample may be of type ReferenceList.
The handling of string constants as parameters is implementation-defined. Either, string constants are converted to numbers, if possible and otherwise, they are treated as zero, or string constants are always treated as zero.
See also VARP 6.18.84
Summary: Calculates the Weibull distribution.
Syntax: WEIBULL( Number value ; Number alpha ; Number beta ; Logical cumulative )
Returns: Number
Constraints: value >= 0; shape > 0; scale > 0
Semantics: Calculates the Weibull distribution at the position value.
If cumulative is false, the probability density function is calculated:
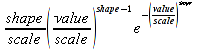
If cumulative is true, the cumulative distribution function is calculated:
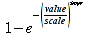
See also BETADIST 6.18.7, BINOMDIST 6.18.10, CHISQDIST 6.18.12, EXPONDIST 6.18.21, FDIST 6.18.22, GAMMADIST 6.18.31, GAUSS 6.18.33, HYPGEOMDIST 6.18.37, LOGNORMDIST 6.18.44, NEGBINOMDIST 6.18.51, NORMDIST 6.18.52, POISSON 6.18.62, LEGACY.TDIST 6.18.77
Summary: Calculates the probability of observing a sample mean as large or larger than the mean of the given sample for samples drawn from a normal distribution.
Syntax: ZTEST( NumberSequenceList sample ; Number mean [ ; Number sigma ] )
Returns: Number
Constraints: The sequence sample shall contain at least two numbers.
Semantics: Calculates the probability of observing a sample mean as large or larger than the mean of the given sample for samples drawn from a normal distribution with the given mean mean and the given standard deviation sigma. If sigma is omitted, it is estimated from sample, using STDEV. With sample being the mean of sample and
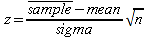
ZTEST returns
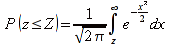
See also FTEST 6.18.30, TTEST 6.18.81
These functions convert between different representations of numbers, such as between different bases and Roman numerals.
The base conversion functions xxx2BIN (such as DEC2BIN), xxx2OCT, and xxx2HEX functions return Text, while the xxx2DEC functions return Number. All of the xxx2yyy functions accept either Text or Number, though a Number is interpreted as the digits when printed in base 10. These are intended to support relatively small numbers, and have a somewhat convoluted interface and semantics, as described in their specifications. General base conversion capabilities are provided by BASE and DECIMAL.
As an argument for the HEX2xxx functions, a hexadecimal number is any string consisting solely of the characters "0","1" to "9", "a" to "f" and "A" to "F". The hexadecimal output of an xxx2HEX function shall be a string consisting solely of the characters "0","1" to "9" (U+0030 through U+0039), "a" to "f" (U+0061 through U+0066) and "A" to "F" (U+0041 through U+0046), and should be a string consisting solely of the characters "0","1" to "9" and "A" to "F". In both cases, the 40th bit (from the right) is considered a sign bit.
Summary: Convert Roman numerals to Number.
Syntax: ARABIC( Text X )
Returns: Number
Constraints: X shall contain Roman numerals, or an empty string.
Semantics: Converts the Roman numeral to Number. This is the reverse of ROMAN; see ROMAN for the values of individual Roman numeral symbols. A Roman symbol to the left of a larger symbol (directly or indirectly) reduces the final value by the symbol amount, otherwise, it increases the final amount by the symbol's amount. Case is ignored.
The characters accepted are U+004D "M", U+0044 "D", U+0043 "C", U+004C "L", U+0058 "X", U+0056 "V", U+0049 "I", U+006D "m", U+0064 "d", U+0063 "c", U+006C "l", U+0078 "x", U+0076 "v", U+0069 "i" .
The following identity shall hold: ARABIC(ROMAN(x; any)) = x, when ROMAN(x; any) is not an Error.
If X is an empty string, 0 is returned.
See also Infix Operator "&" 6.4.10, ROMAN 6.19.17
Summary: Converts a number into a text representation with the given base.
Syntax: BASE( Integer X ; Integer Radix [ ; Integer MinimumLength ] )
Returns: Text
Constraints: X ≥ 0, 2 ≤ Radix ≤ 36, MinimumLength ≥ 0
Semantics: Converts number X into text that represents the value of X in base Radix. The symbols 0-9 (U+0030 through U+0039), then upper case A-Z (U+0041 through U+005A) are used as digits. Thus, BASE(45745;36) returns “ZAP”.
If MinimumLength is not supplied, the generated text uses the smallest number of characters (i.e., it does not add leading 0s). If MinimumLength is supplied, and the resulting text would normally be smaller than MinimumLength, leading 0s are added to produce text exactly MinimumLength characters long. If the text is longer than the MinimumLength argument, the MinimumLength parameter is ignored.
See also DECIMAL 6.19.10
Summary: Converts a binary (base 2) number (up to 10 digits) to its decimal equivalent
Syntax: BIN2DEC( TextOrNumber X )
Returns: Number
Constraints: X shall contain only binary digits (no space or other characters), and shall contain at least one binary digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where the digits in X are only 0 or 1, no more than 10 digits.
Semantics: Converts given binary number into decimal equivalent, with the topmost 10th digit being the sign bit (using a two's complement representation). If given Text, the text is considered a binary number representation. If given a Number, the digits of the number when printed as base 10 are considered the digits of the equivalently-represented binary number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
If any digits are 2 through 9, an evaluator shall return an Error. It is implementation-defined what happens if an evaluator is given an empty string; evaluators may return an Error or 0 in such cases.
Summary: Converts a binary (base 2) number (10th bit is sign) to its hexadecimal equivalent
Syntax: BIN2HEX( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only binary digits (no space or other characters), and shall contain at least one binary digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where the digits in X are only 0 or 1, no more than 10 digits.
Semantics: Converts given binary number into hexadecimal (base 16) equivalent. For input value X, the topmost 10th digit is considered the sign bit (using a two's complement representation). If given Text, the text is considered a binary number representation. If given a Number, the digits of the number when printed as base 10 are considered the digits of the equivalently-represented binary number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
If any digits in X are 2 through 9, an evaluator shall return an Error. It is implementation-defined what happens if an evaluator is given an empty string; evaluators may return an Error or 0 in such cases.
The resulting value is a hexadecimal value, up to 10 hexadecimal digits, with the topmost bit (40th bit) being the sign bit and in two's complement form. The digits A through F are in uppercase. If the input has its 10th bit on, the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits required than the Digits parameter specifies, the results are implementation-defined.
Summary: Converts a binary (base 2) number (10th bit is sign) to its octal (base 8) equivalent
Syntax: BIN2OCT( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only binary digits (no space or other characters), and shall contain at least one binary digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where the digits in X are only 0 or 1, no more than 10 digits.
Semantics: Converts given binary number into octal (base 8) equivalent. For input value X, the topmost 10th digit is considered the sign bit (using a two's complement representation). If given Text, the text is considered a binary number representation. If given a Number, the digits of the number when printed as base 10 are considered the digits of the equivalently-represented binary number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
If any digits in X are 2 through 9, an evaluator shall return an Error. It is implementation-defined what happens if an evaluator is given an empty string; evaluators may return an Error or 0 in such cases.
The resulting value is an octal value, up to 10 octal digits, with the topmost bit (30th bit) being the sign bit and in two's complement form. If the input has its 10th bit on, the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, its results are implementation-defined.
Summary: Converts a decimal number to base 2 (whose 10th bit is sign)
Syntax: DEC2BIN( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only decimal digits (no space or other characters), and shall contain at least one decimal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where -512 <= X <= 511.
Semantics: Converts given number into binary (base 2) equivalent. If given Text, the text is considered a decimal number representation, and may have a leading minus sign. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a binary value, up to 10 digits, with the topmost bit (10th bit) being the sign bit and in two's complement form. If the input is negative, the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Summary: Converts a decimal number to base 16 (whose 40th bit is sign)
Syntax: DEC2HEX( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only decimal digits (no space or other characters), and shall contain at least one decimal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where -239<= X <= 239-1.
Semantics: Converts given number into hexadecimal (base 16) equivalent. If given Text, the text is considered a decimal number representation, and may have a leading minus sign. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a hexadecimal value, up to 10 digits, with the topmost bit (40th bit) being the sign bit and in two's complement form. If the input is negative, the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Summary: Converts a decimal number to base 8 (whose 30th bit is sign)
Syntax: DEC2OCT( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only decimal digits (no space or other characters), and shall contain at least one decimal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where -229<= X <= 229-1.
Semantics: Converts given number into octal (base 8) equivalent. If given Text, the text is considered a decimal number representation, and may have a leading minus sign. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a octal value, up to 10 digits, with the topmost bit (30th bit) being the sign bit and in two's complement form. If the input is negative, the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
See also OCT2DEC
Summary: Converts text representing a number in a given base into a base 10 number.
Syntax: DECIMAL( Text X ; Integer Radix )
Returns: Number
Constraints: 2 ≤ Radix ≤ 36
Semantics: Converts text X in base Radix to a Number. Uppercase letters (U+0041 through U+005A) and lowercase letters (U+0061 through U+007A) are both accepted as equivalent if Radix > 10. Thus, DECIMAL("zap";36) and DECIMAL("ZAP";36) both compute 45745.
An Error is returned if X has characters that do not belong in base Radix. However, leading spaces and tabs in X are always ignored. If Radix is 16, a leading regular expression “0?[Xx]” is ignored, as is a trailing letter H or h. If Radix is 2, the letter b or B at the end is ignored (if present).
See also BASE 6.19.3
Summary: Converts a hexadecimal number (40th bit is sign) to base 2 (whose 10th bit is sign)
Syntax: HEX2BIN( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only hexadecimal digits (no space or other characters), and shall contain at least one hexadecimal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where X is considered in base 10, -512 <= X <= 511.
Semantics: Converts given hexadecimal number into binary (base 2) equivalent. If given Text, the text is considered a hexadecimal number representation; if its 40th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a binary value, up to 10 digits, with the topmost bit (10th bit) being the sign bit and in two's complement form. If the input is negative (40th bit is 1), the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Summary: Converts a hexadecimal number (40th bit is sign) to decimal
Syntax: HEX2DEC( TextOrNumber X )
Returns: Number
Constraints: X shall contain only hexadecimal digits (no space or other characters), and shall contain at least one hexadecimal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where X shall have 1 though 10 (inclusive) hexadecimal digits.
Semantics: Converts given hexadecimal number into decimal equivalent. If given Text, the text is considered a hexadecimal number representation. If X's 40th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a decimal number.
Summary: Converts a hexadecimal number (40th bit is sign) to base 8 (whose 30th bit is sign)
Syntax: HEX2OCT( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain hexadecimal digits (no spaces or other characters), and shall contain at least one hexadecimal digit. When considered as Number, INT(X)=X. Evaluators may evaluate expressions where X has 1 to 10 (inclusive) hexadecimal digits, base 10 value of X is -2 29 < X < 2 29 -1.
Semantics: Converts given hexadecimal number into octal (base 8) equivalent. If given Text, the text is considered a hexadecimal number representation; if its 40th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is an octal value, up to 10 digits, with the topmost bit (10th bit) being the sign bit and in two's complement form. If the input is negative (40th bit is 1), the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Summary: Converts an octal number (30th bit is sign) to base 2 (whose 10th bit is sign)
Syntax: OCT2BIN( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only octal digits (no space or other characters), and shall contain at least one octal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where X is considered in base 10, -512 <= X <= 511.
Semantics: Converts given octal (base 8) number into binary (base 2) equivalent. If given Text, the text is considered an octal number representation; if its 30th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a binary value, up to 10 digits, with the topmost bit (10th bit) being the sign bit and in two's complement form. If the input is negative (30th bit is 1), the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Syntax: OCT2DEC( TextOrNumber X )
Summary: Converts an octal number (30th bit is sign) to decimal
Returns: Number
Constraints: X shall contain only octal digits (no space or other characters), and shall contain at least one octal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where X shall have 1 though 10 (inclusive) octal digits.
Semantics: Converts given octal number into decimal equivalent. If given Text, the text is considered a octal number representation. If X's 30th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a decimal number.
Summary: Converts an octal number (30th bit is sign) to hexadecimal (whose 40th bit is sign)
Syntax: OCT2HEX( TextOrNumber X [ ; Number Digits ] )
Returns: Text
Constraints: X shall contain only octal digits (no space or other characters), and shall contain at least one octal digit. When considered as a Number, INT(X)=X. Evaluators may evaluate expressions where X shall have 1 to 10 (inclusive) octal digits.
Semantics: Converts given octal (base 8) number into hexadecimal (base 16) equivalent. If given Text, the text is considered an octal number representation; if its 30th bit is 1, it is considered a negative number. It is implementation-defined what happens if given a Logical value; an evaluator may produce an Error, or it may convert the Logical to Number (per “Convert to Number”) and then process as a Number.
The resulting value is a hexadecimal value, up to 10 digits, with the topmost bit (40th bit) being the sign bit and in two's complement form. If the input is negative (30th bit is 1), the Digits argument is ignored; otherwise, the Digits indicates the number of digits in the output, with leading 0 digits added as necessary to bring it up to that number of digits. If there are more digits than specified by the Digits parameter, the results are implementation-defined.
Summary: Convert to Roman numerals
Syntax: ROMAN( Integer N [ ; Integer Format = 0 ] )
Returns: Text
Constraints: N>=0, N<4000, 0 <= Format <= 4, ISLOGICAL(1) or NOT(ISLOGICAL(Format))
Semantics: Return the Roman numeral representation of N. “Format” specifies the level of conciseness, and defaults to 0, the classic representation, with larger numbers requiring increasing conciseness.
To supcport legacy documents, evaluators with Logical types that are distinct from Number may accept the format parameter as a scalar, and accept TRUE() specifying format 0, and FALSE() specifying format 4.
The following identity shall hold: ARABIC(ROMAN(x; any)) = x, when ROMAN(x; any) is not an Error.
If N is 0, an empty string is returned.
Table 30 - ROMAN lists the values of individual roman numerals; roman numerals that precede (directly or indirectly) a larger-valued roman number subtract their value from the final value.
|
Roman Numeral |
Value |
Unicode Code Point |
|
I |
1 |
U+0049 |
|
V |
5 |
U+0056 |
|
X |
10 |
U+0058 |
|
L |
50 |
U+004C |
|
C |
100 |
U+0043 |
|
D |
500 |
U+0044 |
|
M |
1000 |
U+004D |
Evaluators that accept 0 as a value of N should return the string “0”. Evaluators that accept negative values of N should include a negative sign (“-”) as the first character.
The Format levels are:
|
Format |
Meaning |
|
0 |
Only subtract powers of 10, not L or V, and only if the next number is not more than 10 times greater. A number following the larger one shall be smaller than the subtracted number. Also known as classic. |
|
1 |
Powers of 10, and L and V may be subtracted, only if the next number is not more than 10 times greater. A number following the larger one shall be smaller than the subtracted number. |
|
2 |
Powers of 10 and L, but not V, may be subtracted, also if the next number is more than 10 times greater. A number following the larger one shall be smaller than the subtracted number. |
|
3 |
Powers of 10, and L and V may be subtracted, also if the next number is more than 10 times greater. A number following the larger one shall be smaller than the subtracted number. |
|
4 |
Produce the fewest Roman digits possible. Also known as simplified. |
See also Infix Operator "&" 6.4.10, ARABIC 6.19.2
Summary: Converts full-width to half-width ASCII and katakana characters.
Syntax: ASC( Text T )
Returns: Text
Constraints: None
Semantics: Conversion is done for full-width ASCII and [UNICODE] katakana characters, some characters are converted in a special way, see table below. Other characters are copied from T to the result. This is the complementary function to JIS.
The percent sign % in the conversion table below denotes the modulo operation. A followed by means that a character is converted to two consecutive characters.
|
From Unicode Character (c) |
To Unicode Character |
Comment |
|
U+30a1 <= c <= U+30aa |
(c - 0x30a2) / 2 + 0xff71 |
katakana a-o |
|
U+30a1 <= c <= U+30aa |
(c - 0x30a1) / 2 + 0xff67 |
katakana small a-o |
|
U+30ab <= c <= U+30c2 |
(c - 0x30ab) / 2 + 0xff76 |
katakana ka-chi |
|
U+30ab <= c <= U+30c2 |
(c - 0x30ac) / 2 + 0xff76 |
katakana ga-dhi |
|
U+30c3 |
0xff6f |
katakana small tsu |
|
U+30c4 <= c <= U+30c9 |
(c - 0x30c4) / 2 + 0xff82 |
katakana tsu-to |
|
U+30c4 <= c <= U+30c9 |
(c - 0x30c5) / 2 + 0xff82 |
katakana du-do |
|
U+30ca <= c <= U+30ce |
c - 0x30ca + 0xff85 |
katakana na-no |
|
U+30cf <= c <= U+30dd |
(c - 0x30cf) / 3 + 0xff8a |
katakana ha-ho |
|
U+30cf <= c <= U+30dd |
(c - 0x30d0) / 3 + 0xff8a |
katakana ba-bo |
|
U+30cf <= c <= U+30dd |
(c - 0x30d1) / 3 + 0xff8a |
katakana pa-po |
|
U+30de <= c <= U+30e2 |
c - 0x30de + 0xff8f |
katakana ma-mo |
|
U+30e3 <= c <= U+30e8 |
(c - 0x30e4) / 2 + 0xff94) |
katakana ya-yo |
|
U+30e3 <= c <= U+30e8 |
(c - 0x30e3) / 2 + 0xff6c |
katakana small ya-yo |
|
U+30e9 <= c <= U+30ed |
c - 0x30e9 + 0xff97 |
katakana ra-ro |
|
U+30ef |
U+ff9c |
katakana wa |
|
U+30f2 |
U+ff66 |
katakana wo |
|
U+30f3 |
U+ff9d |
katakana nn |
|
U+ff01 <= c <= U+ff5e |
c - 0xff01 + 0x0021 |
ASCII characters |
|
U+2015 |
U+ff70 |
HORIZONTAL BAR => HALFWIDTH KATAKANA-HIRAGANA PROLONGED SOUND MARK |
|
U+2018 |
U+0060 |
LEFT SINGLE QUOTATION MARK => GRAVE ACCENT |
|
U+2019 |
U+0027 |
RIGHT SINGLE QUOTATION MARK => APOSTROPHE |
|
U+201d |
U+0022 |
RIGHT DOUBLE QUOTATION MARK => QUOTATION MARK |
|
U+3001 |
U+ff64 |
IDEOGRAPHIC COMMA |
|
U+3002 |
U+ff61 |
IDEOGRAPHIC FULL STOP |
|
U+300c |
U+ff62 |
LEFT CORNER BRACKET |
|
U+300d |
U+ff63 |
RIGHT CORNER BRACKET |
|
U+309b |
U+ff9e |
KATAKANA-HIRAGANA VOICED SOUND MARK |
|
U+309c |
U+ff9f |
KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK |
|
U+30fb |
U+ff65 |
KATAKANA MIDDLE DOT |
|
U+30fc |
U+ff70 |
KATAKANA-HIRAGANA PROLONGED SOUND MARK |
|
U+ffe5 |
U+005c |
FULLWIDTH YEN SIGN => REVERSE SOLIDUS "\" |
|
Note 1: The "\" (REVERSE SOLIDUS, U+005C) is a specialty that gets displayed as a Yen sign with some Japanese fonts, which is a legacy of code-page 932. | ||
Note 2: For references regarding halfwidth and fullwidth characters see [UAX11] and the Halfwidth and Fullwidth Code Chart of [UNICODE].
Note 3: For information about the mapping of JIS X 0201 and JIS X 0208 to Unicode characters see [JISX0201] and [JISX0208].
See also JIS 6.20.11
Summary: Return character represented by the given numeric value
Syntax: CHAR( Number N )
Returns: Text
Constraints: N <= 127; Evaluators may evaluate expressions where N >= 1, N <= 255.
Semantics:
Returns character represented by the given numeric value.
Evaluators should return an Error if N > 255.
Evaluators should implement CHAR such that CODE(CHAR(N)) returns N for any 1 <= N <= 255.
Note 1: Beyond 127, some evaluators return a character from a system-specific code page, while others return the [UNICODE] character. Most evaluators do not allow values greater than 255.
Note 2: Where interoperability is a concern, expressions should use the UNICHAR function. 6.20.25
See also CODE 6.20.5, UNICHAR 6.20.25, UNICODE 6.20.26
Summary: Remove all non-printable characters from the string and return the result.
Syntax: CLEAN( Text T )
Returns: Text
Semantics:
Removes all non-printable characters from the string T and returns the resulting string. Evaluators should remove each particular character from the string, if and only if the character belongs to [UNICODE] class Cc (Other - Control), or to Unicode class Cn (Other - Not Assigned). The resulting string shall contain all printable characters from the original string, in the same order. The space character is considered a printable character.
Summary: Return numeric value corresponding to the first character of the text value.
Syntax: CODE( Text T )
Returns: Number
Constraints: code point <= 127 (ASCII).; Evaluators may evaluate expressions where Length(T) > 0.
Semantics:
Returns a numeric value which represents the first letter of the given text T.
Behavior for code points >= 128 is implementation-defined. Evaluators may use the underlying system's code page. Evaluators should implement CODE such that CODE(CHAR(N)) returns N for 1 <= N <= 255.
Note: Where interoperability is a concern, expressions should use the UNICODE function. 6.20.26
See also CHAR 6.20.3, UNICHAR 6.20.25, UNICODE 6.20.26
Summary: Concatenate the text strings
Syntax: CONCATENATE( { Text T }+ )
Returns: Text
Constraints: None
Semantics: Concatenate each text value, in order, into a single text result.
See also Infix Operator "&" 6.4.10
Summary: Convert the parameters to Text formatted as currency.
Syntax: DOLLAR( Number N [ ; Integer D ] )
Returns: Text
Constraints: None
Semantics: Returns the value formatted as a currency, using locale-specific data. D is the number of decimal places used in the result string, a negative D rounds number N. If D is omitted, locale information may be used to determine the currency's decimal places, or a value of 2 shall be assumed.
Summary: Report if two text values are equal using a case-sensitive comparison .
Syntax: EXACT( Text t1 ; Text t2 )
Returns: Logical
Constraints: None
Semantics: Converts both sides to Text, and then returns TRUE if the two text values are equal, including case, otherwise it returns FALSE.
See also FIND 6.20.9, SEARCH 6.20.20, Infix Operator "<>" 6.4.8, Infix Operator "=" 6.4.7
Summary: Return the starting position of a given text.
Syntax: FIND( Text Search ; Text T [ ; Integer Start = 1 ] )
Returns: Number
Constraints: Start >= 1
Semantics: Returns the character position where Search is first found in T, when the search is started from character position Start. The match is case-sensitive, and no wildcards or other instructions are considered in Search. Returns an Error if text not found.
See also EXACT 6.20.8, SEARCH 6.20.20
Summary: Round the number to a specified number of decimals and format the result as a text.
Syntax: FIXED( Number N [ ; Integer D = 2 [ ; Logical OmitSeparators = FALSE() ] ] )
Returns: Text
Constraints: None
Semantics: Rounds value N to D decimal places (after the decimal point) and returns the result formatted as text, using locale-specific settings. If D is negative, the number is rounded to ABS(D) places to the left from the decimal point. If the optional parameter OmitSeparators is True, then group separators are omitted from the resulting string. Group separators are included in the absence of this parameter. If D is a fraction, it is rounded towards 0 as an integer (ignoring what is the closest integer).
Summary: Converts half-width to full-width ASCII and katakana characters.
Syntax: JIS( Text T )
Returns: Text
Constraints: None
Semantics: Conversion is done for half-width ASCII and [UNICODE] katakana characters, some characters are converted in a special way, see table below. Other characters are copied from T to the result. This is the complementary function to ASC.
A followed by means that there are two consecutive characters to convert from.
|
From Unicode Character (c) |
To Unicode Character |
Comment |
|
U+0022 |
0x201d |
QUOTATION MARK => RIGHT DOUBLE QUOTATION MARK |
|
U+005c |
0xffe5 |
REVERSE SOLIDUS "\" => FULLWIDTH YEN SIGN |
|
U+0060 |
0x2018 |
GRAVE ACCENT => LEFT SINGLE QUOTATION MARK |
|
U+0027 |
0x2019 |
APOSTROPHE => RIGHT SINGLE QUOTATION MARK |
|
U+0021 <= c <= U+007e |
c - 0x0021 + 0xff01 |
ASCII characters |
|
U+ff66 |
0x30f2 |
katakana wo |
|
U+ff67 <= c <= U+ff6b |
(c - 0xff67) * 2 + 0x30a1 |
katakana small a-o |
|
U+ff6c <= c <= U+ff6e |
(c - 0xff6c) * 2 + 0x30e3 |
katakana small ya-yo |
|
U+ff6f |
0x30c3 |
katakana small tsu |
|
U+ff71 <= c <= U+ff75 |
(c - 0xff71) * 2 + 0x30a2 |
katakana a-o |
|
U+ff76 <= c <= U+ff81 |
(c - 0xff76) * 2 + 0x30ac |
katakana ga-dsu |
|
U+ff76 <= c <= U+ff81 |
(c - 0xff76) * 2 + 0x30ab |
katakana ka-chi |
|
U+ff82 <= c <= U+ff84 |
(c - 0xff82) * 2 + 0x30c5 |
katakana du-do |
|
U+ff82 <= c <= U+ff84 |
(c - 0xff82) * 2 + 0x30c4 |
katakana tsu-to |
|
U+ff85 <= c <= U+ff89 |
c - 0xff85 + 0x30ca |
katakana na-no |
|
U+ff8a <= c <= U+ff8e |
(c - 0xff8a) * 3 + 0x30d0 |
katakana ba-bo |
|
U+ff8a <= c <= U+ff8e |
(c - 0xff8a) * 3 + 0x30d1 |
katakana pa-po |
|
U+ff8a <= c <= U+ff8e |
(c - 0xff8a) * 3 + 0x30cf |
katakana ha-ho |
|
U+ff8f <= c <= U+ff93 |
c - 0xff8f + 0x30de |
katakana ma-mo |
|
U+ff94 <= c <= U+ff96 |
(c - 0xff94) * 2 + 0x30e4 |
katakana ya-yo |
|
U+ff97 <= c <= U+ff9b |
c - 0xff97 + 0x30e9 |
katakana ra-ro |
|
U+ff9c |
U+30ef |
katakana wa |
|
U+ff9d |
U+30f3 |
katakana nn |
|
U+ff9e |
U+309b |
HALFWIDTH KATAKANA VOICED SOUND MARK => FULLWIDTH |
|
U+ff9f |
U+309c |
HALFWIDTH KATAKANA SEMI-VOICED SOUND MARK => FULLWIDTH |
|
U+ff70 |
U+30fc |
HALFWIDTH KATAKANA-HIRAGANA PROLONGED SOUND MARK => FULLWIDTH |
|
U+ff61 |
U+3002 |
HALFWIDTH IDEOGRAPHIC FULL STOP => FULLWIDTH |
|
U+ff62 |
U+300c |
HALFWIDTH LEFT CORNER BRACKET => FULLWIDTH |
|
U+ff63 |
U+300d |
HALFWIDTH RIGHT CORNER BRACKET => FULLWIDTH |
|
U+ff64 |
U+3001 |
HALFWIDTH IDEOGRAPHIC COMMA => FULLWIDTH |
|
U+ff65 |
U+30fb |
HALFWIDTH KATAKANA MIDDLE DOT => FULLWIDTH |
Note 1: For references regarding halfwidth and fullwidth characters see [UAX11] and the Halfwidth and Fullwidth Code Chart of [UNICODE].
Note 2: For information about the mapping of JIS X 0201 and JIS X 0208 to Unicode characters see [JISX0201] and [JISX0208].
See also ASC 6.20.2
Summary: Return a selected number of text characters from the left.
Syntax: LEFT( Text T [ ; Integer Length ] )
Returns: Text
Constraints: Length >= 0
Semantics: Returns the INT(Length) number of characters of text T, starting from the left. If Length is omitted, it defaults to 1; otherwise, it computes Length=INT(Length). If T has fewer than Length characters, it returns T. This means that if T is an empty string (which has length 0) or the parameter Length is 0, LEFT() will always return an empty string. Note that if Length<0, an Error is returned. This function shall return the same string as MID(T; 1; Length).
The results of this function may be normalization-sensitive. 4.2
See also LEN 6.20.13, MID 6.20.15, RIGHT 6.20.19
Summary: Return the length, in characters, of given text
Syntax: LEN( Text T )
Returns: Integer
Constraints: None.
Semantics: Computes number of characters (not the number of bytes) in T. If T is of type Number, it is automatically converted to Text, including a fractional part and decimal separator if necessary.
The results of this function may be normalization-sensitive. 4.2
See also TEXT 6.20.23, ISTEXT 6.13.25, LEFT 6.20.12, MID 6.20.15, RIGHT 6.20.19
Summary: Return input string, but with all uppercase letters converted to lowercase letters.
Syntax: LOWER( Text T )
Returns: Text
Constraints: None
Semantics: Return input string, but with all uppercase letters converted to lowercase letters, as defined by sections 3.13 Default Case Algorithms, 4.2 Case-Normative and 5.18 Case Mappings of [UNICODE]. As with most functions, it is side-effect free (it does not modify the source values). All Evaluators shall convert A-Z to a-z.
Note: As this function can be locale aware, results may be unexpected in certain cases. For example in a Turkish locale an upper case "I without dot" (LATIN CAPITAL LETTER I, U+0049) is converted to a lower case "i without dot" (LATIN SMALL LETTER DOTLESS I, U+0131).
See also UPPER 6.20.27, PROPER 6.20.16
Summary: Returns extracted text, given an original text, starting position, and length.
Syntax: MID( Text T ; Integer Start ; Integer Length )
Returns: Text
Constraints: Start >= 1, Length >= 0.
Semantics: Returns the characters from T, starting at character position Start, for up to Length characters. For the integer conversions, Start=INT(Start), and Length=INT(Length). If there are less than Length characters starting at start, it returns as many characters as it can beginning with Start. In particular, if Start > LEN(T), it returns the empty string (""). If Start < 0, it returns an Error. If Start >=0, and Length=0, it returns the empty string. Note that MID(T;1;Length) produces the same results as LEFT(T;Length).
The results of this function may be normalization-sensitive. 4.2
See also LEFT 6.20.12, LEN 6.20.13, RIGHT 6.20.19, REPLACE 6.20.17, SUBSTITUTE 6.20.21
Summary: Return the input string with the first letter of each word converted to an uppercase letter and the rest of the letters in the word converted to lowercase.
Syntax: PROPER( Text T )
Returns: Text
Constraints: None
Semantics: Return input string, but modified as follows:
●.If the first character is a letter, it is converted to its uppercase equivalent; otherwise, the original character is returned
●.If a letter is preceded by a non-letter, it is converted to its uppercase equivalent
●.If a letter is preceded by a letter, it is converted to its lowercase equivalent.
Evaluators shall implement this for at least the Latin letters A-Z and a-z.
As with most functions, it is side-effect free, that is, it does not modify the source values.
See also LOWER 6.20.14, UPPER 6.20.27
Summary: Returns text where an old text is substituted with a new text.
Syntax: REPLACE( Text T ; Number Start ; Number Count ; Text New )
Returns: Text
Constraints: Start >= 1.
Semantics: Returns text T, but remove the characters starting at character position Start for Count characters, and instead replace them with New. Character positions defined by Start begin at 1 (for the leftmost character). If Count=0, the text New is inserted before character position Start, and all the text before and after Start is retained. If Start > length of text T (TLen) then Start is set to TLen. If Count > TLen - Start then Count is set to TLen - Start.
REPLACE(T;Start;Len;New) is the same as LEFT(T;Start-1) & New & MID(T; Start+Len; LEN(T)))
See also LEFT 6.20.12, LEN 6.20.13, MID 6.20.15, RIGHT 6.20.19, SUBSTITUTE 6.20.21
Summary: Return text repeated Count times.
Syntax: T( Text T ; Integer Count )
Returns: Text
Constraints: Count >= 0
Semantics: Returns text T repeated Count number of times; if Count is zero, an empty string is returned. If Count < 0, the result is Error.
See also LEFT 6.20.12, MID 6.20.15, RIGHT 6.20.19, SUBSTITUTE 6.20.21
Summary: Return a selected number of text characters from the right.
Syntax: RIGHT( Text T [ ; Integer Length ] )
Returns: Text
Constraints: Length >= 0
Semantics: Returns the Length number of characters of text T, starting from the right. If Length is omitted, it defaults to 1; otherwise, it computes Length=INT(Length). If T has fewer than Length characters, it returns T (unchanged). This means that if T is an empty string (which has length 0) or the parameter Length is 0, RIGHT() will always return an empty string. Note that if Length<0, an Error is returned.
The results of this function may be normalization-sensitive. 4.2
See also LEFT 6.20.12, LEN 6.20.13, MID 6.20.15
Summary: Return the starting position of a given text.
Syntax: SEARCH( Text Search ; Text T [ ; Integer Start = 1 ] )
Returns: Integer
Constraints: Start >= 1
Semantics: Returns the character position where Search is first found in T, when the search is started from character position Start. The match is not case-sensitive. Start is 1 if omitted. Returns an Error if text not found.
The values returned may vary depending upon the HOST-USE-REGULAR-EXPRESSIONS or HOST-USE-WILDCARDS properties. 3.4
See also EXACT 6.20.8, FIND 6.20.9
Summary: Returns text where an old text is substituted with a new text.
Syntax: SUBSTITUTE( Text T ; Text Old ; Text New [ ; Integer Which ] )
Returns: Text
Constraints: Which >= 1 (when provided)
Semantics: Returns text T, but with text Old replaced by text New (when searching from the left). If Which is omitted, every occurrence of Old is replaced with New; if Which is provided, only that occurrence of Old is replaced by New (starting the count from 1). If there is no match, or if Old has length 0, the value of T is returned. Note that Old and New may have different lengths. If Which is present and Which < 1, returns Error.
See also LEFT 6.20.12, LEN 6.20.13, MID 6.20.15, REPLACE 6.20.17, RIGHT 6.20.19
Summary: Return the text (if Text), else return 0-length Text value
Syntax: T( Any X )
Returns: Text
Constraints: None
Semantics: The type of (a dereferenced) X is examined; if it is of type Text, it is returned, else an empty string (Text value of zero length) is returned. This is not a type-conversion function; T(5) produces an empty string, not "5".
See also N 6.13.26
Summary: Return the value converted to a text.
Syntax: TEXT( Scalar X ; Text FormatCode )
Returns: Text
Constraints: The FormatCode is a sequence of characters with an implementation-defined meaning.
Semantics: Converts the value X to a Text according to the rules of a number format code passed as FormatCode and returns it.
Summary: Remove leading and trailing spaces, and replace all internal multiple spaces with a single space.
Syntax: TRIM( Text T )
Returns: Text
Constraints: None.
Semantics: Takes T and removes all leading and trailing space. Any other sequence of 2 or more spaces is replaced with a single space.
A space is one or more, HORIZONTAL TABULATION (U+0009), LINE FEED (U+000A), CARRIAGE RETURN (U+000D) or SPACE (U+0020) characters.
See also LEFT 6.20.12, RIGHT 6.20.19
Summary: Return the character represented by the given numeric value according to the [UNICODE] Standard.
Syntax: UNICHAR( Integer N )
Returns: Text
Constraints: N >= 0, N <= 1114111 (U+10FFFF)
Semantics: Returns the character having the given numeric value as [UNICODE] code point.
Evaluators shall support values between 1 and 0xFFFF. Evaluators should allow N to be any [UNICODE] code point of type Graphic, Format or Control. Evaluators should implement UNICHAR such that UNICODE(UNICHAR(N)) returns N for any [UNICODE] code point N of type Graphic, Format or Control.
See also UNICODE 6.20.26
Summary: Return the [UNICODE] code point corresponding to the first character of the text value.
Syntax: UNICODE( Text T )
Returns: Number
Constraints: Length(T) > 0.
Semantics: Returns the numeric value of the [UNICODE] code point of the first character of the given text T.
The results of this function may be normalization-sensitive. 4.2
See also UNICHAR 6.20.25
Summary: Return input string, but with all lowercase letters converted to uppercase letters.
Syntax: UPPER( Text T )
Returns: Text
Constraints: None
Semantics: Return input string, but with all lowercase letters converted to uppercase letters, as defined by sections 3.13 Default Case Algorithms, 4.2 Case-Normative and 5.18 Case Mappings of [UNICODE]. As with most functions, it is side-effect free (it does not modify the source values). All Evaluators shall convert a-z to A-Z.
Note: As this function can be locale aware, results may be unexpected in certain cases, for example in a Turkish locale a lower case "i with dot" (LATIN SMALL LETTER I) U+0069 is converted to an upper case "I with dot" (LATIN CAPITAL LETTER I WITH DOT ABOVE, U+0130).
See also LOWER 6.20.14, PROPER 6.20.16
Evaluators may implement additional abilities that are not a matter of which function they support. The following sections describe some specific additional capabilities; evaluators may implement them, and documents may require them (though such documents may not be correctly recalculated on applications which do not implement them). Documents that depend on these other capabilities can still be considered “portable documents”, but only if these additional capabilities are clearly noted (since not applications implement these additional capabilities).
Evaluators claiming to implement “Inline constant arrays” shall support inline arrays with one matrix, with one or more rows, and one or more columns. Such evaluators shall support these 2-dimensional arrays as long as the number of expressions in each row is identical; evaluators may but need not support arrays with a different number of expressions in each row. They shall support at least the following syntactic rules in the Expression values for the inline array:
●Number, optionally preceded with the prefix “-” operator (for negative numbers)
●Text
●Logical constants TRUE() and FALSE()
●Error
Evaluators claiming to implement “Inline non-constant arrays” shall support the full Expression syntax in each component of an array (and not just constants).
Evaluators claiming to implement “Year 1583” can correctly calculate dates correctly starting from the January 1 of the (ISO) year 1583. This means that the evaluator correctly determines that 1900 was not a leap year, and can handle year values for dates back to at least 1583.
These calculations use the ISO (proleptic Gregorian) calendar, that is, the calculations use the usual rules for the ISO (Gregorian) calendar, regardless of locale. This calendar began official use in some locales in 1582, but other locales used other calendars (such as the Julian calendar) and switched to the Gregorian calendar at different times in history, if they switched at all. Evaluators may choose to support years even earlier than this; such evaluators should use a proleptic Gregorian system (continuing the years backwards as if the calendar existed in those years). Note that not all people used, or currently use, the ISO (Gregorian) calendar.
Correct date calculations in this calendar system require that leap years be handled correctly. In this calendar system, leap years include 29 days in February (which otherwise has 28 days), for 366 total days in a leap year. In general, all years evenly divisible by 4 are leap years. However, years that are divisible by 100 shall also be divisible by 400 to be a leap year; otherwise, they are common (non-leap) years.
Expressions may depend upon features that are not implemented by all evaluators. This section identifies and defines some features not commonly implemented to enable expressions to indicate their reliance on these features.
An evaluator may have the “Distinct Logical” feature, which means that its Logical type is a distinct type from both Number and Text, and that certain other properties or queries hold true as well. Some legacy documents depend on the “distinct logical” feature. An evaluator that has the “distinct logical” feature as described in this specification shall have the following properties:
●ISNUMBER() applied to a Logical value (constant or calculated) will return False, and ISLOGICAL() applied to a Number will be False, either directly or via a reference
●TRUE() will not be equal to 1, and FALSE() will not be equal to 0, when they are compared using “=”
●In a NumberSequence (such as when using SUM), Logical values are skipped when inside a range, but are included and automatically converted to a Number if provided as the NumberSequence itself